We talked to test engineers, QA leads, test automation experts and CTOs to figure out what their most common test data generation issues were. There are some common themes, and it's clear that the test data space is ready for some AI help.
The biggest day-to-day test data challenges
Enterprise architectures are not prepared to provide useful test data for software development. From an organizational point of view, test data tends to be the proverbial hot potato no one is willing to handle. The lack of quality test data results in longer development times and suboptimal product quality. But what makes this potato too hot to touch? The answer lies in the complexity of test data provisioning. To find out what the most common blockers are for test architects, we first mapped out how test data is generated today.
1. Copy production data and pray for forgiveness
Let's face it. Lots of dev teams do this. With their eyes half-closed, they copy the production data to staging and hope against the odds that all will be fine. It never is, though. Even if you are lucky enough to dodge a cyberattack, 59% of privacy incidents originate in-house, and most often, they are not even intentional.
Our advice for these copy-pasting daredevils is simple: do not do that. Ever. Take your production data out of non-production environments and do it fast.
2. Using legacy data anonymization like data masking or obfuscation and destroy the data in the process
Others in more privacy-conscious industries, like insurance and banking, use legacy data anonymization techniques on production data. As a direct consequence of data masking, obfuscation, and the likes, they struggle with data quality issues. They neither have the amount nor the bandwidth of data they need to meaningfully test systems. Not to mention the privacy risk these seemingly safe and arguably widespread practices bring. Test engineers are not supposed to be data scientists well versed in the nuances of data anonymization. Nor are they necessarily aware of the internal and external regulations regarding data privacy. In reality, lots of test engineers just delete some columns they flagged as personally identifiable information (PII) and call it anonymized. Many test data creation tools out there do pretty much the same automatically, conveniently forgetting that simply masking PII does not qualify as privacy-safe.
3. Manually create test data
Manual test data creation has its place in projects where entirely new applications with no data history need to be tested. However, as most testers can attest, it is a cumbersome method with lots of limitations. Mock data libraries are handy tools, but can’t solve everything. Highly differentiated test data, for example, is impossible to construct by hand. Oftentimes, offshore development teams have no other choice but to generate random data themselves. The resulting test data doesn't represent production and lacks a balance between positive cases, negative cases, as well as unlikely edge cases. A successful and stress-free go-live is out of reach both for these off-shore teams and their home crew. Even when QA engineers crack the test data issues perfectly at first, keeping the test data consistent and up-to-date is a constant struggle. Things change, often. Test data generation needs to be flexible and dynamic enough to be able to keep up with the constantly moving goalposts. Application updates introduce new or changed inputs and outputs, and test data often fails to capture these movements.
The tragic heroes of software testing and development
It's clear that data issues permeate the day-to-day work of test engineers. They deal with these as best as they can, but it does look like they are often set up for unsolvable challenges and sleepless nights. In order to generate good quality test data, they need to understand both the product and its customers. Their attention to detail needs to border on unhealthy perfectionism. Strong coding skills need to be paired with exceptional analytical and advanced data science knowledge with a generous hint of privacy awareness. It looks like the good people of testing could use some sophisticated AI help.
What does the future of AI-generated test data look like?
Good test data can be generated without thinking about it and on the fly. Good test data is available in abundance, covering real-life scenarios as well as highly unlikely edge cases. Good test data leads to quantifiable, meaningful outcomes. Good test data is readily available when using platforms for test automation. AI to the rescue! Instead of expecting test engineers to figure out the nuances of logic and painstakingly crafting datasets by hand, they can use AI-generated synthetic data to increase their product quality without spending more time on solving data issues. AI-generated synthetic data will become an important piece of the testing toolbox. Just like mock data libraries, synthetic data generators will be a natural part of the test data generation process.
As one of our QA friends put it, he would like AI "to impersonate an array of different people and situations, creating consistent feedback on system reliability as well as finding circumstantial errors." We might just be able to make his dreams come true.
From where we stand, the test data of the future looks and feels like production data but is actually synthetic. Read more about the synthetic data use case for testing and software development!
The world is changing, and anonymous data is not anonymous anymore
In recent years, data breaches have become more frequent. A sign of changing times: data anonymization techniques sufficient 10 years ago fail in today's modern world. Nowadays, more people have access to sensitive information, who can inadvertently leak data in a myriad of ways. This ongoing trend is here to stay and will be exposing vulnerabilities faster and harder than ever before. The disclosure of not fully anonymous data can lead to international scandals and damaged reputation.
