The world is changing, and anonymous data is not anonymous anymore
In recent years, data breaches have become more frequent. A sign of changing times: data anonymization techniques sufficient 10 years ago fail in today's modern world. Nowadays, more people have access to sensitive information, who can inadvertently leak data in a myriad of ways. This ongoing trend is here to stay and will be exposing vulnerabilities faster and harder than ever before. The disclosure of not fully anonymous data can lead to international scandals and damaged reputation.
Most importantly, customers are more conscious of their data privacy needs. According to Cisco's research, 84% of respondents indicated that they care about privacy. Among privacy-active respondents, 48% indicated they already switched companies or providers because of their data policies or data sharing practices. And it's not only customers who are increasingly suspicious. Authorities are also aware of the urgency of data protection and privacy, so the regulations are getting stricter: it is no longer possible to easily use raw data even within companies.
This blogpost will discuss various techniques used to anonymize data. The following table summarizes their re-identification risks and how each method affects the value of raw data: how the statistics of each feature (column in the dataset) and the correlations between features are retained, and what the usability of such data in ML models is.
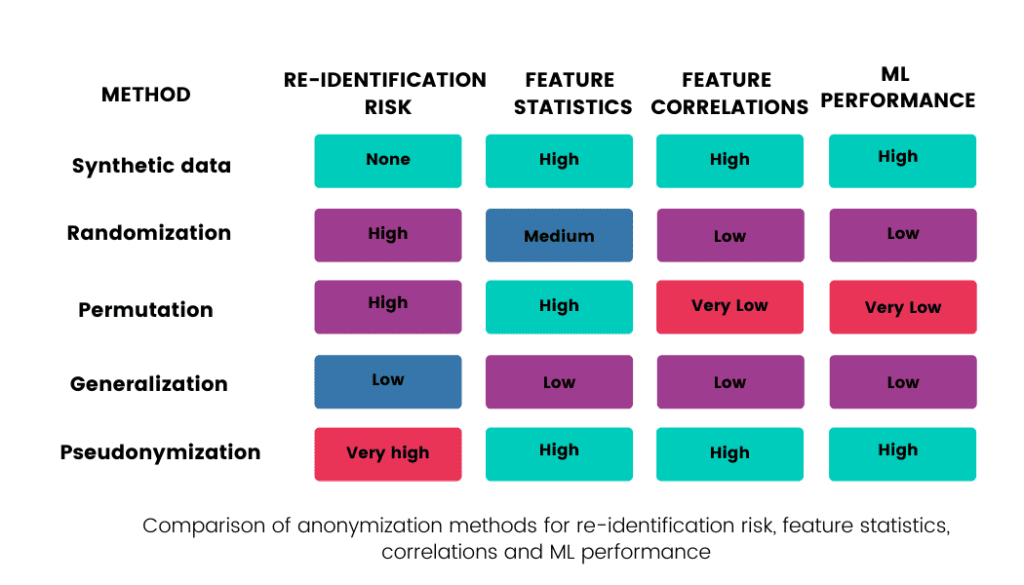
#1 Pseudonymization is not anonymization
The EU launched the GDPR (General Data Protection Regulation) in 2018, putting long-planned data protection reforms into action. GDPR's significance cannot be overstated. It was the first move towards an unified definition of privacy rights across national borders, and the trend it started has been followed worldwide since. So what does it say about privacy-respecting data usage?
First, it defines pseudonymization (also called de-identification by regulators in other countries, including the US). Based on GDPR Article 4, Recital 26: "Personal data which have undergone pseudonymisation, which could be attributed to a natural person by the use of additional information should be considered to be information on an identifiable natural person." Article 4 states very explicitly that the resulting data from pseudonymization is not anonymous but personal data. Thus, pseudonymized data must fulfill all of the same GDPR requirements that personal data has to.
Why is pseudonymization dangerous?
Imagine the following sample of four specific hospital visits, where the social security number (SSN), a typical example of Personally Identifiable Information (PII), is used as a unique personal identifier.

The pseudonymized version of this dataset still includes direct identifiers, such as the name and the social security number, but in a tokenized form:

Replacing PII with an artificial number or code and creating another table that matches this artificial number to the real social security number is an example of pseudonymization. Once both tables are accessible, sensitive personal information is easy to reverse engineer. That's why pseudonymized personal data is an easy target for a privacy attack.
How about simply removing sensitive information?
For data analysis and the development of machine learning models, the social security number is not statistically important information in the dataset, and it can be removed completely. Therefore, a typical approach to ensure individuals’ privacy is to remove all PII from the data set. But would it indeed guarantee privacy? Is this true data anonymization?
Unfortunately, the answer is a hard no. The problem comes from delineating PII from non-PII. For instance, 63% of the US population is uniquely identifiable by combining their gender, date of birth, and zip code alone. In our example, it is not difficult to identify the specific Alice Smith, age 25, who visited the hospital on 20.3.2019 and to find out that she suffered a heart attack.
These so-called indirect identifiers cannot be easily removed like the social security number as they could be important for later analysis or medical research.
So what next? Should we forget pseudonymization once and for all? No, but we must always remember that pseudonymized data is still personal data, and as such, it has to meet all data regulation requirements.
#2 Legacy data anonymization techniques destroy data
How can we share data without violating privacy? We can choose from various well-known techniques such as:
- Permutation (random permutation of data)
- Randomization (random modification of data)
- Generalization
Permutation - high risk of re-identification, low statistical performance
We could permute data and change Alice Smith for Jane Brown, waiter, age 25, who came to the hospital on that same day. However, with some additional knowledge (additional records collected by the ambulance or information from Alice's mother, who knows that her daughter Alice, age 25, was hospitalized that day), the data can be reversibly permuted back.
We can go further than this and permute data in other columns, such as the age column. Column-wise permutation's main disadvantage is the loss of all correlations, insights, and relations between columns. In our example, we can tell how many people suffer heart attacks, but it is impossible to determine those people's average age after the permutation.

Randomization - high risk of re-identification, low statistical performance
Randomization is another old data anonymization approach, where the characteristics are modified according to predefined randomized patterns. One example is perturbation, which works by adding systematic noise to data. In this case, the values can be randomly adjusted (in our example, by systematically adding or subtracting the same number of days to the date of the visit).
However, in contrast to the permutation method, some connections between the characteristics are preserved. In reality, perturbation is just a complementary measure that makes it harder for an attacker to retrieve personal data but doesn’t make it impossible. Never assume that adding noise is enough to guarantee privacy!

Generalization - low risk of re-identification, low statistical performance
Generalization is another well-known data anonymization technique that reduces the granularity of the data representation to preserve privacy. The main goal of generalization is to replace overly specific values with generic but semantically consistent values. One of the most frequently used techniques is k-anonymity.
K-anonymity prevents the singling out of individuals by coarsening potential indirect identifiers so that it is impossible to drill down to any group with fewer than (k-1) other individuals. In other words, k-anonymity preserves privacy by creating groups consisting of k records that are indistinguishable from each other, so that the probability that the person is identified based on the quasi-identifiers is not more than 1/k. In our example, k-anonymity could modify the sample in the following way:

By applying k-anonymity, we must choose a k parameter to define a balance between privacy and utility. However, even if we choose a high k value, privacy problems occur as soon as the sensitive information becomes homogeneous, i.e., groups have no diversity.
Suppose the sensitive information is the same throughout the whole group - in our example, every woman has a heart attack. In such cases, the data then becomes susceptible to so-called homogeneity attacks described in this paper. The authors also proposed a new solution, l-diversity, to protect data from these types of attacks.
Nevertheless, even l-diversity isn’t sufficient for preventing attribute disclosure. Another article introduced t-closeness - yet another anonymity criterion refining the basic idea of k-anonymity to deal with attribute disclose risk. Most importantly, all research points to the same pattern: new applications uncover new privacy drawbacks in data anonymization methods, leading to new techniques and, ultimately, new drawbacks.
The privacy-utility trade-off
No matter what criteria we end up using to prevent individuals’ re-identification, there will always be a trade-off between privacy and data value. Data that is fully anonymized so that an attacker cannot re-identify individuals is not of great value for statistical analysis.
On the other hand, if data anonymization is insufficient, the data will be vulnerable to various attacks, including linkage. Although an attacker cannot identify individuals in that particular dataset directly, data may contain quasi-identifiers that could link records to another dataset that the attacker has access to. In combination with other sources or publicly available information, it is possible to determine which individual the records in the main table belong to.
The re-identification process is much more difficult with legacy data anonymization than in the case of pseudonymization because there is no direct connection between the tables. Re-identification, in this case, involves a lot of manual searching and the evaluation of possibilities. Still, it is possible, and attackers use it with alarming regularity. As more connected data becomes available, enabled by semantic web technologies, the number of linkage attacks can increase further.
There are many publicly known linkage attacks. In 2001 anonymized records of hospital visits in Washington state were linked to individuals using state voting records. In one of the most famous works, two researchers from the University of Texas re-identified part of the anonymized Netflix movie-ranking data by linking it to non-anonymous IMDb (Internet Movie Database) users’ movie ratings. Others de-anonymized the same dataset by combining it with publicly available Amazon reviews.
We have already discussed data-sharing in the era of privacy in the context of the Netflix challenge in a previous blog post. The topic is still hot: sharing insufficiently anonymized data is getting more and more companies into trouble. Linkage attacks can have a huge impact on a company’s entire business and reputation. At the center of the data privacy scandal, a British cybersecurity company closed its analytics business putting hundreds of jobs at risk and triggering a share price slide.
