Table of Contents
What is data bias?
Data bias is the systematic error introduced into data workflows and machine learning (ML) models due to inaccurate, missing, or incorrect data points which fail to accurately represent the population. Data bias in AI systems can lead to poor decision-making, costly compliance issues as well as drastic societal consequences. Amazon’s gender-biased HR model and Google’s racially-biased hate speech detector are some well-known examples of data bias with significant repercussions in the real world. It is no surprise, then, that 54% of top-level business leaders in the AI industry say they are “very to extremely concerned about data bias”.
With the massive new wave of interest and investment in Large Language Models (LLMs) and Generative AI, it is crucial to understand how data bias can affect the quality of these applications and the strategies you can use to mitigate this problem.
In this article, we will dive into the nuances of data bias. You will learn all about the different types of data bias, explore real-world examples involving LLMs and Generative AI applications, and learn about effective strategies for mitigation and the crucial role of synthetic data.
Data bias types and examples
There are many different types of data bias that you will want to watch out for in your LLM or Generative AI projects. This comprehensive Wikipedia list contains over 100 different types, each covering a very particular instance of biased data. For this discussion, we will focus on 5 types of data bias that are highly relevant to LLMs and Generative AI applications.
- Selection bias
- Automation bias
- Temporal bias
- Implicit bias
- Social bias
Selection bias
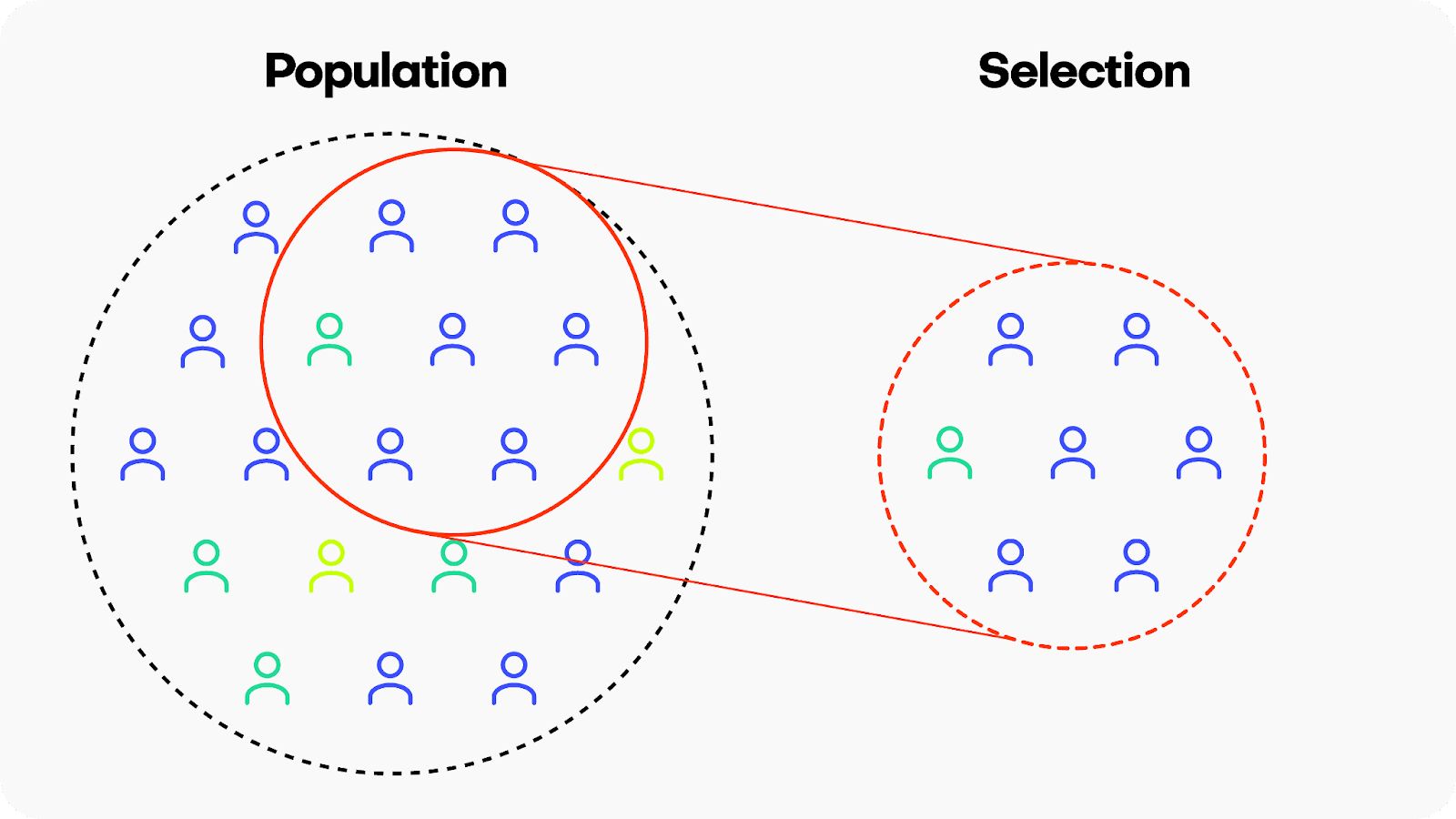
Selection bias occurs when the data used for training a machine learning model is not representative of the population it is intended to generalize to. This means that certain groups or types of data are either overrepresented or underrepresented, leading the model to learn patterns that may not accurately reflect the broader population. There are many different kinds of selection bias, such as sampling bias, participation bias and coverage bias.
Example: Google’s hate-speech detection algorithm Perspective is reported to exhibit bias against black American speech patterns, among other groups. Because the training data did not include sufficient examples of the linguistic patterns typical of the black American community, the model ended up flagging common slang used by black Americans as toxic. Leading generative AI companies like OpenAI, Anthropic and others are using Perspective daily at massive scale to determine the toxicity of their LLMs, potentially perpetuating these biased predictions.