Most importantly, customers are more conscious of their data privacy needs. According to Cisco's research, 84% of respondents indicated that they care about privacy. Among privacy-active respondents, 48% indicated they already switched companies or providers because of their data policies or data sharing practices. And it's not only customers who are increasingly suspicious. Authorities are also aware of the urgency of data protection and privacy, so the regulations are getting stricter: it is no longer possible to easily use raw data even within companies.
This blogpost will discuss various techniques used to anonymize data. The following table summarizes their re-identification risks and how each method affects the value of raw data: how the statistics of each feature (column in the dataset) and the correlations between features are retained, and what the usability of such data in ML models is.
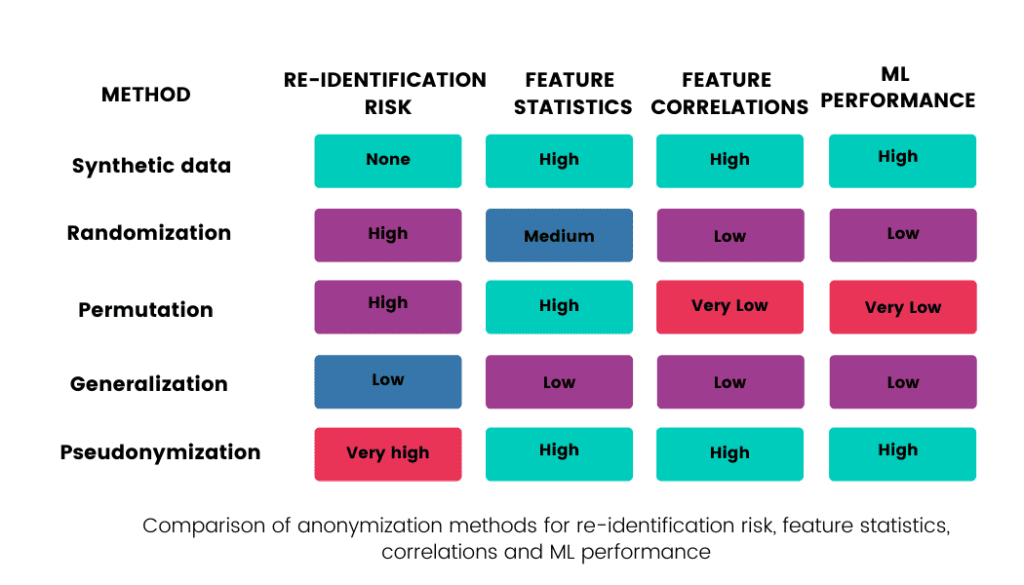
#1 Pseudonymization is not anonymization
The EU launched the GDPR (General Data Protection Regulation) in 2018, putting long-planned data protection reforms into action. GDPR's significance cannot be overstated. It was the first move towards an unified definition of privacy rights across national borders, and the trend it started has been followed worldwide since. So what does it say about privacy-respecting data usage?
First, it defines pseudonymization (also called de-identification by regulators in other countries, including the US). Based on GDPR Article 4, Recital 26: "Personal data which have undergone pseudonymisation, which could be attributed to a natural person by the use of additional information should be considered to be information on an identifiable natural person." Article 4 states very explicitly that the resulting data from pseudonymization is not anonymous but personal data. Thus, pseudonymized data must fulfill all of the same GDPR requirements that personal data has to.
Why is pseudonymization dangerous?
Imagine the following sample of four specific hospital visits, where the social security number (SSN), a typical example of Personally Identifiable Information (PII), is used as a unique personal identifier.

The pseudonymized version of this dataset still includes direct identifiers, such as the name and the social security number, but in a tokenized form:

Replacing PII with an artificial number or code and creating another table that matches this artificial number to the real social security number is an example of pseudonymization. Once both tables are accessible, sensitive personal information is easy to reverse engineer. That's why pseudonymized personal data is an easy target for a privacy attack.
How about simply removing sensitive information?