The final conclusion regarding anonymization: 'anonymized' data can never be totally anonymous. We can trace back all the issues described in this blogpost to the same underlying cause. All anonymized datasets maintain a 1:1 link between each record in the data to one specific person, and these links are the very reason behind the possibility of re-identification. Moreover, the size of the dataset modified by legacy data anonymization is the same as the size of the original data.
#3 Synthetic data provides an easy way out of the dilemma
Synthetic data doesn't suffer from this limitation. Synthetic data contains completely made up but realistic information, without any link to real individuals. In contrast to other approaches, synthetic data doesn't attempt to protect privacy by merely masking or obfuscating those parts of the original dataset deemed privacy-sensitive while leaving the rest of the original dataset intact. Data synthesis is a fundamentally different approach where the source data only serves as training material for an AI algorithm, which learns its patterns and structures.
Once the AI model was trained, new statistically representative synthetic data can be generated at any time, but without the individual synthetic data records resembling any individual records of the original dataset too closely. Therefore, the size of the synthetic population is independent of the size of the source dataset. In other words, the flexibility of generating different dataset sizes implies that such a 1:1 link cannot be found.
MOSTLY AI's synthetic data platform makes this process easily accessible for anyone. The algorithm automatically builds a mathematical model based on state-of-the-art generative deep neural networks with built-in privacy mechanisms. Our synthetic data platform fits the statistical distributions of the real data and generates synthetic data by drawing randomly from the fitted model. No matter if you generate 1,000, 10,000, or 1 million records, the synthetic population will always preserve all the patterns of the real data.
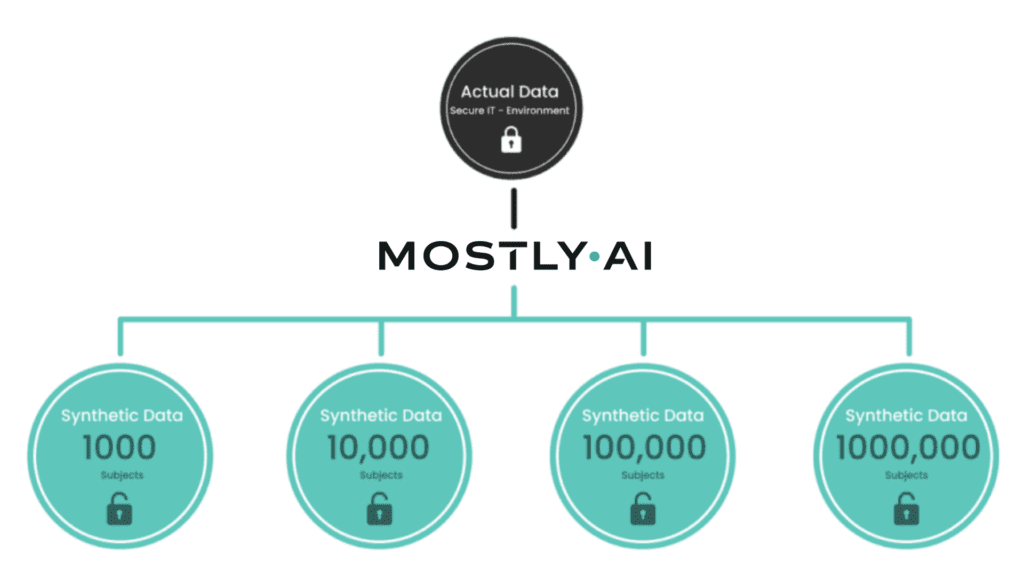
An example of AI-generated synthetic data
Let’s look at an example of the resulting statistics of MOSTLY AI’s synthetic data of the Berka dataset. This public financial dataset, released by a Czech bank in 1999, provides information on clients, accounts, and transactions. The figures below illustrate how closely synthetic data (labeled “synth” in the figures) follows the distributions of the original variables keeping the same data structure as in the target data (labeled “tgt” in the figures).
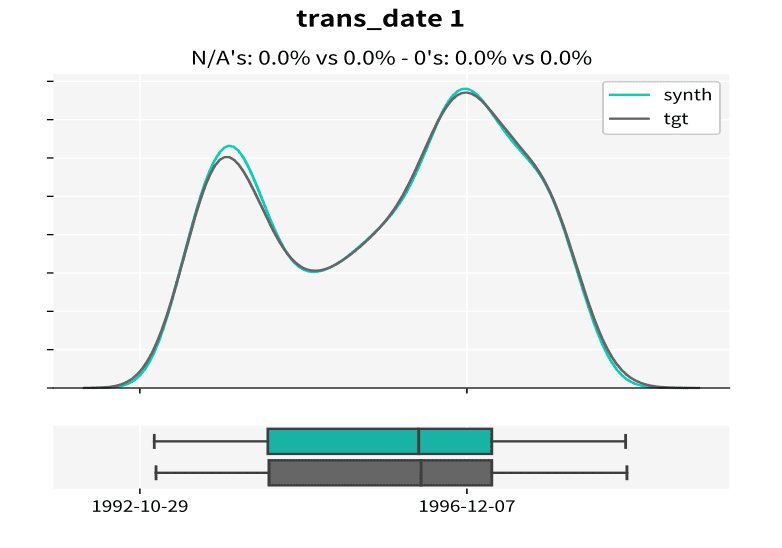
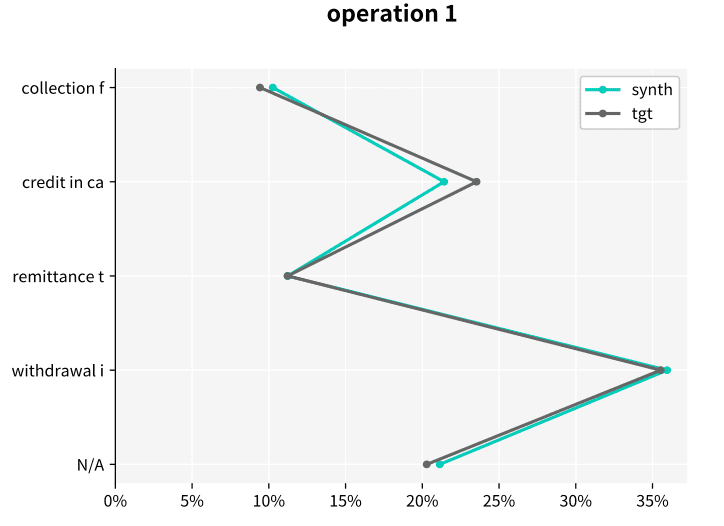
Synthetic data keeps all the variable statistics such as mean, variance or quantiles. Due to built-in privacy mechanisms, synthetic populations generated by MOSTLY AI's synthetic data platform can differ in the minimum and maximum values if they only rely on a few individuals. Keeping these values intact is incompatible with privacy, because a maximum or minimum value is a direct identifier in itself.
For example, in a payroll dataset, guaranteeing to keep the true minimum and maximum in the salary field automatically entails disclosing the salary of the highest-paid person on the payroll, who is uniquely identifiable by the mere fact that they have the highest salary in the company. In other words, the systematically occurring outliers will also be present in the synthetic population because they are of statistical significance. However, the algorithm will discard distinctive information associated only with specific users in order to ensure the privacy of individuals.
Synthetic data is as-good-as-real
The power of big data and its insights come with great responsibility. Merely employing old data anonymization techniques doesn’t ensure the privacy of an original dataset. Synthetic data is private, highly realistic, and retains all the original dataset’s statistical information.
We have illustrated the retained distribution in synthetic data using the Berka dataset, an excellent example of behavioral data in the financial domain with over 1 million transactions. Such high-dimensional personal data is extremely susceptible to privacy attacks, so proper data anonymization is of utmost importance.
Synthetic data has the power to safely and securely utilize big data assets empowering businesses to make better strategic decisions and unlock customer insights confidently. To learn more about the value of behavioral data, read our blog post series describing how MOSTLY AI's synthetic data platform can unlock behavioral data while preserving all its valuable information.
Download the Data Anonymization Guide
Get your hands on a copy of the condensed take-aways of this blogpost and upgrade your data anonymization toolkit for true privacy and compliance!
This is the second part of our blog post series on anonymous synthetic data. While Part I introduced the fundamental challenge of true anonymization, this part will detail the technical possibilities of establishing the privacy and thus safety of synthetic data.
The new era of anonymization: AI-generated synthetic copies
MOSTLY AI's synthetic data platform enables anyone to reliably extract global structure, patterns, and correlations from an existing dataset, to then generate completely new synthetic data at scale. These synthetic data points are sampled from scratch from the fitted probability distributions and thus bear no 1:1 relationship to any real, existing data subjects.
This lack of direct relationship to actual people already provides a drastically higher level of safety and renders deterministic re-identification, as discussed in Part I, impossible. However, a privacy assessment of synthetic data must not stop there but also needs to consider the most advanced attack scenarios. For one, to be assured, that customers’ privacy is not being put at any risk. And for two, to establish that a synthetic data solution indeed adheres to modern-day privacy laws. Over the past months, we have had two renowned institutions conduct thorough technical and legal assessments of MOSTLY AI's synthetic data across a broad range of attack scenarios and a broad range of datasets. And once more, it was independently established and attested by renowned experts: synthetic data by MOSTLY AI is not personal data anymore, thus adheres to all modern privacy regulations. ✅ While we go into these assessments’ details in this blog post, we are more than happy to share the full reports with you upon request.
