
The agile and DevOps transformation of software testing has been accelerating since the pandemic and there is no slowing down. Applications need to be tested faster and earlier in the software development lifecycle, while customer experience is a rising priority. However, good quality, production-like test data is still hard to come by. Up to 50% of the average tester‘s time is spent waiting for test data, looking for it, or creating it by hand. Test data challenges plague companies of all sizes from the smaller organizations to enterprises. What is true in most fields, also applies in software testing: AI will revolutionize testing. AI-powered testing tools will improve quality, velocity, productivity and security. In a 2021 report, 75% of QA experts said that they plan to use AI to generate test environments and test data. Saving time and money is already possible with readily available tools like synthetic test data generators. According to Gartner, 20% of all test data will be synthetically generated by 2025. And the tools are already here. But let's start at the beginning.
What is test data?
The definition of test data depends on the type of test. Application testing is made up of lots of different parts, many of which require test data. Unit tests are the first to take place in the software development process. Test data for unit tests consist of simple, typically small samples of test data. However, realism might already be an important test data quality. Performance testing or load testing requires large batches of test data. Whichever stage we talk about, one thing is for sure. Production data is not test data. Production data should never be in test environments. Data masking, randomization, and other common techniques do not anonymize data adequately. Mock data and AI-generated synthetic data are privacy-safe options. The type of test should decide which test data generation should be used.
What is a synthetic test data generator?
Synthetic test data is an essential part of the software testing process. Mobile banking apps, insurance software, retail and service providers all need meaningful, production-like test data for high quality QA. There is a confusion around the synthetic data term with many still thinking of synthetic data as mock or fake data. While mock data generators are still useful in unit tests, their usefulness is limited elsewhere. Similar to mock data generators, AI-powered synthetic test data generators are available online, in the cloud or on premise, depending on the use case. However, the quality of the resulting synthetic data varies widely. Use a synthetic test data generator that is truly AI-powered, retains the data structures, the referential integrity of the sample database and has additional, built-in privacy checks when generating synthetic data.
Accelerate your testing with synthetic test data
Get hands-on with MOSTLY AI's AI-powered platform and generate your first synthetic data set!
What is synthetic test data? The definition of AI-generated synthetic test data (TL;DR: it's NOT mock data)
Synthetic test data is generated by AI, that is trained on real data. It is structurally representative, referential integer data with support for relational structures. AI-generated synthetic data is not mock data or fake data. It is as much a representation of the behavior of your customers as production data. It’s not generated manually, but by a powerful AI engine that is capable of learning all the qualities of the dataset it is trained on, providing 100% test coverage. A good quality synthetic data generator can automate test data generation with high efficiency and without privacy concerns. Customer data should always be used in its synthetic form to protect privacy and to retain business rules embedded in the data. For example, mobile banking apps should be tested with synthetic transaction data, that is based on real customer transactions.
Test data types, challenges and their synthetic test data solutions
Synthetic data generation can be useful in all kinds of tests and provide a wide variety of test data. Here is an overview of different test data types, their applications, main challenges of data generation and how synthetic data generation can help create test data with the desired qualities.
| Test Data Types | Application | Challenge | Solution |
|---|---|---|---|
| Valid test data The combination of all possible inputs. | Integration, interface, system and regression testing | It’s challenging to cover all scenarios with manual data generation. Maintaining test data is also extremely hard. | Generate synthetic data based on production data. |
| Invalid (erroneous) test data Data that cannot and should not be processed by the software. | Unit, integration, interface, system testing, security testing | It is not always easy to identify error conditions to test because you don't know them a priori. Access to production errors is necessary but will also not yield previously unknown error scenarios. | Create more diverse test cases with synthetic data based on production data. |
| Huge test data Large volume test data for load and stress testing. | Performance testing, stress testing | Lack of sufficiently large and varied batches of data. Simply multiplying production data does not simulate all the components of the architecture correctly. Recreating real user scenarios with the right timing and general temporal distribution with manual scripts is hard. | Upsample production data via synthesization. |
| Boundary test data Data that is at the upper or lower limits of expectations. | Reliability testing | Lack of sufficiently extreme data. It’s impossible to know the difference between unlikely and impossible for values not defined within lower and upper limits, such as prices or transaction amounts. | Generate synthetic data in creative mode or use contextual generation. |
How to generate synthetic test data using AI
Generate synthetic data for testing using a purpose-built, AI-powered synthetic data platform. Some teams opt to build their own synthetic data generators in-house, only to realize that the complexity of the job is way bigger than what they signed up for. MOSTLY AI’s synthetic test data generator offers a free forever option for those teams looking to introduce synthetic data into their test data strategy.