For data analysis and the development of machine learning models, the social security number is not statistically important information in the dataset, and it can be removed completely. Therefore, a typical approach to ensure individuals’ privacy is to remove all PII from the data set. But would it indeed guarantee privacy? Is this true data anonymization?
Unfortunately, the answer is a hard no. The problem comes from delineating PII from non-PII. For instance, 63% of the US population is uniquely identifiable by combining their gender, date of birth, and zip code alone. In our example, it is not difficult to identify the specific Alice Smith, age 25, who visited the hospital on 20.3.2019 and to find out that she suffered a heart attack.
These so-called indirect identifiers cannot be easily removed like the social security number as they could be important for later analysis or medical research.
So what next? Should we forget pseudonymization once and for all? No, but we must always remember that pseudonymized data is still personal data, and as such, it has to meet all data regulation requirements.
#2 Legacy data anonymization techniques destroy data
How can we share data without violating privacy? We can choose from various well-known techniques such as:
- Permutation (random permutation of data)
- Randomization (random modification of data)
- Generalization
Permutation - high risk of re-identification, low statistical performance
We could permute data and change Alice Smith for Jane Brown, waiter, age 25, who came to the hospital on that same day. However, with some additional knowledge (additional records collected by the ambulance or information from Alice's mother, who knows that her daughter Alice, age 25, was hospitalized that day), the data can be reversibly permuted back.
We can go further than this and permute data in other columns, such as the age column. Column-wise permutation's main disadvantage is the loss of all correlations, insights, and relations between columns. In our example, we can tell how many people suffer heart attacks, but it is impossible to determine those people's average age after the permutation.

Randomization - high risk of re-identification, low statistical performance
Randomization is another old data anonymization approach, where the characteristics are modified according to predefined randomized patterns. One example is perturbation, which works by adding systematic noise to data. In this case, the values can be randomly adjusted (in our example, by systematically adding or subtracting the same number of days to the date of the visit).
However, in contrast to the permutation method, some connections between the characteristics are preserved. In reality, perturbation is just a complementary measure that makes it harder for an attacker to retrieve personal data but doesn’t make it impossible. Never assume that adding noise is enough to guarantee privacy!

Generalization - low risk of re-identification, low statistical performance
Generalization is another well-known data anonymization technique that reduces the granularity of the data representation to preserve privacy. The main goal of generalization is to replace overly specific values with generic but semantically consistent values. One of the most frequently used techniques is k-anonymity.
K-anonymity prevents the singling out of individuals by coarsening potential indirect identifiers so that it is impossible to drill down to any group with fewer than (k-1) other individuals. In other words, k-anonymity preserves privacy by creating groups consisting of k records that are indistinguishable from each other, so that the probability that the person is identified based on the quasi-identifiers is not more than 1/k. In our example, k-anonymity could modify the sample in the following way:

By applying k-anonymity, we must choose a k parameter to define a balance between privacy and utility. However, even if we choose a high k value, privacy problems occur as soon as the sensitive information becomes homogeneous, i.e., groups have no diversity.
Suppose the sensitive information is the same throughout the whole group - in our example, every woman has a heart attack. In such cases, the data then becomes susceptible to so-called homogeneity attacks described in this paper. The authors also proposed a new solution, l-diversity, to protect data from these types of attacks.
Nevertheless, even l-diversity isn’t sufficient for preventing attribute disclosure. Another article introduced t-closeness - yet another anonymity criterion refining the basic idea of k-anonymity to deal with attribute disclose risk. Most importantly, all research points to the same pattern: new applications uncover new privacy drawbacks in data anonymization methods, leading to new techniques and, ultimately, new drawbacks.
The privacy-utility trade-off
No matter what criteria we end up using to prevent individuals’ re-identification, there will always be a trade-off between privacy and data value. Data that is fully anonymized so that an attacker cannot re-identify individuals is not of great value for statistical analysis.
On the other hand, if data anonymization is insufficient, the data will be vulnerable to various attacks, including linkage. Although an attacker cannot identify individuals in that particular dataset directly, data may contain quasi-identifiers that could link records to another dataset that the attacker has access to. In combination with other sources or publicly available information, it is possible to determine which individual the records in the main table belong to.
