
What is synthetic data?
In this post, I will review the landscape of synthetic data companies. But first, what is synthetic data? Synthetic data is an artificial version of your real data created algorithmically. It looks and feels like real data and can be used for the same purposes. Synthetic data should not be confused with mock data; it retains the structure and statistical properties (including correlations) of your real data.
Why have synthetic data companies emerged recently?
Several factors are impacting the synthetic data landscape:
- The increasing demand for artificial intelligence (AI) applications that require large and diverse datasets for training and validation.
- Growing awareness of ethical and legal issues associated with real data, such as privacy, consent, and bias.
- The development of advanced technologies and algorithms capable of generating realistic and high-quality synthetic data.
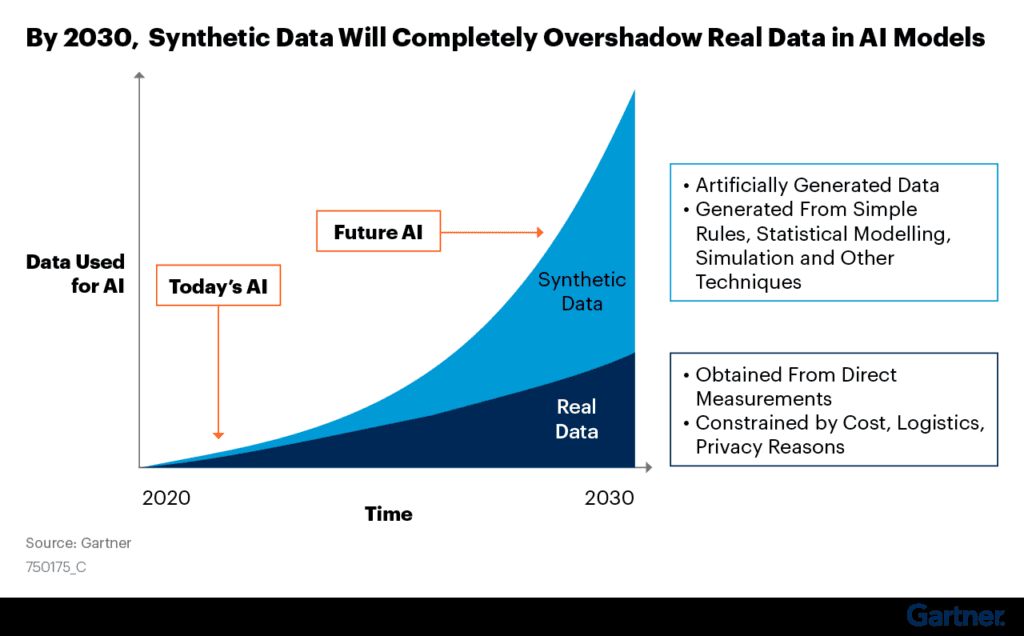
Until recently, synthetic data was viewed as a substitute or backup for real data. However, with recent advances in generative AI, synthetic data can now match or even surpass the quality of real data. According to Gartner, by 2030, synthetic data will dominate the use of real data in AI models.
What problems do synthetic data companies solve?
Synthetic data companies address various pain points in different industries and use cases, including:
- The lack of sufficient or relevant real data for training and testing AI models, especially in complex or rare scenarios.
- High costs and time associated with collecting, labeling, and processing real data.
- The risk of exposing sensitive or personal information from real data, leading to privacy breaches, legal liabilities, or ethical dilemmas.
By generating synthetic data that closely resembles real data but contains no identifiable information, these companies help overcome these challenges, enabling faster, cost-effective, and safer AI development and deployment.
The world's leading tabular synthetic data generator
Structured vs. unstructured synthetic data
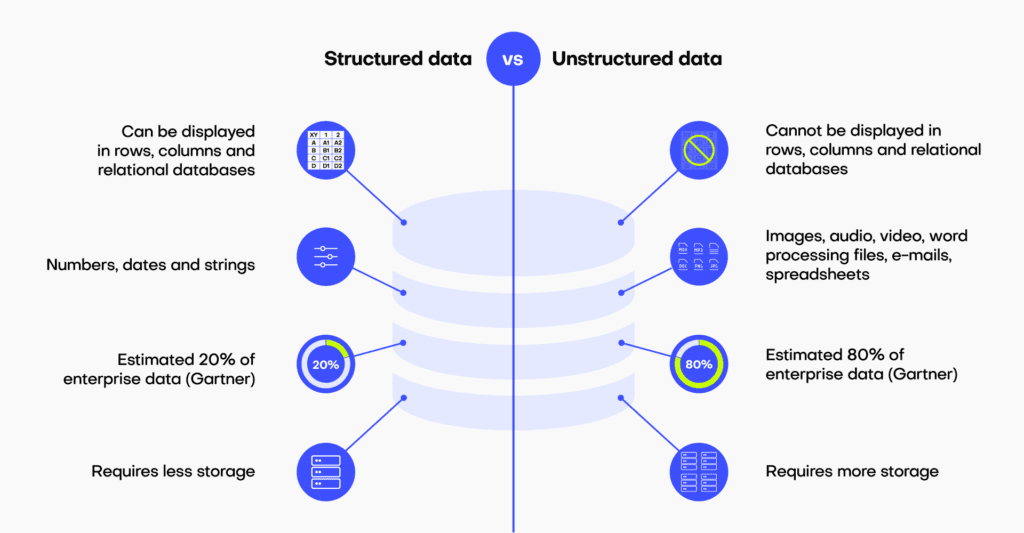
Synthetic data can be structured or unstructured, depending on its type and purpose:
- Structured data has a defined format and clear relationships between data points, typically stored in tabular form, such as in Excel files or SQL databases.