This online test data generator is extremely simple to use:
- Connect your source database
- Define the tables where you want to protect privacy
- Start the synthesization
- Save the synthetic data to your target database
The result is structurally representative, referential integer data with support for relational structures. Knowing how to generate synthetic data starts with some basic data preparation. Fear not, it's easy and straightforward, once you understand the principles, it will be a breeze.
Do you need a synthetic test data generator?
If you are a company building a modern data stack to work with data that contains PII (personally identifiable information), you need a high quality synthetic data generator. Why? Because AI-generated synthetic test data is a different level of beast where generating a few tables won’t cut it. To keep referential integrity, MOSTLY AI can directly connect to the most popular databases and synthesize directly from your database. If you are operating in the cloud, it makes even more sense to test with synthetic data for security purposes.
Synthetic test data advantages
Synthetic data is smarter
Thanks to the powerful learning capabilities of the AI, synthetic data offers better test coverage, resulting in fewer bugs and higher reliability. You’ll be able to test with real customer stories and improve customer experience with unprecedented accuracy. High-quality synthetic test data is mission-critical for the development of cutting edge digital products.
Synthetic data is faster
Accelerated data provisioning is a must-have for agile software development. Instead of tediously building a dataset manually, you can let AI do the heavy lifting for you in a fraction of the time.
Synthetic data is safer
Built-in privacy mechanisms prevent privacy leaks and protect your customers in the most vulnerable phases of development. Radioactive production data should never be in test environments in the first place, no matter how secure you think it is. Legacy anonymization techniques fail to provide privacy, so staying away from data masking and other simple technuiques is a must.
Synthetic data is flexible
Synthesization is a process that can change the size of the data to match your needs. Upscale for performance testing or subset for a smaller, but referentially correct dataset.
Synthetic data is low-touch
Data provisioning can be easily automated by using MOSTLY AI’s Data Catalog function. You can save your settings and reuse them, allowing your team to generate data on-demand.
What’s wrong with how test data has been generated so far?
A lot of things. Test data management is riddled with costly bad habits. Quality, speed and productivity suffer unnecessarily if your team does any or all of the following:
1.) Using production data in testing
Just take a copy of production and pray that the unsecure test environment won’t leak any. It’s more common than you’d think, but that doesn’t make it ok. It’s only a matter of time before something goes wrong and your company finds itself punished by customers and regulators for mishandling data. What’s more, actual data doesn’t cover all possible test cases and it’s difficult to test new features with data that doesn’t yet exist.
2.) Using legacy anonymization techniques
Contrary to popular belief, adding noise to the data, masking data or scrambling it doesn’t make it anonymous. These legacy anonymization techniques have been shown time and again to endanger privacy and destroy data utility at the same time. Anonymizing time-series, behavioral datasets, like transaction data, is notoriously difficult. Pro-tip: don’t even try, synthesize your data instead. Devs often have unrestricted access to production data in smaller companies, which is extremely dangerous. According to Gartner, 59% of privacy incidents originate with an organization’s own employees. It may not be malicious, but the result is just as bad.
3.) Generate fake data
Another very common approach is to use fake data generators like Mockito or Mockaroo. While there are some test cases, like in the case of a brand new feature, when fake data is the only solution, it comes with serious limitations. Building datasets out of thin air costs companies a lot of time and money. Using scripts built in-house or mock data generation tools takes a lot of manual work and the result is far from sophisticated. It’s cumbersome to recreate all the business rules of production data by hand, while AI-powered synthetic data generators learn and retain them automatically. What’s more, individual data points might be semantically correct, but there is no real "information" coming with fake data. It's just random data after all. The biggest problem with generating fake data is the maintenance cost. You can start testing a new application with fake data, but updating it will be a challenge. Real data changes and evolves while your mock test data will become legacy quickly.
4.) Using fake customers or users to generate test data
If you have an army of testers, you could make them behave like end users and create production like data through those interactions. It takes time and a lot of effort, but it could work if you are willing to throw enough resources in. Similarly, your employees could become these testers, however, test coverage will be limited and outside your control. If you need a quick solution for a small app, it could be worth a try, but protecting your employees’ privacy is still important.
5.) Canary releases for performance and regression tests
Some app developers push a release to a small subset of their users first and consider performance and regression testing done. While canary testing can save you time and money in the short run, long term your user base might not appreciate the bugs they encounter on your live app. What’s more, there is no guarantee that all issues will be detected.
It’s time to develop healthy test data habits! AI-generated synthetic test data is based on production data. As a result, the data structure is 100% correct and it’s really easy to generate on-demand. What’s more, you can create even more varied data than with production data covering unseen test cases. If you choose a mature synthetic data platform, like MOSTLY AI’s, built-in privacy mechanisms will guarantee safety. The only downside you have to keep in mind is that for new features you’ll still have to create mock data, since AI-generated synthetic data needs to be based on already existing data.