The re-identification process is much more difficult with legacy data anonymization than in the case of pseudonymization because there is no direct connection between the tables. Re-identification, in this case, involves a lot of manual searching and the evaluation of possibilities. Still, it is possible, and attackers use it with alarming regularity. As more connected data becomes available, enabled by semantic web technologies, the number of linkage attacks can increase further.
There are many publicly known linkage attacks. In 2001 anonymized records of hospital visits in Washington state were linked to individuals using state voting records. In one of the most famous works, two researchers from the University of Texas re-identified part of the anonymized Netflix movie-ranking data by linking it to non-anonymous IMDb (Internet Movie Database) users’ movie ratings. Others de-anonymized the same dataset by combining it with publicly available Amazon reviews.
We have already discussed data-sharing in the era of privacy in the context of the Netflix challenge in a previous blog post. The topic is still hot: sharing insufficiently anonymized data is getting more and more companies into trouble. Linkage attacks can have a huge impact on a company’s entire business and reputation. At the center of the data privacy scandal, a British cybersecurity company closed its analytics business putting hundreds of jobs at risk and triggering a share price slide.
The final conclusion regarding anonymization: 'anonymized' data can never be totally anonymous. We can trace back all the issues described in this blogpost to the same underlying cause. All anonymized datasets maintain a 1:1 link between each record in the data to one specific person, and these links are the very reason behind the possibility of re-identification. Moreover, the size of the dataset modified by legacy data anonymization is the same as the size of the original data.
#3 Synthetic data provides an easy way out of the dilemma
Synthetic data doesn't suffer from this limitation. Synthetic data contains completely made up but realistic information, without any link to real individuals. In contrast to other approaches, synthetic data doesn't attempt to protect privacy by merely masking or obfuscating those parts of the original dataset deemed privacy-sensitive while leaving the rest of the original dataset intact. Data synthesis is a fundamentally different approach where the source data only serves as training material for an AI algorithm, which learns its patterns and structures.
Once the AI model was trained, new statistically representative synthetic data can be generated at any time, but without the individual synthetic data records resembling any individual records of the original dataset too closely. Therefore, the size of the synthetic population is independent of the size of the source dataset. In other words, the flexibility of generating different dataset sizes implies that such a 1:1 link cannot be found.
MOSTLY AI's synthetic data platform makes this process easily accessible for anyone. The algorithm automatically builds a mathematical model based on state-of-the-art generative deep neural networks with built-in privacy mechanisms. Our synthetic data platform fits the statistical distributions of the real data and generates synthetic data by drawing randomly from the fitted model. No matter if you generate 1,000, 10,000, or 1 million records, the synthetic population will always preserve all the patterns of the real data.
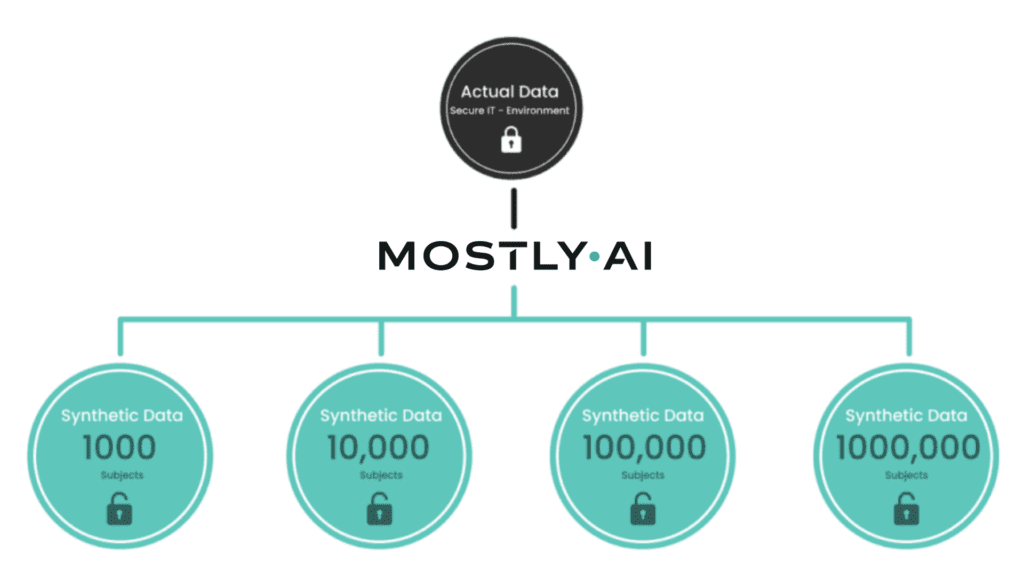
An example of AI-generated synthetic data
Let’s look at an example of the resulting statistics of MOSTLY AI’s synthetic data of the Berka dataset. This public financial dataset, released by a Czech bank in 1999, provides information on clients, accounts, and transactions. The figures below illustrate how closely synthetic data (labeled “synth” in the figures) follows the distributions of the original variables keeping the same data structure as in the target data (labeled “tgt” in the figures).