The privacy assessment of synthetic data
Europe has recently introduced the toughest privacy law in the world, and its regulation also provides the strictest requirements for anonymization techniques. In particular, WP Article 29 has defined three criteria that need to be assessed:
- (i) is it still possible to single out an individual,
- (ii) is it still possible to link records relating to an individual, and
- (iii) can information be inferred concerning an individual?
These translate to evaluating synthetic data with respect to:
- the risk of identity disclosure: can anyone link actual individuals to synthetically generated subjects,
- the risk of membership disclosure: can anyone infer whether a subject was or was not contained in a dataset based on the derived synthetic data,
- the risk of attribute disclosure: can anyone infer additional information on a subject’s attribute if that subject was contained in the original data?
Whereas self-reported privacy metrics continue to emerge, it needs to be emphasized that these risks have to be empirically tested in order to assess the correct workings of any synthetic data algorithm as well as implementation.
Attribute disclosure
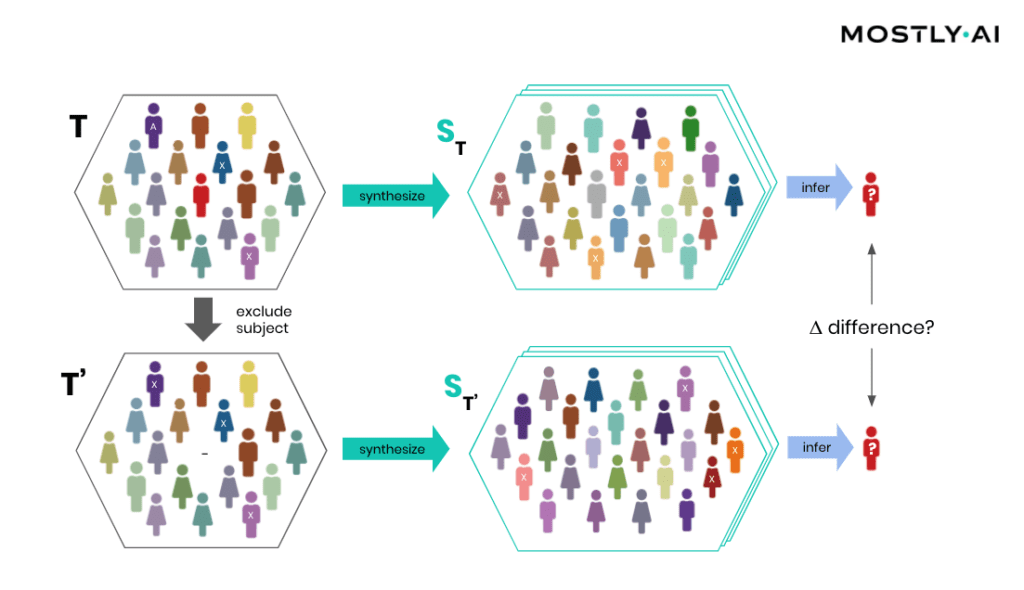
How is it possible for a third party to empirically assess the privacy of a synthetic data implementation? SBA Research, a renowned research center for information security, has been actively researching the field of attribute disclosure over the past couple of years and recently developed a sophisticated leave-one-out ML-based attribute disclosure test framework, as sketched in Figure 1. In that illustration, T depicts the original target data, that serves as training data for generating multiple synthetic datasets ST. T’ is then a so-called neighboring dataset of T that only differs with respect to T by excluding a single individual. Any additional information obtained from the synthetic datasets ST (based on T) as opposed to ST’ (based on T’) would reveal an attribute disclosure risk from including that individual. The risk of attribute disclosure can be systematically evaluated by training a multitude of machine learning models that predict a sensitive attribute based on all remaining attributes in order to then study the predictive accuracy for the excluded individual (the red-colored male depicted in Figure 1). A privacy-safe synthetic data platform, like MOSTLY AI with its in-built privacy safeguards, does not exhibit any measurable change in inference due to the inclusion or exclusion of a single individual.
At this point, it is important to emphasize that it’s the explicit goal of a synthesizer to retain as much information as possible. And a high predictive accuracy of an ML model trained on synthetic data is testimony to its retained utility and thus value, and in itself not a risk of attribute disclosure. However, these inferences must be robust, meaning that they must not be susceptible to the influence of any single individual, no matter how much that individual conforms or does not conform to the remaining population. The bonus: any statistics, any ML model, any insights derived from MOSTLY AI’s anonymous synthetic data comes out-of-the-box with the added benefit of being robust. The following evaluation results table for the contraceptive method choice dataset from the technical assessment report further supports this argument.
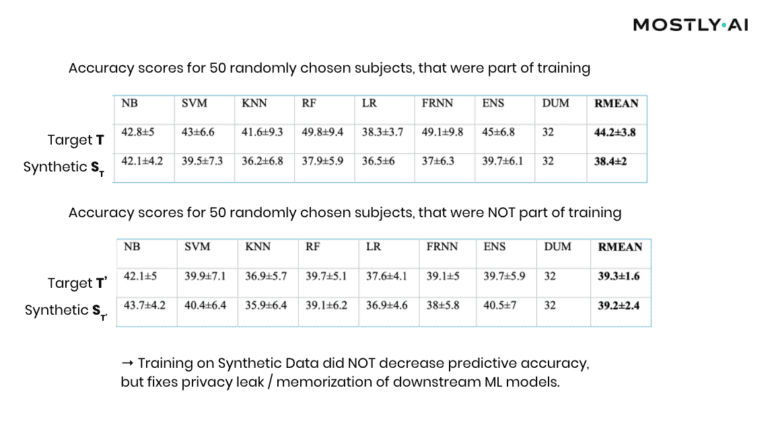
As can be seen, training standard machine learning models on actual data tends to be sensitive towards the inclusion of individual subjects (compare the accuracy of T vs. T’), which shows that the model has memorized its training data, and thus privacy has been leaked into the model parameters. On the other hand, training on MOSTLY AI’s synthetic data is NOT sensitive to individuals (compare ST with ST’). Thus, using synthetic data prevents the privacy leak / the overfitting of this broad range of ML models to actual data while remaining at the same level of predictive accuracy for holdout records.
Similarity-based privacy tests
While the previously presented framework allows for the systematic assessment of the (in)sensitivity of a synthetic data solution with respect to individual outliers, its leave-one-out approach does come with significant computational costs that make it unfortunately infeasible to be performed for each and every synthesis run. However, strong privacy tests have been developed based on the similarity of synthetic and actual data subjects, and we’ve made these an integral part of MOSTLY AI. Thus, every single time a user performs a data synthesis run, the platform conducts several fully automated tests for potential privacy leakage to help confirm the continuous valid working of the system.
Simply speaking, synthetic data shall be as close as possible, but not too close to actual data. So, accuracy and privacy, can both be understood as concepts of (dis)similarity, with the key difference being that the former is measured at an aggregate level and the latter at an individual level. But, what does it mean for a data record to be too close? How can one detect whether synthetic records are indeed statistical representations as opposed to overfitted/memorized copies of actual records? Randomly selected actual holdout records can help answer these questions by serving as a proper reference since they stem from the same target distribution but have not been seen before. Ideally, the synthetic subjects are indistinguishable from the holdout subjects, both in terms of their matching statistical properties, and their dissimilarity to the exposed training subjects. Thus, while synthetic records shall be as close as possible to the training records, they must not be any closer to them than what would be expected from the holdout records, as this would indicate that individual-level information is leaked rather than general patterns learned.
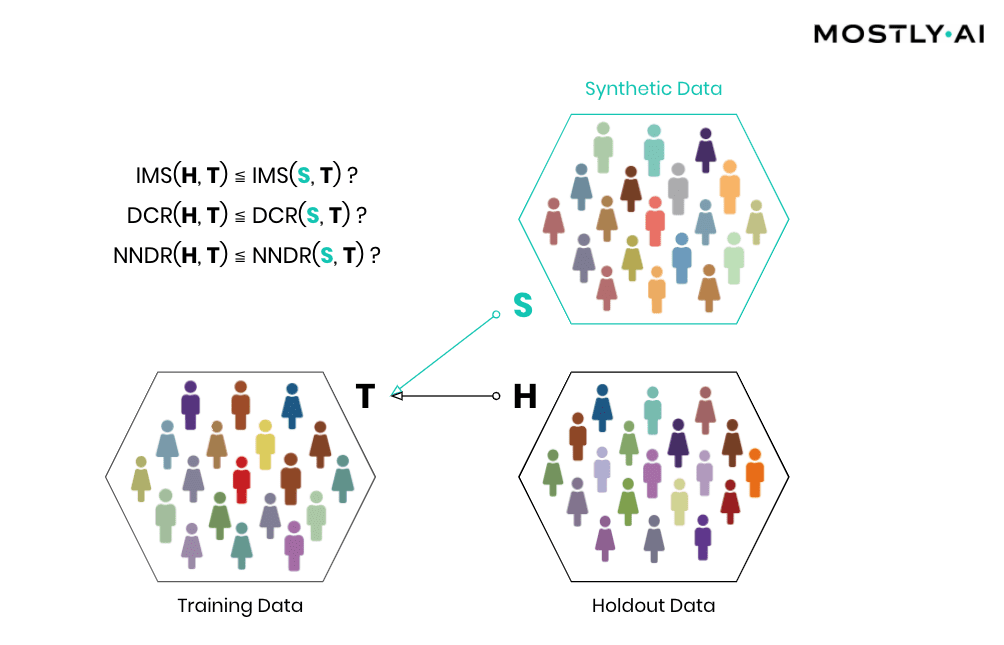
Then, how can the individual-level similarity of two datasets be quantified? A first, natural candidate is to investigate the number, respectively the share, of identical matches between these (IMS = identical match share). We thus have statistical tests automatically be performed that verify that the synthetic dataset does not have significantly more matches with the training data than what would be expected from a holdout data.
