
The choice for mankind lies between freedom and happiness and for the great bulk of mankind, happiness is better.
The above is my favorite quote from George Orwell's dystopian classic, 1984. This is one among several chilling quotes that can be revisited and newly interpreted to provide searing insight into present-day events.
With a slight tweak, this quote can be re-imagined by encapsulating the challenge of big data privacy.
The choice for mankind lies between
freedomprivacy andhappinessutility, and for the great bulk of mankind,happinessutility is better.
The key here is choice.
From an individual perspective, the choice is between privacy and convenience. We share our personal data because we receive something of value in return.
For the modern enterprise, the choice comes down to two ingredients of digital transformation:
- protecting its customers' privacy,
- and unlocking the valuable insights contained within customer data.
It is a difficult choice when framed as a zero-sum game, but does it have to be so?
This is the question that compelled me to join the MOSTLY AI team. MOSTLY AI is reshaping the paradigm with realistic and representative synthetic data. We are creating a data ecosystem in which privacy and utility can co-exist.
In this blog, we will look at privacy vs. utility in personalized digital banking.
Digital transformation in banking with personalized customer experience
The COVID-19 pandemic has accelerated the shift to digital banking. In this new world, personalized customer experiences are sacrosanct.
'The goal of digital banking is to offer easily understandable client-focused services that help customers to improve their financial health,' says Tomas Balint, Data Chapter Lead at the George digital banking team at Erste Group. 'To achieve this goal, banks need to translate complex customer interactions into clear data evidence and use this evidence to provide simple and relevant advice to their customers.'
Data-driven personalization analyzes customer data in real time. Machine-learning models provide personalized services based on the customer's financial profile. These machine-learning models need quality data—and lots of it. Models learn what is important to the customer. This is how banks can provide relevant and timely advice during the digital banking experience. However, accessing customer data for the purposes of analytics requires specific consent.
Is it possible to provide personalized customer experiences without personal data? And if so, would that constitute the perfect balance of privacy and utility?
Digital banking personalization drives business impact
In the latest World Retail Banking Report, 57% of consumers say they now prefer internet (online) banking to traditional branch banking. 55% of consumers now prefer using mobile banking apps to stay on top of their finances, up from 47% in the pre-pandemic era.
The shift to digital banking was well underway before the pandemic, driven in large part by changing customer expectations. As customers, we expect the same level of personalization in our digital banking experience that we have become accustomed to in other aspects of our life. Our mobile banking app should make it simple to understand how much money we have, how we spend our money, and what we can do with our money. Customers are embracing personalized insights, achieving satisfaction scores of 4.4 out of 5, according to Personetics' 2020 global banking analysis. Better experiences equal happier customers, and happier customers make the bank more money.
There are several powerful incentives for banks to accelerate digital transformation, including:
- increased value of sales per customer,
- improved customer acquisition rates,
- reduced customer churn,
- lower servicing costs, and
- an enhanced halo effect.
To put this into perspective, BCG estimates that for every $100 billion in assets that a bank has, it can achieve as much as $300 million in revenue growth by personalizing its customer interactions.
The privacy–personalization paradox
The challenge for banks is that they must contend with two opposing truths in their quest to develop this lucrative personalized customer experience.
- Customers expect personalized digital banking experiences.
- Customers are increasingly skeptical about how their data is used.
Balancing these two opposing truths is no easy feat and goes straight to the heart of the privacy vs. utility trade-off. We have previously spoken on this blog about how privacy kills data-driven innovation for banks. Furthermore, our colleagues on Mobey's AI and Data Privacy Expert Group have recently spoken at length about how operating with data at scale without sacrificing privacy along the way is a major challenge in banking.
Power your personalization in banking with synthetic data
So, we have established that personalized customer experiences drive business impact. However, banks must contend with privacy obstacles in the form of customer consent.
How it works: Data lifecycle
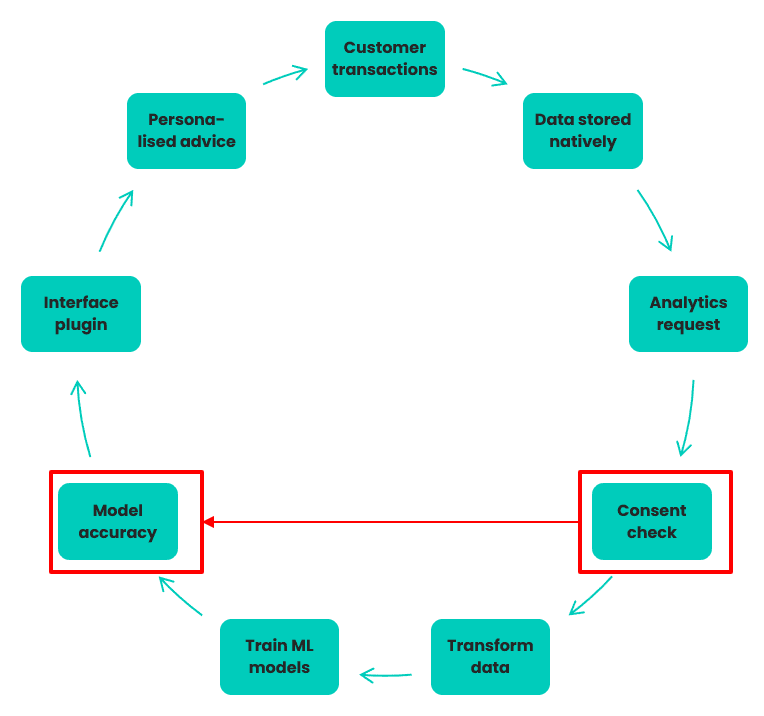
1. Customer generates transaction data through digital banking activity
2. Data stored natively in Elasticsearch for easy search & retrieval
3. Data analytics team requests data for predictive analysis
4. Compliance team verifies specific consent obtained for 30% of data
5. That data is transferred to Hadoop, transformed to tabular format
6. Data is used to train ML algorithms on what’s important to customers
7. The accuracy of the ML models are assessed by the business team
8. Interface team inserts accurate models into application plug-ins
9. Mobile app delivers personalized insights and advice to customers
Challenge: Only 30% of customers give specific consent to use their transactional data for the purposes of data analytics, therefore the quality and coverage of the ML models is suboptimal.