Solution: Invest in high-quality, diverse data sources. When your data still has missing values or imbalanced categories, consider using synthetic data with rebalancing and smart imputation methods.
Automation bias

Automation bias is the tendency to favor results generated by automated systems over those generated by non-automated systems, irrespective of the relative quality of their outputs. This is becoming an increasingly relevant type of bias to watch out for as people, including top-level business leaders, may rush to implement automatically generated AI applications with the underlying assumption that simply because these applications use the latest, most popular tech their output will be inherently more trustworthy or performant.
Example: In a somewhat ironic overlap of generative technologies, a 2023 study found that some Mechanical Turk workers were using LLMs to generate the data which they were being paid to generate themselves. Later studies have since shown that training generative models on generated data can create a negative loop, also called “the curse of recursion”, which can significantly reduce output quality.
Solution: Include human supervision safeguards in any mission-critical AI application.
Temporal or historical bias
Temporal or historical bias arises when the training data is not representative of the current context in terms of time. Imagine a language model trained on a dataset from a specific time period, adopting outdated language or perspectives. This temporal bias can limit the model's ability to generate content that aligns with current information.

Example: ChatGPT’s long-standing September 2021 cut-off date is a clear example of a temporal bias that we have probably all encountered. Until recently, the LLM could not access training data after this date, severely limiting its applicability for use cases that required up-to-date data. Fortunately, in most cases the LLM was aware of its own bias and communicated it clearly with responses like "'I'm sorry, but I cannot provide real-time information".
Solution: Invest in high-quality data, up-to-date data sources. If you are still lacking data records, it may be possible to simulate them using synthetic data’s conditional generation feature.
Implicit bias
Implicit bias can happen when the humans involved in ML building or testing operate based on unconscious assumptions or preexisting judgments that do not accurately match the real world. Implicit biases are typically ingrained in individuals based on societal and cultural influences and can impact perceptions and behaviors without conscious awareness. Implicit biases operate involuntarily and can influence judgments and actions even when an individual consciously holds no biased beliefs. Because of the implied nature of this bias, it is a particularly challenging type of bias to address.