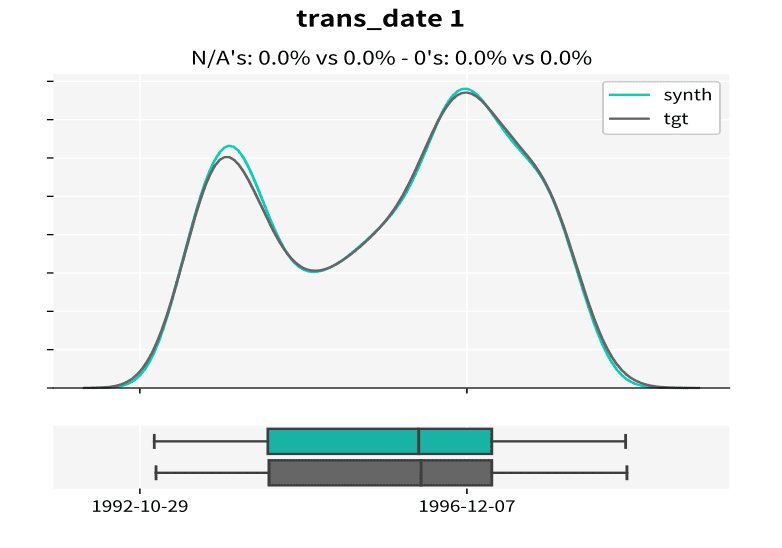
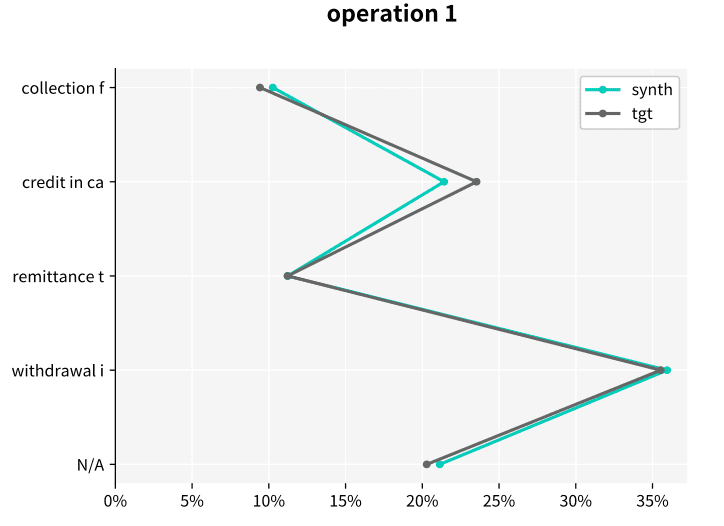
Synthetic data keeps all the variable statistics such as mean, variance or quantiles. Due to built-in privacy mechanisms, synthetic populations generated by MOSTLY AI's synthetic data platform can differ in the minimum and maximum values if they only rely on a few individuals. Keeping these values intact is incompatible with privacy, because a maximum or minimum value is a direct identifier in itself.
For example, in a payroll dataset, guaranteeing to keep the true minimum and maximum in the salary field automatically entails disclosing the salary of the highest-paid person on the payroll, who is uniquely identifiable by the mere fact that they have the highest salary in the company. In other words, the systematically occurring outliers will also be present in the synthetic population because they are of statistical significance. However, the algorithm will discard distinctive information associated only with specific users in order to ensure the privacy of individuals.
Synthetic data is as-good-as-real
The power of big data and its insights come with great responsibility. Merely employing old data anonymization techniques doesn’t ensure the privacy of an original dataset. Synthetic data is private, highly realistic, and retains all the original dataset’s statistical information.