Important: the existence of identical matches within a synthetic dataset is in itself not an indicator for a privacy leak but rather needs to be assessed in the context of the dataset, as is done with our statistical tests. E.g., a dataset that exhibits identical matches within the actual data itself, shall also have a similar share of identical matches with respect to the synthetic data. Analogous to that metaphorical monkey typing the complete works of William Shakespeare by hitting random keys on a typewriter for an infinite time, any random data generator will eventually end up generating any data records, including the full medical history of yours. However, as there is no indication which of the generated data points actually exist and which not, the occurrence of such matches in a sea of data is of no use to an attacker. Yet further, these identical matches must NOT be removed from the synthetic output, as such a filter would 1) distort the resulting distributions, but more importantly 2) would actually leak privacy, as it would reveal the presence of a specific record in the training data by it being absent from a sufficiently large synthetic dataset!
But one has to go further and not only consider the dissimilarity with respect to exact matches but also with respect to the overall distribution of their distance to closest records (DCR). Just adding noise to existing data in a high-dimensional data space does not provide any protection, as has been laid out in the seminal Netflix paper on reidentification attacks (see also Part I). Taking your medical record, and changing your age by a couple of years, still leaks your sensitive information and makes that record re-identifiable, despite the overall record not being an exact match anymore. Out of an abundance of caution and to provide the strictest guarantees, one, therefore, shall demand that a synthetic record is not systematically any closer to an actual training record than what is again expected from an actual holdout record. On the other hand, if similar patterns occur within the original data across subjects, then the same (dis-)similarity shall be present also within the synthetic data. Whether the corresponding DCR distributions are significantly different can then be checked with statistical tests that compare the quantiles of the corresponding empirical distribution functions. In case the test fails, the synthetic data shall be rejected, as it is too close to actual records, and thus information on real individuals can potentially be obtained by looking for near matches within the synthetic population.
While checking for DCR is already a strong test, it comes with the caveat of measuring closeness in absolute terms. However, the distance between records can vary widely across a population, with Average Joes having small DCRs and Weird Willis (=outliers) having very large DCRs. E.g., if Weird Willi is 87 years old, has 8 kids, and is 212 cm tall, then shifting his height by a couple of centimeters will do little for his privacy. We have therefore developed an advanced measure that normalizes the distance to the closest record with respect to the overall density within a data space region, by dividing it by the distance to the 2nd closest record. This concept is known as the Nearest Neighbor Distance Ratio (NNDR) and is fortunately straightforward to compute. By checking that the NNDRs for synthetic records are not systematically any closer than expected from holdout records, one can thus provide an additional test for privacy that also protects the typically most vulnerable individuals, i.e., the outliers within a population. In any case, all tests (IMS, DCR, and NNDR) for a synthetic dataset need to pass in order to be considered anonymous.
Conclusion
We founded MOSTLY AI with the mission to foster an ethical data and AI ecosystem, with privacy-respecting synthetic data at its core. And today, we are in an excellent position to enable a rapidly growing number of leading-edge organizations to safely collaborate on top of their data for good use, to drive data agility as well as customer understanding, and to do so at scale. All while ensuring core values and fundamental rights of individuals remain fully protected.
Anonymization is hard - synthetic data is the solution. MOSTLY AI's synthetic data platform is the world’s most accurate and most secure offering in this space. So, reach out to us and learn more about how your organizations can reap the benefits of their data assets, while knowing that their customers’ trust is not put at any risk.
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
The very first question commonly asked with respect to Synthetic Data is: how accurate is it? Seeing, then, the unparalleled accuracy of MOSTLY AI's synthetic data platform in action, resulting in synthetic data that is near indistinguishable from real data, typically triggers the second, just as important question: is it really private? In this blog post series we will dive into the topic of privacy preservation, both from a legal as well as a technical perspective, and explain how external assessors unequivocally come to the same conclusion: MOSTLY AI generates truly anonymous synthetic data, and thus any further processing, sharing or monetization becomes instantly compliant with even the toughest privacy regulations being put in place these days.
What is anonymous data? A historical perspective
So, what does it mean for a dataset to be considered private in the first place? A common misconception is that any dataset that has its uniquely identifying attributes removed is thereby made anonymous. However, the absence of these so-called “direct identifiers”, like the full names, the e-mail addresses, the social security numbers, etc., within a dataset provides hardly any safety at all. The simple composition of multiple attributes taken together is unique and thus allows for the re-identification of individual subjects. Such attributes that are not direct identifiers by themselves, but only in combination, are thus termed quasi-identifiers. Just how easy this re-identification is, and how few attributes are actually required, came as a surprise to a broader audience when Latanya Sweeney published her seminal paper entitled “Simple Demographics Often Identify People Uniquely” in the year 2000. In particular, because her research was preceded by the successful re-identification of publicly available highly sensitive medical records, that were supposedly anonymous. Notably, the simple fact that zip code, date-of-birth, and gender in combination are unique to 87% of the US population, served as an eye-opener for policy-makers and researchers alike. And as a direct result of Sweeney’s groundbreaking work, privacy regulations were adapted to provide extra safety. For instance, the HIPAA privacy rule that covers the handling of health records in the US was passed in 2003, and explicitly lists a vast number of attributes (incl. any dates), that are all to be removed to provide safety (see footnote 15 here). Spurred by the discovery of these risks in methods then considered state-of-the-art anonymization, researchers continued their quest for improved de-identification methods and privacy guarantees, based on the concept of quasi-identifiers and sensitive attributes.
However, the approach ultimately had to hit a dead end, because any seemingly innocuous piece of information, that is related to an individual subject, is potentially sensitive, as well as serves as a quasi-identifier. And with more and more data points being collected, there is no escape from adversaries combining all of these with ease to single out individuals, even in large-scale datasets. The futility of this endeavor becomes even more striking once you realize that it’s a hard mathematical law that one attempts to compete with: the so-called curse of dimensionality. The number of possible outcomes grows exponentially with the number of data points per subject, and even for modestly sized databases quickly surpasses the number of atoms in the universe. Thus, with a continuously growing number of data points collected, any individual in any database is increasingly distinctive from all others and therefore becomes susceptible to de-anonymization.
The consequence? Modern-day privacy regulations (GDPR, CCPA, etc.) provide stricter definitions of anonymity. They consider data to be anonymous if and only if none of the subjects are re-identifiable, neither directly nor indirectly, neither by the data controller nor by any third party (see GDPR §4.1). They do soften the definition, requiring that the re-identification attack needs to be reasonably likely to be performed (see GDPR Recital 26 or CCPA 1798.140(o)). However, these clauses clearly do NOT exempt from considering the most basic and thus reasonable form, the so-called linkage attacks, that simply require 3rd party data to be joined for a successful de-anonymization. And it was simple linkage attacks, that lead to the re-identification of Netflix users, the re-identification of NY taxi trips, the re-identification of telco location data, the re-identification of credit card transactions, the re-identification of browsing data, the re-identification of health care records, and so forth.
A 2019 Nature paper thus had to conclude:
“[..] even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR and seriously challenge the technical and legal adequacy of the de-identification release-and-forget model.”
Gartner projects that by 2023, 65% of the world’s population will have its personal information covered under modern privacy regulations, up from 10% today with the European GDPR regulation becoming the de-facto global standard.
True anonymization today is almost impossible with old tools

And while thousands, rather millions of bits are being collected about each one of us on a continuous basis, only 33 bits of information turn out to be sufficient to re-identify each individual among a global population of nearly 8 billion people. This gap between how much data is captured and how much information can be at most retained is widening by the day, making it an ever-more pressing concern for any organization dealing with privacy-sensitive data.
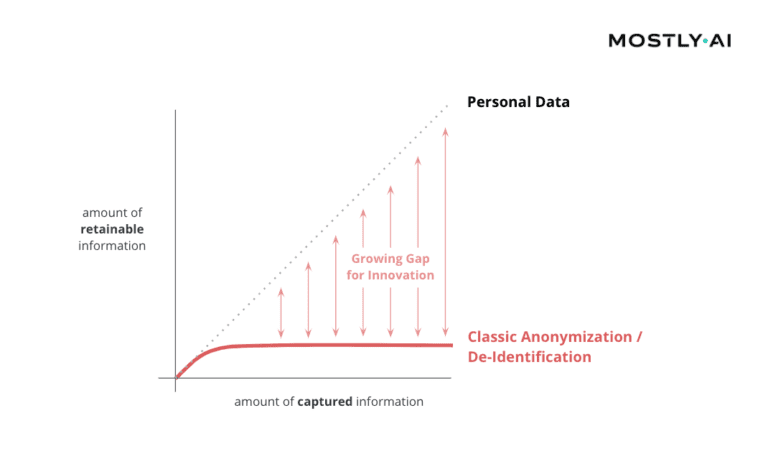
In particular, as this limitation is true for any of the existing techniques, and for any real-world customer data asset, as has already been conjectured in the seminal 2008 paper on de-anonymizing basic Netflix ratings:
“[..] the amount of perturbation that must be applied to the data to defeat our algorithm will completely destroy their utility [..] Sanitization techniques from the k-anonymity literature such as generalization and suppression do not provide meaningful privacy guarantees, and in any case fail on high-dimensional data.”