Example: LLMs and generative AI applications require huge amounts of labeled data. This labeling or annotation is largely done by human workers. These workers may operate with implicit biases. For example, in assigning a toxicity score for specific language prompts, a human annotation worker may assign an overly cautious or liberal score depending on personal experiences related to that specific word or phrase.
Solution: Invest in fairness and data bias training for your team. Whenever possible, involve multiple, diverse individuals in important data processing tasks to balance possible implicit biases.
Social bias
Social bias occurs when machine learning models reinforce existing social stereotypes present in the training data, such as negative racial, gender or age-dependent biases. Generative AI applications can inadvertently perpetuate biased views if their training data includes data that reflects societal prejudices. This can result in responses that reinforce harmful societal narratives. As ex-Google researcher Timit Gebru and colleagues cautioned in their 2021 paper: “In accepting large amounts of web text as ‘representative’ of ‘all’ of humanity [LLMs] risk perpetuating dominant viewpoints, increasing power imbalances and further reifying inequality.”
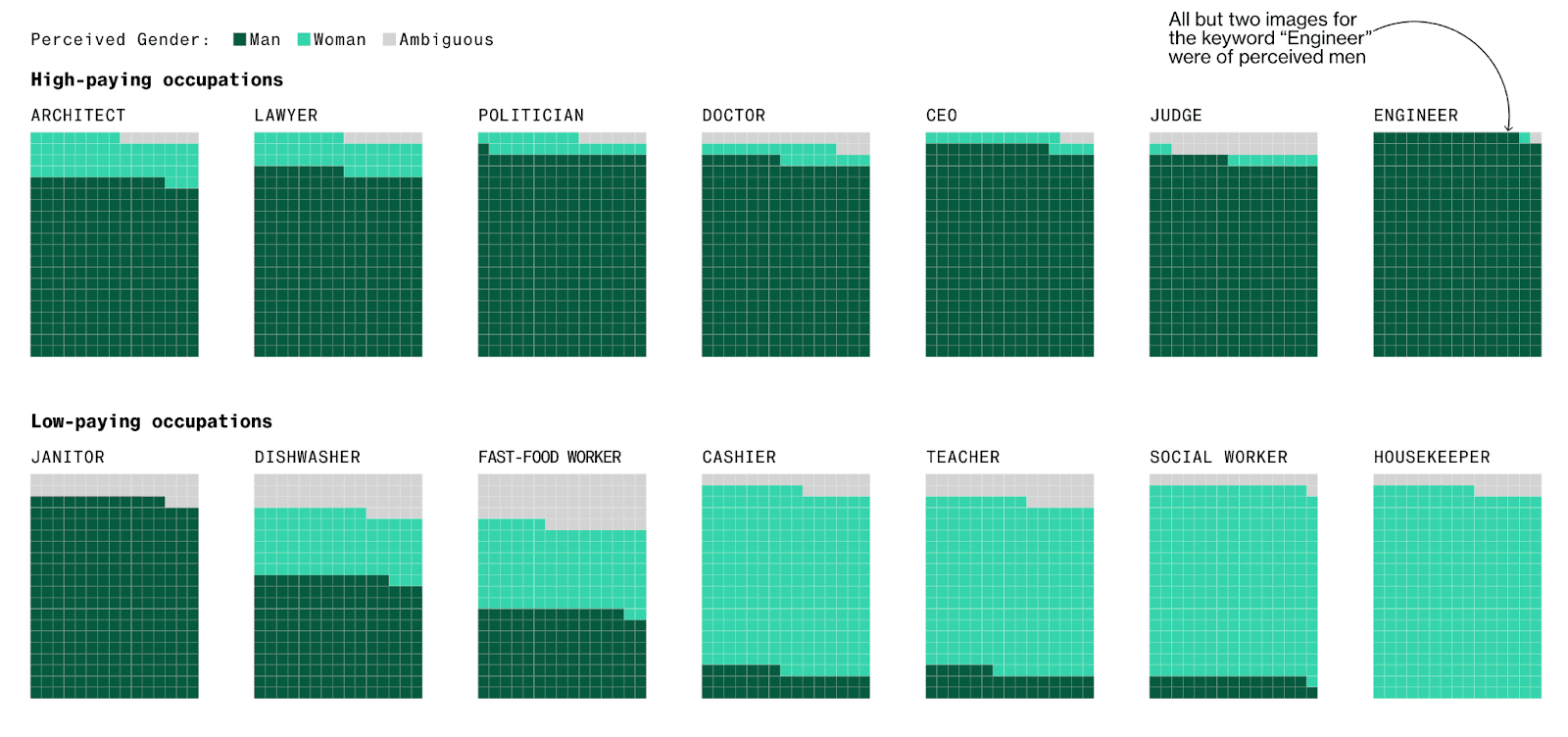
Example: Stable Diffusion and other generative AI models have been reported to exhibit socially biased behavior due to the quality of their training datasets. One study reported that the platform tends to underrepresent women in images of high-performing occupations and overrepresent darker-skinned people in images of low-wage workers and criminals. Part of the problem here seems to be the size of the training data. Generative AI models require massive amounts of training data and in order to achieve this data volume, the selection controls are often relaxed leading to poorer quality (i.e. more biased) input data.
Solution: Invest in high-quality, diverse data sources as well as data bias training for your team. It may also be possible to build automated safeguarding checks that will spot social bias in model outputs.
Perhaps more than any other type of data bias, social bias shows us the importance of the quality of the data you start with. You may build the perfect generative AI model but if your training data contains implicit social biases (simply because these biases existed in the subjects who generated the data) then your final model will most likely reproduce or even amplify these biases. For this reason, it’s crucial to invest in high-quality training data that is fair and unbiased.
Strategies for reducing data bias