We have illustrated the retained distribution in synthetic data using the Berka dataset, an excellent example of behavioral data in the financial domain with over 1 million transactions. Such high-dimensional personal data is extremely susceptible to privacy attacks, so proper data anonymization is of utmost importance.
Synthetic data has the power to safely and securely utilize big data assets empowering businesses to make better strategic decisions and unlock customer insights confidently. To learn more about the value of behavioral data, read our blog post series describing how MOSTLY AI's synthetic data platform can unlock behavioral data while preserving all its valuable information.
Download the Data Anonymization Guide
Get your hands on a copy of the condensed take-aways of this blogpost and upgrade your data anonymization toolkit for true privacy and compliance!
This is the second part of our blog post series on anonymous synthetic data. While Part I introduced the fundamental challenge of true anonymization, this part will detail the technical possibilities of establishing the privacy and thus safety of synthetic data.
The new era of anonymization: AI-generated synthetic copies
MOSTLY AI's synthetic data platform enables anyone to reliably extract global structure, patterns, and correlations from an existing dataset, to then generate completely new synthetic data at scale. These synthetic data points are sampled from scratch from the fitted probability distributions and thus bear no 1:1 relationship to any real, existing data subjects.
This lack of direct relationship to actual people already provides a drastically higher level of safety and renders deterministic re-identification, as discussed in Part I, impossible. However, a privacy assessment of synthetic data must not stop there but also needs to consider the most advanced attack scenarios. For one, to be assured, that customers’ privacy is not being put at any risk. And for two, to establish that a synthetic data solution indeed adheres to modern-day privacy laws. Over the past months, we have had two renowned institutions conduct thorough technical and legal assessments of MOSTLY AI's synthetic data across a broad range of attack scenarios and a broad range of datasets. And once more, it was independently established and attested by renowned experts: synthetic data by MOSTLY AI is not personal data anymore, thus adheres to all modern privacy regulations. ✅ While we go into these assessments’ details in this blog post, we are more than happy to share the full reports with you upon request.
The privacy assessment of synthetic data
Europe has recently introduced the toughest privacy law in the world, and its regulation also provides the strictest requirements for anonymization techniques. In particular, WP Article 29 has defined three criteria that need to be assessed:
- (i) is it still possible to single out an individual,
- (ii) is it still possible to link records relating to an individual, and
- (iii) can information be inferred concerning an individual?
These translate to evaluating synthetic data with respect to:
- the risk of identity disclosure: can anyone link actual individuals to synthetically generated subjects,
- the risk of membership disclosure: can anyone infer whether a subject was or was not contained in a dataset based on the derived synthetic data,
- the risk of attribute disclosure: can anyone infer additional information on a subject’s attribute if that subject was contained in the original data?
Whereas self-reported privacy metrics continue to emerge, it needs to be emphasized that these risks have to be empirically tested in order to assess the correct workings of any synthetic data algorithm as well as implementation.
Attribute disclosure
How is it possible for a third party to empirically assess the privacy of a synthetic data implementation? SBA Research, a renowned research center for information security, has been actively researching the field of attribute disclosure over the past couple of years and recently developed a sophisticated leave-one-out ML-based attribute disclosure test framework, as sketched in Figure 1. In that illustration, T depicts the original target data, that serves as training data for generating multiple synthetic datasets ST. T’ is then a so-called neighboring dataset of T that only differs with respect to T by excluding a single individual. Any additional information obtained from the synthetic datasets ST (based on T) as opposed to ST’ (based on T’) would reveal an attribute disclosure risk from including that individual. The risk of attribute disclosure can be systematically evaluated by training a multitude of machine learning models that predict a sensitive attribute based on all remaining attributes in order to then study the predictive accuracy for the excluded individual (the red-colored male depicted in Figure 1). A privacy-safe synthetic data platform, like MOSTLY AI with its in-built privacy safeguards, does not exhibit any measurable change in inference due to the inclusion or exclusion of a single individual.