So, true anonymization is hard. Is this the end of privacy? No! But we will need to move beyond mere de-identification. Enter synthetic data. Truly anonymous synthetic data.
Head over to Part II of our blog post series to dive deeper into the privacy of synthetic data, and how it can be assessed.
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
Last Thursday the European Court of Justice published their verdict on the so-called Schrems II case: See the full ECJ Press Release or The Guardian for a summary. In essence, the ECJ invalidated with immediate effect the EU-US Privacy Shield and clarified the obligations for companies relying on Standard Contractual Clauses (SCC) for cross-border data sharing. This verdict, the culmination of a year-long legal battle between data privacy advocates, national data protection authorities, and Facebook, came to many observers as a surprise. In particular, as the Privacy Shield has been established as a response to yet another ECJ ruling made in 2015, that already recognized the danger of US surveillance for EU citizens (see here for a timeline of events). However, the ECJ makes the case that the Privacy Shield is not effective in protecting the personal data of European citizens, a recognized fundamental right, in particular with respect to (known or unknown) data requests by US intelligence agencies, like the NSA.
Let’s take a step back: Personal data is protected within the EU based on the General Data Protection Regulation (GDPR) and other previous regulations (e.g. Charter of Fundamental Rights). With this unified regulation, it is relatively easy to move personal data across borders within the European Union. However, data transfer to a third country, in principle, may only take place if the third country in question ensures an adequate level of data protection. The data exporter needs to ensure that this adequate level of data protection is given. Because this is difficult and cumbersome to do on an individual basis, the data transfer to the US has been granted a particular exemption via the EU-US Privacy Shield in 2016. It is this exemption that has now been recognized as being invalid from its beginning.
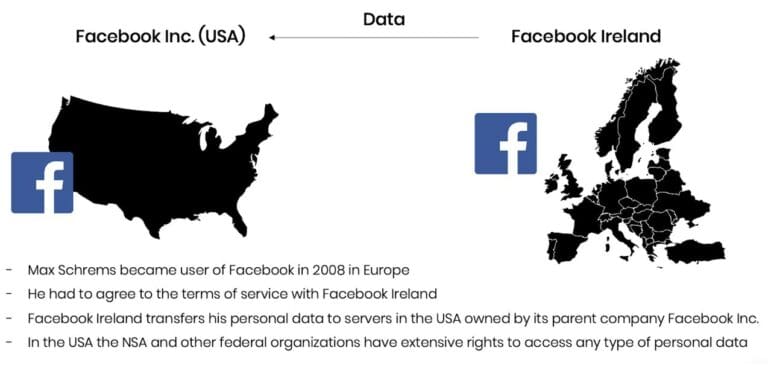
Max Schrems, privacy advocate and party in the case, expressed relief and satisfaction in a first reaction to this verdict. The non-profit organization NOYB, which he founded, shared their view on the ruling in their first reaction. In particular, the clear call to action towards national Data Protection Authorities was highly welcomed, as the GDPR relies on these in order to be truly effective. Several privacy law firms followed suit over the last couple of days and published their perspectives. E.g., Taylor Wessing also emphasizes that while standard contract clauses remain valid, they are not to be seen as a "panacea”. The obligations to assess the legality of a cross-border data transfer remain with the data exporter and data importer and need to be studied on a case-by-case basis, which typically incurs significant costs, time, as well as legal risks. As it has been shown by the ECJ verdict itself, even the European Commission was proven to be wrong in terms of their judgment when negotiating the Privacy Shield in the first place.
Bottom line is that this ruling will make it even more difficult for organizations to legally share any personal data of EU citizens from the EU to the US, as well as to other third countries. This impacts the sharing of customer data just as well as employee’s data for multinational organizations. And this ruling comes on top of a global trend towards tighter data sovereignty and data localization laws taking effect (see here).
All that being said, it is important to remember that none of this applies to non-personal data. While most existing anonymization techniques need to destroy vast amounts of information in order to prevent re-identification, it is the unique value proposition of synthetic data that finally allows for information to flow freely at granular level as needed, without infringing individuals’ fundamental right for privacy. Rather than sharing the original, privacy-sensitive data, organizations can thus share statistically representative data and circumvent the restrictions on personal data.
Our economy increasingly depends on the free flow of information. It’s broadly recognized, and yet, at the same time, the need for strong privacy is more important than ever before. Synthetic data is a solution that offers a viable way out of this dilemma.
We are facing an unprecedented crisis that has changed our daily life in several ways and that spans virtually all aspects of society. The coronavirus disease 2019 (COVID-19) outbreak, caused by a new strain of coronavirus, had its first infection in humans in late 2019. In the meantime, it has spread to 6 continents and affected over 5 million people worldwide. This gave rise to new challenges, both to our political leaders and ourselves and the social, economic, and political ramifications of this crisis are still to be fully appreciated.
On the other hand, innovation often emerges in response to extreme needs, and there are previous examples of societal crisis-induced shifts. The Black Death, in the 14th century, may have shifted the future of Europe by ending feudalism and starting the foundations of the Renaissance movement. World War II not only led to the increased participation of women in the labor force but also triggered technological innovations such as the jet engine, computers, the radar, and penicillin. In times like this, collective shifts in social attitudes were eventually transformed into policy shifts, with long-lasting effects in society.
To the extent that we can envision a positive aspect arising from the current pandemic, without forgetting the many lives lost, is that this may again be a time of opportunity and innovation. Indeed, different industries are already adjusting to the current needs and jumping in to help. From beermakers and distilleries that shifted production to hand sanitizers, to engineering companies and universities which developed and made new parts freely available, or even open-source ventilators – everyone is trying to do their part.
COVID-19 and the Global Big Data Problem
Over the last years, we have been gathering data in unprecedented amounts and speed. Since the start of the pandemic, this has been intensified. Relevant authorities are rushing to gather data on disease symptoms, virus tracking (affected people), availability of healthcare resources, among others, in an attempt to understand the outbreak and eventually control it. But there are two valuable tools that will guide our knowledge of the scale of the outbreak – testing and tracing. Testing is crucial for quickly identifying new cases, understanding how prevalent the disease is, and how it is evolving. Tracing, on the other hand, can give us contact networks. It can help to stop new cases by warning individuals of potential contact with infected people. This may be especially important in tracking the second wave and during the deconfinement.
Data has thus become the main resource to guide our collective survival strategy. At this stage, Big Data, machine learning, and artificial intelligence (AI) have the potential to make a difference by guiding political leaders and healthcare providers in the fight against the pandemic. Tech companies that used to profit from these technologies, are rallying to help governments and healthcare organizations cope with the situation. Previously unusual partnerships are already forming more frequently and more rapidly, namely between governmental or academic departments and private companies. Google and Apple, traditional competitors, have joined forces to create an API that would facilitate each countries’ tracing apps to work on both operating systems, and it is compliant with stricter privacy restrictions.
However, extracting useful knowledge from the data being collected will require a collaborative effort. In addition to the big data problem, we will need to form teams whose expertise span different areas. Within healthcare, academia, and industry, people are used to working in their own fields. However, this is an interdisciplinary problem, and expertise from computation and AI, as well as biomedical sciences, epidemiology, and demographic modeling will need to be merged to find effective solutions. Facebook’s Data for Good program has created and made available data maps and distribution of infected individuals and the density of at-risk populations. Public health researchers have used this information across Asia, Europe, and North America.
Big corporations mining our data have been at the forefront of privacy discussions in recent years. The outbreak may well be a blessing for big tech companies that saw mistrust against them grow over the past years, as people became increasingly aware of the misuse of private information. The situation is posed for them to provide a positive contribution to a global problem to which everyone can relate. Another important point is the adoption of Big Data and AI solutions which are set to increase, as data science teams all around the world are being called to crunch petabytes of data and build prediction models for decision-makers. These solutions, if made safely available, may help us find treatments sooner and design effective contingency plans to help counteract the negative consequences of the aftermath of the outbreak. In fact, officials are more open to adopting new measures in the face of great economic and social challenges.
Are We Entering a New Era of Digital Surveillance?
China is the pivotal example of digital surveillance. The culture was already in place and was intensified during the outbreak. Thermal scans are a norm in public transportation, and security cameras that track every citizen's movements are widespread. This enables health officials to quickly track potential new cases as whoever shows high temperature is immediately detained and undergoes obligatory testing. Together with access to government-issued ID cards from every passenger, the police can quickly alert anyone that has been in contact with infected people, and instruct them to be quarantined.
This, coupled with the broad network of security cameras that track people breaching quarantine orders, enables authorities to have a tighter grip on the outbreak. Mobile phone data is also a rich source of information to track its citizens’ movements. Integrating data from “Close Contact Detector” apps and travel reports from telecom companies has enabled the country to build a strong response to the outbreak.