Recognizing and acknowledging data bias is of course just the first step. Once you have identified data bias in your project you will also want to take concrete action to mitigate it. Sometimes, identifying data bias while your project is ongoing is already too late; for this reason it’s important to consider preventive strategies as well.
To mitigate data bias in the complex landscape of AI applications, consider:
- Investing in dataset diversity and data collection quality assurances.
- Performing regular algorithmic auditing to identify and rectify bias.
- Including humans in the loop for supervision.
- Investing in model explainability and transparency.
Let’s dive into more detail for each strategy.
Diverse dataset curation
There is no way around the old adage: “garbage in, garbage out”. Because of this, the cornerstone of combating bias is curating high-quality, diverse datasets. In the case of LLMs, this involves exposing the model to a wide array of linguistic styles, contexts, and cultural nuances. For Generative AI models more generally, it means ensuring to the best of your ability that training data sets are sourced from as varied a population as possible and actively working to identify and rectify any implicit social biases. If, after this, your data still has missing values or imbalanced categories, consider using synthetic data with rebalancing and smart imputation methods.
Algorithmic auditing
Regular audits of machine learning algorithms are crucial for identifying and rectifying bias. For both LLMs and generative AI applications in general, auditing involves continuous monitoring of model outputs for potential biases and adjusting the training data and/or the model’s architecture accordingly.
Humans in the loop
When combating data bias it is ironically easy to fall into the trap of automation bias by letting programs do all the work and trusting them blindly to recognize bias when it occurs. This is the core of the problem with the widespread use of Google’s Perspective to avoid toxic LLM output. Because the bias-detector in this case is not fool-proof, its application is not straightforward. This is why the builders of Perspective strongly recommend continuing to include human supervision in the loop.
Explainability and transparency
Some degree of data bias is unavoidable. For this reason, it is crucial to invest in the explainability and transparency of your LLMs and Generative AI models. For LLMs, providing explanations and sources for generated text can offer insights into the model's decision-making process. When done right, model explainability and transparency will give users more context on the generated output and allow them to understand and potentially contest biased outputs.