Test data management in different types of testing
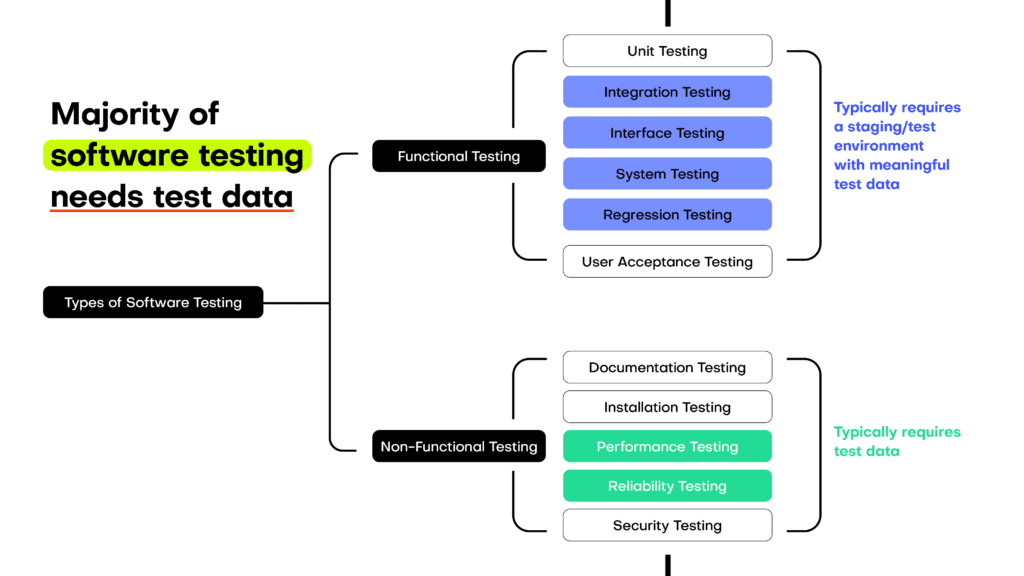
FUNCTIONAL TESTING
Unit testing
The smallest units of code tested with a single function. Mock data generators are often used for unit tests. However, AI-generated synthetic data can also work if you take a small subset of big original production datasets.
Integration testing
The next step in development is integrating the smallest units. The goal is to expose defects. Integration testing typically takes place in environments populated with meaningful, production-like test data. AI-generated synthetic data is the best choice, since relationships of the original data are kept without privacy sensitive information.
Interface testing
The application’s UI needs to be tested through all possible customer interactions and customer data variations. Synthetic customers can provide the necessary realism for UI testing and expose issues dummy data couldn’t.
System testing
System testing examines the entire application with different sets of inputs. Connected systems are also tested in this phase. As a result, realistic data can be mission-critical to success. Since data leaks are the most likely to occur in this phase, synthetic data is highly recommended for system testing.
Regression testing
Adding a new component could break old ones. Automated regression tests are the way forward for those wanting to stay on top of issues. Maximum test data coverage is desirable and AI-generated synthetic data offers just that.
User acceptance testing
In this phase, end-users test the software in alpha and beta tests. Contract and regulatory testing also falls under this category. Here, suppliers and vendors or regulators test applications. Demo data is frequently used at this stage. Populating the app with hyper-realistic synthetic data can make the product come to life, increasing the likelihood of acceptance.
NON-FUNCTIONAL TESTING
Documentation testing
The documentation detailing how to use the product needs to match how the app works in reality. The documentation of data-intensive applications often contain dataset examples for which synthetic data is a great choice.
Installation testing
The last phase of testing, before the end-user takes over, testing the installation process itself to see if it works as expected.
Performance testing
Tests how a product behaves in terms of speed and reliability. The data used in performance testing must be very close to the original. That’s why a lot of test engineers use production data treated with legacy anonymization techniques. However, these old-school technologies, like data masking and generalization, destroy both insights and come with very weak privacy.
Security testing
Security testing’s goal is to find risks and vulnerabilities. The test data used in security testing needs to cover authentication, like usernames and passwords as well as databases and file structures. High-quality AI-generated synthetic data is especially important to use for security testing.
Test data checklist
- Adopt an engineering mindset to test data across your team.
- Automate test data generation as much as you can.
- Develop a test data as a service mindset and provide on-demand access to privacy safe synthetic data sandboxes.
- Use meaningful, AI-generated smart synthetic test data whenever you can.
- Get management buy-in for modern privacy enhancing technologies (PETs) like synthetic data.