However, digital surveillance is on the rise worldwide. Other countries are considering implementing, or have already implemented, some version of location-data monitoring, including Belgium, UK, USA, China, South Korea, and Israel. The downside of such systems is a lack of privacy by design. Weak privacy laws in most countries, along with inadequate or insufficient anonymization technologies, expose the dangers of uncontrolled surveillance. In some countries, there have been concerning privacy violations, with personal health data being made public in Montenegro and Moldava, cyberattacks on hospital websites in Croatia and Romania, and imposed surveillance and phone tracking in Serbia.
Indeed, accessing mobile phone data has the potential to be a game-changer in the fight against the pandemic. Location data, that gather information of how people move through space over time, and contact tracing, identification of persons who may have come into contact with an infected person, are powerful sources of information that – if used in a correct and fair manner – could help monitor the progress of the pandemic by tracking how effective lockdown measures are and by helping to create a contact network.
Despite its intensive media coverage nowadays, the usage of location data is not new to fighting the spread of diseases. Prominent cases include the fight against malaria, dengue, and more recently, Ebola. Even though there was a commitment to tackle these problems by specific entities, like the Bill and Melinda Gates Foundation with the participation of Microsoft, these were not diseases that impacted the world on a global scale, therefore, no global solutions were pursued. But with high penetration rates (up to 90%), and reaching less developed countries, mobile phones can become a primary data source to tackle global crises.
Location data includes traditional Call Detail Records and high-frequency x-Detail Record (xDR), which provide real-time traffic information. Both are able to track the disease dynamics and are used by governmental agencies and industry, like Google or Facebook. Furthermore, there is already evidence where location data could help track a population’s compliance with social distancing measures. However, since this data includes social life habits, it is considered legally sensitive and subject to higher security standards and the requirement of the individual’s expressed consent.
Contact tracing is also a powerful source of information since it can trace and notify potentially infected people using contact lists, by tracking nearby cell phones via Bluetooth or GPS signals. This is potentially very effective, however, also problematic, as evidenced by this experiment where they estimated that 1% of London installing a malicious app could allow a digital attacker to track half of the London population without their consent.
But for this measure to be effective, we need a high penetration rate. Most people need to feel comfortable downloading and uploading content and personal information. Of course, in theory, this should be anonymized data where all personally identifiable information is removed. However, this Spatio-temporal data, is, unfortunately, very hard to anonymize. Research has shown that it is possible to re-identify 95% of individuals with only 4 places and times previously visited. Moreover, research from UCLouvain and Imperial College London built a model to evaluate deanonymization potential of a given dataset. For instance, 15 demographic attributes can render a unique 99.98% of a population the size of Massachusetts, which is made even easier for smaller populations. Other times it can be modified to track movements of groups of people, with no unique individual identifiers, referred to as aggregated data. But even aggregated data can be vulnerable to revealing sensitive information.
Thus, there is a need to find more effective ways to make this data safely available. There are currently a few privacy-oriented models enabling the secure anonymization of this data and we at MOSTLY AI are at the forefront of developing these solutions.
Fighting This Crisis Without Sacrificing Privacy
Many Asian countries learned to balance transparency with security and privacy from previous outbreaks. While there are clear compromises to be made, this should be done without risking personal identification. South Korea and Taiwan are examples of societies that have learned to leverage the power of digital data and the sharing of information to respond to pandemics. As a consequence of the SARS outbreak, they built a culture of trust where more flexible privacy regulations are adopted during times of epidemics, with clear consent from the population. Afterward, the data is owned again by the individuals that have the right to “be forgotten”.
The western world now has the opportunity to learn from the pandemic and use digital data to improve the rebound period. Even Margrethe Vestager, one of the forefront advocates for digital privacy laws, admits that tradeoffs have to be done during a time of crisis. However, this should not mean we enter a new age of digital surveillance.
Nowadays society seems primed for discussions around AI and data privacy, and the potential risks and benefits from new technologies. More people are aware of the possible dangers of uncontrolled information sharing and are therefore asking to be informed regarding the use and conditions of usage of their data. Most of us are debating the balance between ensuring a proper fight against the disease and ensuring our safety, versus blindly submitting to mass surveillance. What is the sweet spot? The final goal should be to track the virus and not surveil citizens.
The Global AI Ethics Consortium (GAIEC) on Ethics and the Use of Data and Artificial Intelligence in the Fight Against COVID-19 and other Pandemics has recently formed and is debating these issues. This consortium believes that there are potential risks in making decisions that will affect society in the long run based on problems affecting us in the present and forced by a health crisis. Their overall goal is to provide support and expertise in ethical questions relating to COVID-19, as well as to facilitate interaction by creating open communication avenues and possible collaborations.
As said before, the COVID-19 pandemic could be viewed as a call to action to determine how access to data could be improved. Since these issues require strong technical solutions, the innovations happening now could have an impact not only in times of crisis but also on how we see and act on modern society going forward.
Synthetic data is one of those technical solutions. Synthetic data, as the name suggests, is data that is artificially generated. Most often it is created by funneling real-world data through complex mathematical algorithms that capture the statistical features of the original information. It is highly accurate and as-good-as-real without being a copy of the original dataset. Due to the fact that synthetic data is generated completely from scratch, it is also fully anonymous and therefore ensures that individuals' privacy stays protected. Synthetic data is also exempt from data protection regulations; thus amenable to several opportunities for usage and sharing that are not possible with the original data. With our clients, we have seen that synthetic data makes data sharing easy while boosting collaborations - and we are convinced that synthetic data has tremendous potential to speed up our response to future crises.
Conclusion
This pandemic has tested the resilience and adaptability of governments and entire societies. And even though the world has overcome pandemics before, nowadays we have unprecedented tools that can turn the odds in our favor. We have the ability to gather and share data on a global scale. By upholding privacy rights and increasing transparency throughout the whole process, we may also increase people's trust and potentially change society’s relationship with these technologies. In fact, we can arise from the crisis with a more innovative, responsive and data-literate society, that is better equipped to handle similar emergencies in the future, as well as with strong collaborations that may go beyond the COVID-19 outbreak.
Whether you’ve just heard about synthetic data at the last conference you attended or are already evaluating how it could help your organization to innovate with your customer data in a privacy-friendly manner, this mini video series will cover everything you need to know about synthetic data:
- What is it? (Pssst, spoiler: a fundamentally new approach to big data anonymization)
- Why is it needed?
- Why classic anonymization fails for big data (and how relying on it puts your organization at risk)
- How synthetic data helps with privacy protection,
- Why it is important that it is AI-generated synthetic data & how to differentiate between different types
- And lastly, synthetic data use cases and insights on how some of the largest brands in the world are already using synthetic data to fuel their digital transformation
1. Introduction to synthetic data
2. Synthetic Data versus Classic Anonymization
3. What is Synthetic Data? And why is AI-generated Synthetic Data superior?
4. Why Synthetic Data helps with Big Data Privacy
5. How Synthetic Data fuels AI & Big Data Innovation
As of January 1, 2020, the California Consumer Privacy Act (CCPA) went into effect, forcing many U.S. companies to improve their privacy standards, Thanks to the European Union's General Data Protection Regulation (GDPR), some organizations were prepared for this change and well equipped to handle the shift in compliance requirements. While other organizations scrambled to meet new privacy standards, some turned to AI for a helping hand- which we’ll get to later but first, let’s define the privacy law everyone’s talking about.
The CCPA In a Nutshell
Generally speaking, the CCPA impacts any company, regardless of physical location, that serves California residents and:
- Brings in annual revenue of $25 million or more,
- Handles personal data of at least 50,000 people, or
- Earns more than half its revenue selling personal data.
To be clear, these companies do not need to be based in California or even the United States, to fall under this law.
Facebook's Polarizing Reaction to the CCPA
Although a few exceptions to the rule above exist, it appears Facebook would be governed by the CCPA. Facebook brings in billions of dollars in revenue each year, collects personal data from over two billion people (with millions of users living in California – the same state where its headquartered), and earns the majority of its revenue through targeted advertising to its users.
Despite that, Facebook is taking a coy yet combative stance with regards to the CCPA’s application. In a December blog post by Facebook, it states:
We’re committed to clearly explaining how our products work, including the fact that we do not sell people’s data.
Facebook is adamant it does not sell user data and as such, it’s encouraging advertisers and publishers that use Facebook services “to reach their own decisions on how to best comply with the law.” Facebook is attempting to shift responsibility to the companies that use Facebook for advertising purposes. To some, this may seem a bit surprising, however, their position aligns with previous arguments associated with privacy lawsuits dating back to 2015.
Facebook is drawing a line in the sand. My interpretation of Facebook’s blog post is this: We do not sell the data we collect. We merely offer a service to help businesses advertise. As such, we’re exempt and the CCPA does not apply. Regardless, we’re CCPA compliant and have invested in technology to help our users manage their privacy.
Recall above, I mentioned there are a few exceptions to the rule. Well, per the CCPA, some “service providers” are exempt. Service providers require data from others to offer their services and in these situations, the transfer of data is acceptable. Facebook doesn’t technically “sell” user data; Facebook simply makes it easy for companies to advertise to targeted individuals on its platform by leveraging the personal data it collects.
Facebook is taking a clever stance but legal experts are not convinced it will hold in the court of law. Some believe Facebook does not fall under the “service provider” exemption because it uses the data it collects for other business purposes in addition to providing advertising services. Therefore, Facebook would not be exempt and the CCPA should apply.
Potential Penalties for Facebook
In 2019 alone, 27 companies, including Google, Uber and Marriott, received penalties totaling over €428 million. With the CCPA now in effect, fines from both the GDPR and CCPA are expected to reach billions in 2020.