Synthetic data reduces data bias
Synthetic data can help you mitigate data bias. During the data synthesization process, it is possible to introduce different kinds of constraints, such as fairness. The result is fair synthetic data, without any bias. You can also use synthetic data to improve model explainability and transparency by removing privacy concerns and significantly expanding the group of users you can share the training data with.
More specifically, you can mitigate the following types of data bias using synthetic data:
Selection Bias
If you are dealing with imbalanced datasets due to selection bias, you can use synthetic data to rebalance your datasets to include more samples of the minority population. For example, you can use this feature to provide more nuanced responses for polarizing topics (e.g. book reviews, which generally tend to be overly positive or negative) to train your LLM app.
Social Bias
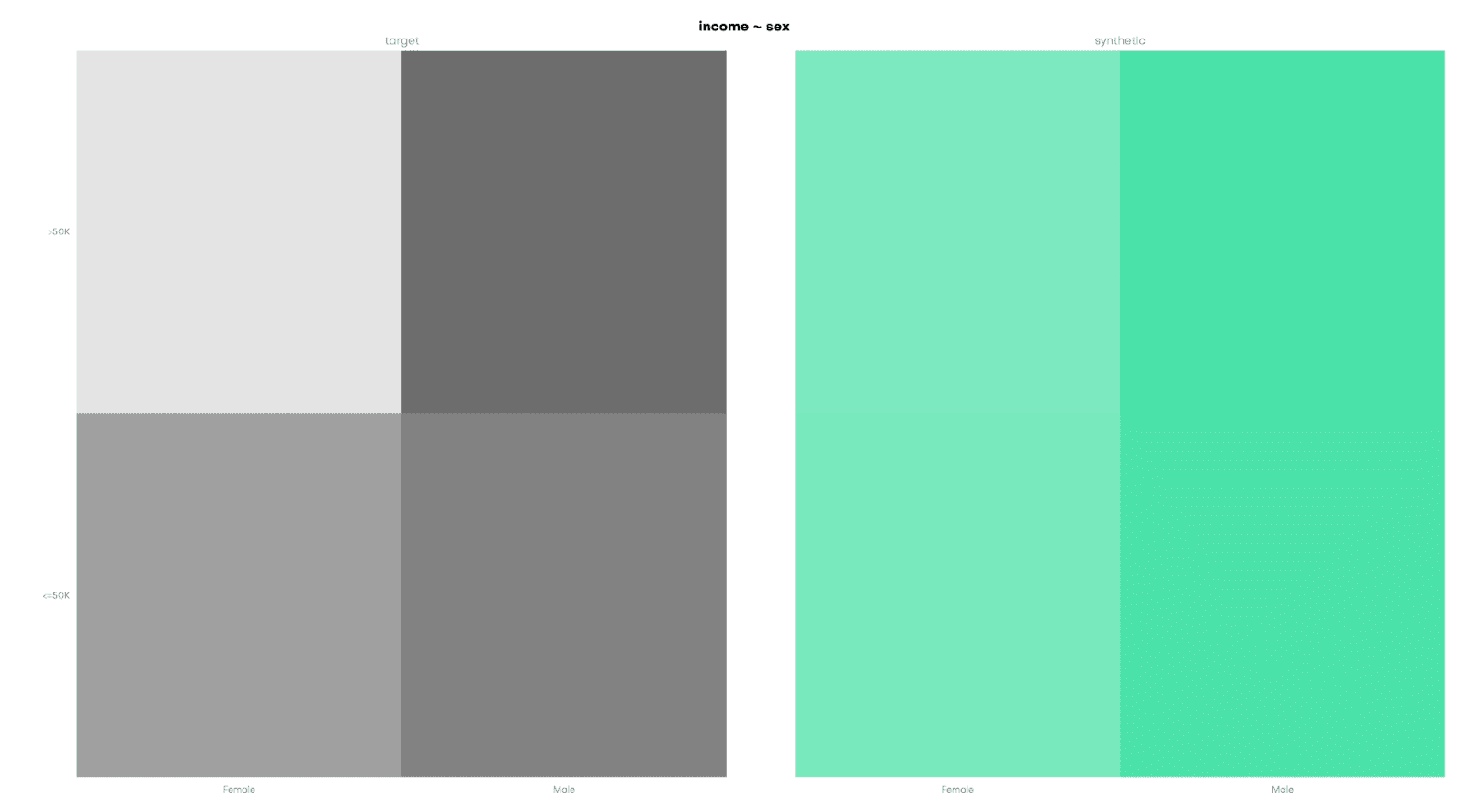
Conditional data generation enables you to take a gender- or racially-biased dataset and simulate what it would look like without the biases included. For example, you can simulate what the UCI Adult Income dataset would look like without a gender income gap. This can be a powerful tool in combating social biases.