Let's take a look at a sample data lifecycle involved in creating personalized customer experiences. As we can see from figure 1, there are a number of steps involved:
- taking customer transactional data,
- analyzing customer transactional data,
- learning patterns from the data, and
- delivering it back to customers in the form of relevant advice and opportunities.
Machine learning underpins the data-driven workflow and enables complex, holistic, and predictive analyses of customer behavior.
As we know, the performance and accuracy of machine learning models are predicated on the quality and volume of data available to train them. A lack of data covering the full breadth and depth of real-life conditions is often a reason why a machine-learning model performs poorly.
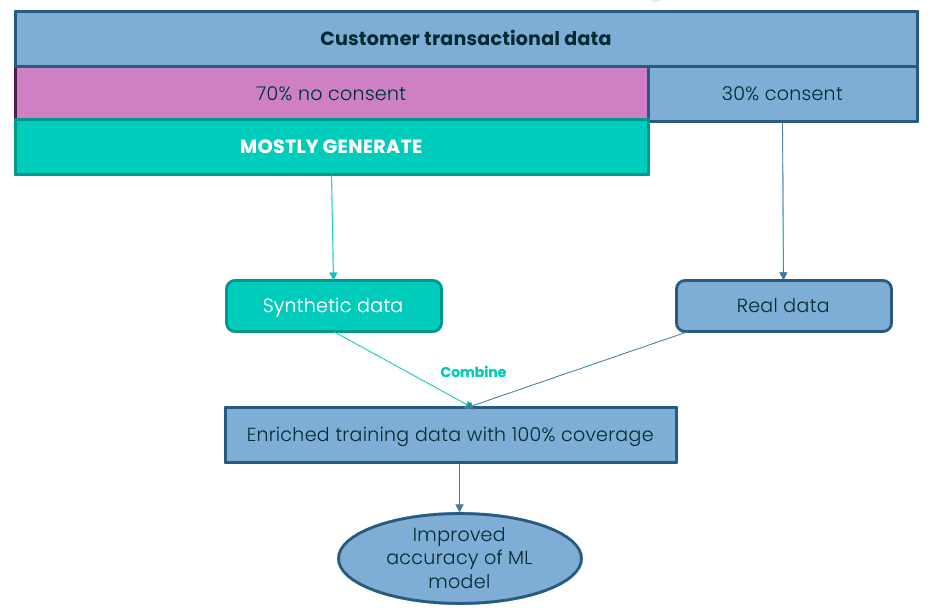
We can assume that only 30% of customers (a generous assumption in our experience) provide consent to use their data for analytic purposes. The bank must operate within the bounds of those privacy constraints, even if it's to the detriment of the machine learning model's accuracy. From speaking with our banking customers, we know that commercial teams are constantly pushing their counterparts in data analytics teams for more accurate models. Their goal is to create more personalized recommendations and ultimately generate more revenue for the bank. The constant drive for improvement is understandable as every granular increase in model accuracy can equate to significant downstream revenue.
For those banks striving for granular improvements in accuracy, they should cast their eye at synthetic data. Synthetic data can provide those granular improvements in your machine learning accuracy and then some. We have previously demonstrated how you can boost your machine learning accuracy with synthetic data. By leveraging synthetic data in your machine learning algorithms, you can unlock the insights contained within the data you cannot access (i.e., data that you do not have consent to process).
Figure 2 shows a simple workflow where a bank creates a mixed dataset of original data and synthetic data. This creates 100% coverage of the customer transactional data, ready to supercharge your machine learning accuracy.
A sufficient amount of accurate training data is critical for the success of any machine learning initiative. There is no more important machine learning initiative in digital banking than creating a personalized customer experience.
Data-driven personalization means greater market share for banks
Banks who master data-driven personalization will continue to achieve higher levels of digital-enabled sales and greater market share. Personalization has become a competitive imperative. Banks need to think outside of the box in order to survive; they need to go synthetic.
I will sign off with another one of my favorite quotes from George Orwell's 1984.
'Sanity is not statistical.'
The majority does not always determine what is right or correct. The prevailing wisdom in the modern bank maintains that you can achieve privacy or utility, privacy or personalization, but not both. Here at MOSTLY AI, we disagree.