If a business fails to cure a CCPA violation within 30 days of notification of noncompliance, the business may face up to $2,500 per violation, or $7,500 per intentional violation. For example, if a company intentionally fails to delete personal data of 1,000 users who made those requests, the resulting penalty could be $7.5 million.
So, what could this look like for Facebook? Well, according to estimates and calculations by Nicholas Schmidt, a lawyer and former research fellow of the IAPP Westin Research Center, Facebook “could face a rough full maximum penalty of $61.6 billion for an unintentional violation affecting each of its users and up to $184.7 billion for an intentional violation.” That’s a whole lot of cash, even for a company worth over $500 billion. This may explain why Facebook has taken steps to help people access, download and delete their data, in accordance with the CCPA.
Despite Claiming CCPA Exemption, Facebook Makes Effort to Comply
The CCPA provides consumers with new data privacy rights, including the right to data collection transparency, the right to opt-out, and the right to be forgotten.
Essentially, consumers have the right to know what data of theirs is being collected, if their data has been shared with others, and who has seen or received their data. Consumers also have the right to opt-out, or in other words, prevent the transfer or “sale” of their data. And even if they opt-out, they still have the right to receive the same pricing or services as those who have not. Equally as important, consumers have the right to access their own personal data and request its deletion.
The CCPA borrowed the “Right to be Forgotten” aka the “Right to Erasure” from the GDPR and applies its similar variation as the “Right to Request Deletion”
When I prepared this blog post, I learned that Instagram (which is owned by Facebook) has made it incredibly easy for people to review and download their personal data. Rather than forcing users to jump through hoops, send email requests, and wait 45 days for a reply, Instagram has streamlined the request and data review process required under the CCPA. It took me only a minute to send a request to download data and to exercise my “right to request deletion”. Viewing my account and advertising data was simple and straightforward too:
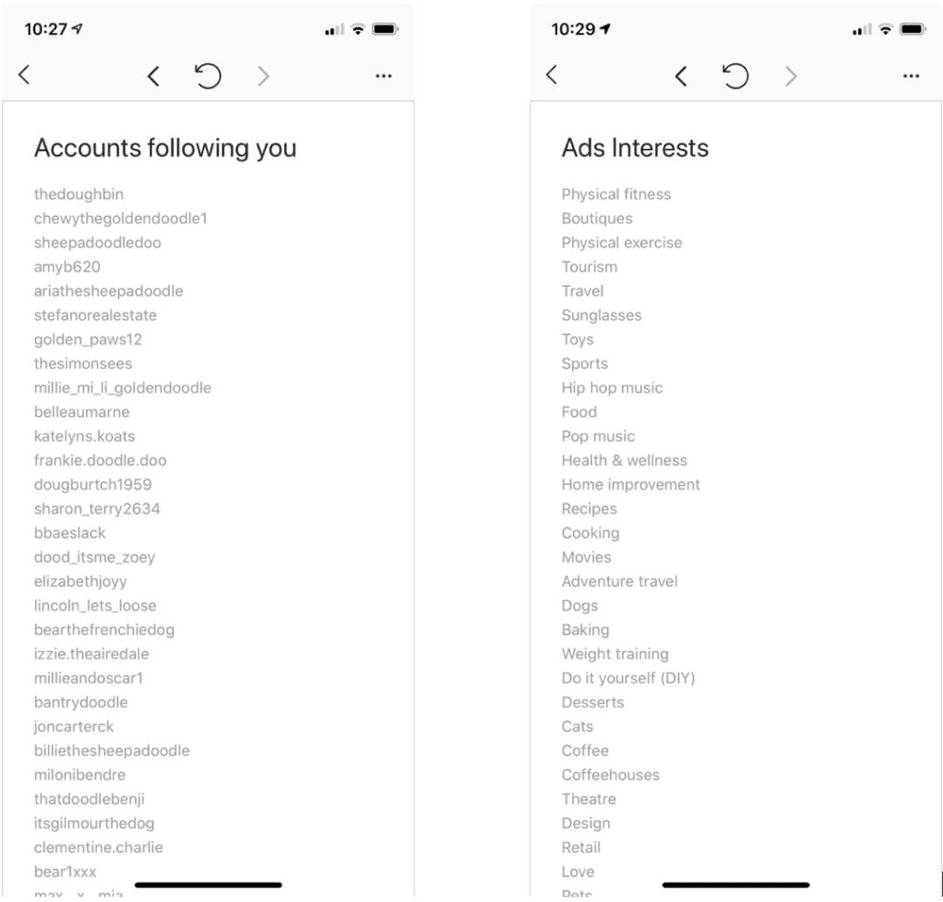
Facebook is going above and beyond in an attempt to meet CCPA compliance for all users, regardless of where those users reside. Based on their updated user experience for CCPA inquiries and data reporting, it seems like Facebook is aware it falls under the law – regardless of what it states on its blog.
Lessons Learned from Facebook and How To Use AI for Compliance
The CCPA influences how businesses collect, store and share data, which continues to create ripple effects of improved policies and procedures nationwide.
In an effort to meet CCPA compliance, Facebook provides a great example of how to embrace artificial intelligence and self-serving tools to help individuals manage privacy. Despite Facebook’s position on the CCPA, we’ve seen how they’ve updated their “help center” and automation flow to meet the requirements of this new law. Some companies, however, are handling privacy requests manually, one email at a time, which is resulting in additional work for its employees. Others are turning to artificial intelligence to handle these tasks while improving security, compliance and data protection.
To prevent fraud, organizations are using AI to verify user identity before allowing people to download their personal data. Some businesses are using AI-powered chatbots to efficiently answer privacy related questions and manage data access. In addition to fraud detection and customer support, companies are using AI to generate synthetic data for CCPA compliance. This saves companies hundreds of hours of time spent masking personally identifiable information and empowers organizations to train machine learning algorithms regardless of how much customer data has already been (or will be) deleted.
Artificially manufactured synthetic data appears just as real to the naked eye but contains no personal information from actual users. Since it’s generated by an algorithm that learns the patterns and correlations of raw data before using this knowledge to create new, highly realistic synthetic data, it’s completely anonymous and untraceable to any individuals. Therefore, synthetic data can be freely shared amongst teams without the risk of reverse engineering any users’ identities or personal information. It’s with this advancement in technology that companies can protect the privacy of its users and continue to make data-driven decisions.
Organizations around the globe, including Amazon, Apple, Google and Uber are now using synthetic data. It’s an incredible tool to train AI and leverage data previously collected without putting any of your customers at risk. It’s GDPR and CCPA compliant, and rumor has it, Facebook is already using synthetic data too.
If you focus on compliance, AI, or anywhere in between, we’d love to hear how you’ve embraced the CCPA. You can contact us here, anytime, for a fun conversation or friendly debate.
Why Privacy Matters?
“Knowledge is power” should be a familiar quote for most of us. But did you know that in the earliest documented occurrence of this phrase from the 7th century the original sentence finishes with “…and it can command obedience”? If we apply this idea to personal information it’s easy to understand why privacy matters. Nobody wants to be at the receiving end.
Today privacy is recognized as one of the fundamental human rights by the UN and protected through international and national level legislation. Not complying with privacy regulations can be very costly if not a business-threatening risk for organizations working with their customers’ data.
Should We Trust Blindly?
Never before has it been as difficult as now to preserve individuals’ privacy. People have lost track and control of what kind of personal data, how much of it, why and where it is being collected, stored and even sold further. From “1000 songs in our pockets” (Apple’s first iPod slogan) we moved to an endless number of apps and trackers in our pockets, recording our daily activities. In our homes as well as in public spaces, devices with sensors and meters record every step and action we take.
As an individual, it’s wise to question if the consent given to a data controller is compliant with current privacy regulations. Because sometimes data controllers turn to the Dark Side by collecting unnecessary data, sharing data with third parties, failing to protect data appropriately or using it in a discriminatory way against the data subjects.
The Industry’s Dirty Secret About Privacy
But even the data controllers who are not crossing the legal red lines are struggling more and more to protect their customer’s data at rest as well as in motion. Their life would be much easier if customer data could be locked up in a safe. But data, if not the new oil of our economy, is for sure the lubricant necessary to keep the business machine running. This means that every company needs to expose its customer’s data at least for the following purposes:
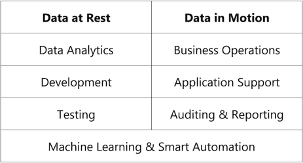
Often it’s not the bad intention but simple incapability of data controllers to comply with privacy regulations because the instruments at their hands are not capable of securely anonymizing data without destroying all of the utility in it. I remember many discussions with data security officers at different companies admitting that their current processes aren’t compliant but as long as there is no technical fix they can’t stop the machine that’s running.
What do those data security officers mean when they say that there’s no technical fix for privacy compliance? Although there are many different methods to protect data like cryptography, tokenization and anonymization, all of them have some weak points when it comes to data protection.
Sometimes the weak point is the human: If cryptographic keys are compromised the privacy is lost. Sometimes, like in the case of classic anonymization techniques, the weak point is the technology. What more and more people realize is that classic anonymization (randomization, generalization,…) is at the same time an optimization problem and an uphill battle. When original data is modified it loses some of its information value and therefore its utility. The more protection the less utility and vice versa. The data anonymization engineer is continuously balancing between the legal requirements to protect the privacy of the data subjects and the business requirements to extract value out of the data.