Reporting or Participation Bias
If you are dealing with missing data points due to reporting or participation bias, you can use smart imputation to impute the missing values in a high-quality, statistically representative manner. This allows you to avoid data loss by allowing you to use all the records available. Using MOSTLY AI’s Smart Imputation feature it is possible to recover the original population distribution which means you can continue to use the dataset as if there were no missing values to begin with.
Mitigating data bias in LLM and generative AI applications
Data bias is a pervasive and multi-faceted problem that can have significant negative impacts if not dealt with appropriately. The real-world examples you have seen in this article show clearly that even the biggest players in the field of AI struggle to get this right. With tightening government regulations and increasing social pressure to ensure fair and responsible AI applications, the urgency to identify and rectify data bias at all points of the LLM and Generative AI lifecycle is only becoming stronger.
In this article you have learned how to recognise the different kinds of data bias that can affect your LLM or Generative AI applications. You have explored the impact of data bias through real-world examples and learned about some of the most effective strategies for mitigating data bias. You have also seen the role synthetic data can play in addressing this problem.
If you’d like to put this new knowledge to use directly, take a look at our hands-on coding tutorials on conditional data generation, rebalancing, and smart imputation. MOSTLY AI's free, state-of-the-art synthetic data generator allows you to try these advanced data augmentation techniques without the need to code.
For a more in-depth study on the importance of fairness in AI and the role that synthetic data can play, read our series on fair synthetic data.
Synthetic data is quickly becoming a critical tool for organizations to unlock the value of sensitive customer data while keeping the privacy of their customers protected and in compliance with data protection regulations such as GDPR and CCPA. It can be generated quickly in abundance and has been proven to drastically improve machine learning performance. As a result, it is often used for advanced analytics and AI training, such as predictive algorithms, fraud detection and pricing models.
According to Gartner, by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.
MOSTLY AI pioneered the creation of synthetic data for AI model development and software testing. With things moving so quickly in this space here are three trends that we see happening in AI and synthetic data in 2022:
1. Bias in AI will get worse before it gets better.
Most of the machine learning and AI algorithms currently in production, interacting with customers, making decisions about people have never been audited for fairness and discrimination, the training data has never been augmented to fix embedded biases. It is only through massive scandals that companies are finding out and learning the hard way that they need to pay more attention to biased data and to use fair synthetic data instead.
2. Companies’ data assets will freeze up due to regulations and declining customer consent.
Regulations all over the world are getting stricter every day; many countries have a personal data protection policy in place by now. Using customer data is getting increasingly difficult for a number of other reasons too - people are more privacy-conscious and are increasingly likely to refuse consent to using their data for analytics purposes. So companies literally run out of relevant and usable data assets. Companies will learn to understand that synthetic data is the way out of this dilemma.
3. Synthetic data will be standardized with globally recognized benchmarks for privacy and accuracy.
Not all synthetic data is created equal. To start off with, there is a world of difference between what we call structured and unstructured synthetic data. Unstructured data means images and text for example, while structured data is mainly tabular in nature. There are lots of open source and proprietary synthetic data providers out there for both kinds of synthetic data and the quality of their generators varies widely. It’s high time to establish a synthetic data standard to make sure that synthetic data users get consistently high-quality synthetic data. We are already working on structured synthetic data standards.
If you’d like to connect on these trends, we’re happy to set up an interview or write a byline on these topics for your publication. Please let us know - thanks.