- Unstructured data lacks a predefined structure, making it more challenging to analyze using traditional methods. Examples include images, videos, transcripts, and emails.
Use cases for structured synthetic data
Structured synthetic data finds applications for example in:
- Simulation and prediction research in healthcare.
- Fraud identification in financial services.
- Public release of datasets for research or education purposes.
Use cases for unstructured synthetic data
Unstructured synthetic data is used for example in:
- Natural language processing (NLP) tasks.
- Computer vision tasks.
- Clinical decision support systems.
Funding for synthetic data companies
Here is a list of structured and unstructured synthetic data companies along with their funding:
Structured synthetic data companies
| # | Name | Funding in Mio $ |
|---|---|---|
| 1 | Accelario | 15.6 |
| 2 | AiDrome | |
| 3 | Betterdata | 2.4 |
| 4 | Clearbox AI | 0.79 |
| 5 | CloudTDMS | |
| 6 | CNAI | |
| 7 | Curiosity | |
| 8 | Datacebo | |
| 9 | DataCo | |
| 10 | Datomize | 6 |
| 11 | Datamaker | 0.073 |
| 12 | ExactData | |
| 13 | Facteus | 15.1 |
| 14 | Fairgen | 2.5 |
| 15 | FinCrime Dynamics | 0.758 |
| 16 | Gretel.ai | 67.7 |
| 17 | HAZY | 14.8 |
| 18 | Howso (formerly Diveplane) | 34 |
| 19 | Kymera Labs | 0.15 |
| 20 | K2view | |
| 21 | MDClone | 104 |
| 22 | Mirry.ai | |
| 23 | MOSTLY AI | 31.1 |
| 24 | Octopize MD | 1.5 |
| 25 | Replica analytics | 1 |
| 26 | Sarus | 2.17 |
| 27 | Statice | |
| 28 | Syndata | 0.245 |
| 29 | Syntheticus | |
| 30 | Synthesized | 2.8 |
| 31 | Syntho | 1.22 |
| 32 | Tonic.AI | 45 |
| 33 | Truata | 0.05 |
| 34 | Veil.ai | 1.41 |
| 35 | Ydata | 3.2 |
| Total funding in Mio $ | 370.2 |
Unstructured synthetic data companies
| # | Name | Funding in Mio $ |
|---|---|---|
| 1 | AI Reverie | 5.8 |
| 2 | Anyverse | 0.972 |
| 3 | Bifrost | 3.5 |
| 4 | CVEDIA | - |
| 5 | Coohom Cloud | - |
| 6 | Datagen | - |
| 7 | Dazzle AI | - |
| 8 | Deep Vision Data | - |
| 9 | EdgeCase | - |
| 10 | Elevenlabs | 21 |
| 11 | Kroop AI | 0.034 |
| 12 | Lexset | 1 |
| 13 | Midjourney | - |
| 14 | Mindtech | 10.1 |
| 15 | Neurolabs | 4.9 |
| 16 | Parallel domain | 43.9 |
| 17 | Rendered AI | 6 |
| 18 | Scale Synthetic | - |
| 19 | Sky Engine | 2 |
| 20 | Synthesis AI | 21.5 |
| 21 | Synthetik | 1.9 |
| 22 | Vypno | - |
| 23 | Zumo Labs | 0.15 |
| Total funding in Mio $ | 121.1 |

Acquisitions of synthetic data companies
As of August 2023, there have been four publicly-known acquisitions:
| # | Name | Acquired by | When |
|---|---|---|---|
| 1 | AI.Reverie | 2021 | |
| 2 | Replica Analytics | Aetion | 2022 |
| 3 | Statice | Anonos | 2022 |
| 4 | Logiq.ai | Apica | 2023 |
The future of synthetic data companies
As AI technologies advance, the role of synthetic data in AI development will evolve. Synthetic data companies have a promising future driven by the increasing demand for high-quality data. To ensure the quality and compliance of synthetic data, companies must refine their data synthesis methods and address challenges related to privacy, diversity, and cost-effectiveness.
The upcoming AI Act in Europe highlights the importance of synthetic data in AI development, particularly in addressing data privacy and quality issues. Synthetic data companies are poised to play a crucial role in this regulatory landscape.
The world's leading tabular synthetic data generator
Conclusion
Synthetic data companies have ushered in an era of responsible and ethical AI development. They have addressed data scarcity, privacy concerns, and model bias, offering a reliable and privacy-conscious alternative to mock data. As AI continues to advance, synthetic data's potential to mitigate bias, enhance model robustness, and reduce costs will become increasingly indispensable.
In a world of tightening data privacy regulations, synthetic data will continue to ensure ethical and legal AI development. The promises and possibilities ahead are boundless as we embrace a data-driven future.
If you need to synthesize structured synthetic data, check out MOSTLY AI's synthetic data generator!