But in the age of big data with millions of records and thousands of attributes this optimization is getting almost impossible to achieve. The more data points are being collected about individuals, the easier it gets to re-identify individuals even in large databases. For example, 80% of all credit card owners are re-identified by 3 transactions, even when only the merchant and the date of the transaction are revealed.
The anonymization trade-off has shifted to a paradox state where only useless data is sufficiently protected data. So if you have been using anonymized, granular level data for analytics or testing, the odds are high that a significant fraction of this data is actually re-identifiable and the privacy of your customers isn’t adequately protected.
This dirty secret is causing some sleepless nights in legal and security departments across various industries. What’s even scarier is that some organizations aren’t even aware of it. And the only thing worse than not protecting your customer’s privacy is acting with the false impression that you are doing it, which leads to organizations taking their guard down to freely share poorly anonymized information internally and externally.
The trouble is on the horizon. In 2019 GDPR fine total went up to almost 500 million Euros and it wouldn’t surprise me if this amount would double in 2020. But the legal fines aren’t the biggest trouble awaiting data controllers.
What Happens When Privacy Is Breached?
Nowadays, data breaches happen more frequently even when access to sensitive data is restricted. According to IBM, the odds of experiencing a data breach went up 31% in the last 5 years to a 29% likelihood of experiencing a data breach in the next two years. Data snoopers are the bank robbers of the 21st century. The average total cost of a data breach is millions of Euros and that doesn’t only consist of regulatory fines. The biggest cost factor of a data breach is the loss of reputation that directly leads to the loss of business.
This Sunday a story was published in British media holding all the components of a perfect privacy nightmare: a data breach of a governmental database containing personal information of about 28 million children. The breach happened through the access that the UK government has granted to an educational and training provider.
Just imagine what horrible things could be done with that data. Now go through your diabolical list and strike out “selling children’s private data to betting firms” – this task has already been successfully accomplished. How successfully? According to UK media, betting companies were able to significantly increase the number of children passing their identity checks and have used the stolen data to increase the number of young people who gamble online. The house always wins.
And there’s no sign that the winning streak of data adversaries will break anytime soon. Every year we see the number of data breaches and the volume of exposed sensitive data captured rising. With a total of 550 million leaked records last year, the 28 million data records of the recent breach in the UK will hardly break the top five data breaches of 2019.
The types of breaches go from incompetency like accidental exposure, employee error, improper disposal or lost to intentional theft like hacking, insider theft, unauthorized access, and even physical data theft.
In the dark web the data is offered to other criminals or even legal entities like the betting companies in the example above, as well as social media organizations who use this data among others to check if their own passwords were indirectly exposed.
What Are The Alternatives?
The list of things that could be done to reduce privacy risk is long. When data is in motion, for example during business process operations, data controllers will continue to use cryptography and tokenization as preferred methods to protect data in operative applications. For data at rest used for data analytics, development & testing, machine learning and open innovation there are new innovative ways to truly anonymize data and fix the privacy vs. utility trade-off once for all.
AI-generated synthetic data is THE way forward to preserve the utility of data while protecting the privacy of every data subject. This innovative approach was only possible thanks to the progress in the field of artificial intelligence. Generative deep neural networks can be trained on the original structured data to then be used to generate new synthetic data points. These new synthetic datasets preserve all the correlations, structures and time dependencies present in the original data. Customer-related events like financial transactions, online-clicks, movements etc. can be synthesized and all the important insights contained in the original data can be preserved in the synthetic dataset. And at the same time there’s no way to re-identify the original customer.
With synthetic data, the way to do machine learning with anonymous “full privacy-full utility” data is wide open. The evaluation results obtained by doing machine learning on synthetic data are very similar to those generated from the original data. Application testing with synthetic data is able to cover the edge cases which are normally covered only in the original data. And the performance tests of the applications are not a problem anymore because synthetic test data, in contrast to original data, isn’t scarce anymore. Millions of synthetic records can be produced with the click of a button.
With AI-generated synthetic data being used more and more, data security and legal departments will finally be able to sleep easier. At the same time, the data scientists and development & testing teams will be able to focus on more productive tasks and won’t get distracted by legal and security requirements. Trust is good, control is better, but no dependency on trust is the best.
And what about data adversaries? What would happen if they manage to steal 28 million synthetic records of UK children like in the story above?
Nothing.
These data adversaries would be sitting on terabytes of artificially generated data: nothing more than a high-quality-look-a-like dataset. They’d be painfully disappointed to discover that re-identifying any of the 28 million UK kids would not be possible. And you can bet on that.
Netflix has been working on a recommender systems for years by then, were recognized for their business innovation as well as technical excellence, managed to hire the smartest data engineers and machine learning experts alike, and certainly knew all the ins and outs on movies, genres and popular actors. Still, they were eager to learn more.
The competition began on October 2nd, 2006. Within a mere six days a first contestant succeeded in beating their existing solution. Six days! From getting access to the data and taking a first look, to building a movie recommender algorithm from scratch, all the way to making more accurate predictions for over a million ratings than anyone before. Six days, from zero to world class.
It didn’t stop there. Within a year, over 40,000 teams from 186 countries entered the competition, all trying to improve on Netflix’ algorithms. And contestants increasingly started collaborating, sharing their learnings and taking lesson from others, formed bigger teams and ensembled ever more powerful models. Hardly ever before was there such a rich & big dataset on consumer behavior openly available. Together with a clearly stated and measurable objective, it provided a challenging, yet safe and fair sandbox for a worldwide community of intellectually driven engineers. All working together on advancing science, while, as a more than welcome side effect, also helping Netflix improve its core algorithm.
The Case for #OpenBigData
Being open enables to pick the brain of a wider group, to bring in fresh perspectives to existing challenges, to build upon the creative minds of the many. And with data being the lingua franca of today’s business world, being the common denominator across departments, across corporations, across industries, being open is really about sharing data, about sharing granular level data at scale!
Openly sharing customer data at scale in 2006 was a bold move. But it was no coincidence that it’s been done by Netflix. Already in their early years they successfully established a culture of excellence, curiosity as well as courage, well documented in “one of Silicon’s valley’s most important PowerPoint decks” [1]. Sharing data broadly takes courage, but is even more so a sign of curiosity and a thrive for excellence. No holding back, no hiding out, no making excuses. Netflix was never afraid of their competitors. They were afraid of stopping to strive for the best.
Openly sharing customer data at scale in 2019 is an (unl)awful move. Over the past years, the explosion in data volumes met a poorly regulated market, with little sanctions being imposed, and thus allowing excessive misuse of personal data. The tide though has turned, both the regulators as well as corporates are acknowledging privacy as a fundamental human right, one that is to be defended [2]. This is indeed a new era of privacy.
Unfortunately, this plays into the hands of modern-day corporate gatekeepers. Those decision makers, who’ve never really been fond of being transparent and being challenged, and thus reluctant to share “their” data in the first place. It turns out they found a new ally in defending their corporate data silos: privacy.
The Case for #SyntheticData
This is the point where one needs to tell the lesser known part of the Netflix Prize story: As successful the competition was for the company overall, they also had to pay their prize at court. In fact, they were forced to cancel their second machine learning challenge, that was planned for 2011 [3]. Netflix had misjudged their anonymization measures they’ve had put in place. Even though they limited data to movie ratings and their dates, merely linked to a scrambled user ID, it proved inefficient to prevent re-identification. It had taken only 16 days, after the data was released for an outsider (with no superhuman hacking skills) to link these user IDs with freely available public data – with enough time left at hand to write up a whole paper on de-anonymization [4]. Netflix had unintentionally exposed the full movie history for parts of their customer base, with no chance of making that privacy infringement undone. A decade later Facebook had to learn that same painful lesson. Once the data is out and you failed to properly anonymize, no matter how good your intentions might have been, you will have a hard time to undo your actions.
This risk of re-identification in large-scale data is by now well understood by privacy and security experts [5], and yet still widely under-estimated by the corporate world. That’s why these experts face a challenging role within organizations, as they need to educate their colleagues, that most anonymization attempts for big data in fact fail to provide safety for their customers. And these experts are forced to give a NO more often than a YES to a new initiative, to a new innovation project, in order to keep privacy safe and secure.
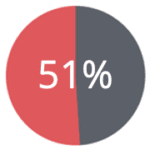
of mobile phone owners are re-identified simply by 2 antenna signals, even when coarsened to the hour of the day
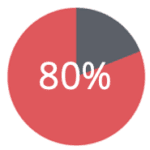
of credit card owners are re-identified by 3 transactions, even when only merchant and the date of transaction is revealed
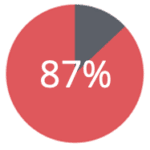
of all people are re-identified, merely by their date-of-birth, their gender and their ZIP code of residence
So, this is the big quest of our time: How to be open, while being private at the same time? How to put big data to good use, while still protecting each and everyone’s right for privacy? How to foster data-driven, people-centric and innovative societies and organizations, all at the same time, while not giving up an inch on safeguarding privacy?
We, at Mostly AI, set out to solve this challenge, and developed a one-of-its-kind technical solution to this long-standing problem: an AI-based synthetic data generator. One that learns based on actual behavioral data, to generate statistical representative synthetic personas and their data. Synthetic data, that can be broadly shared, internally as well as externally, without exposing any individuals. It’s all the value of the original data, but without the privacy risk.
This is 2019. It’s time to protect privacy, as well as to embrace the power of open again. It’s time to #GoSynthetic!