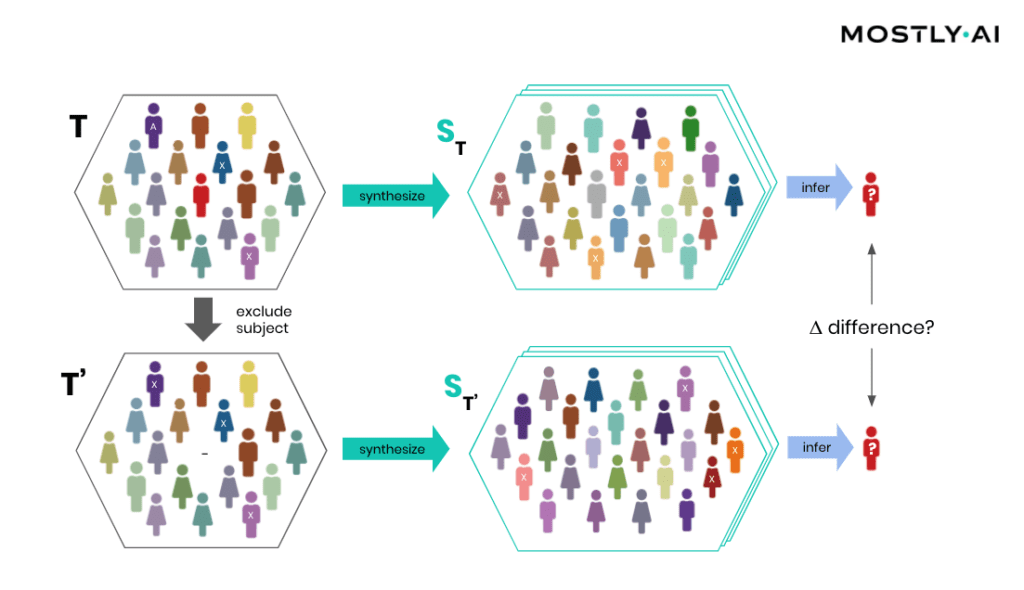
At this point, it is important to emphasize that it’s the explicit goal of a synthesizer to retain as much information as possible. And a high predictive accuracy of an ML model trained on synthetic data is testimony to its retained utility and thus value, and in itself not a risk of attribute disclosure. However, these inferences must be robust, meaning that they must not be susceptible to the influence of any single individual, no matter how much that individual conforms or does not conform to the remaining population. The bonus: any statistics, any ML model, any insights derived from MOSTLY AI’s anonymous synthetic data comes out-of-the-box with the added benefit of being robust. The following evaluation results table for the contraceptive method choice dataset from the technical assessment report further supports this argument.
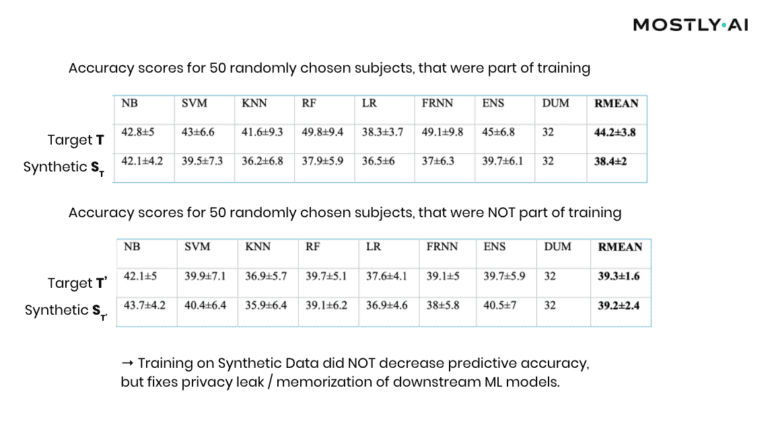
As can be seen, training standard machine learning models on actual data tends to be sensitive towards the inclusion of individual subjects (compare the accuracy of T vs. T’), which shows that the model has memorized its training data, and thus privacy has been leaked into the model parameters. On the other hand, training on MOSTLY AI’s synthetic data is NOT sensitive to individuals (compare ST with ST’). Thus, using synthetic data prevents the privacy leak / the overfitting of this broad range of ML models to actual data while remaining at the same level of predictive accuracy for holdout records.
Similarity-based privacy tests
While the previously presented framework allows for the systematic assessment of the (in)sensitivity of a synthetic data solution with respect to individual outliers, its leave-one-out approach does come with significant computational costs that make it unfortunately infeasible to be performed for each and every synthesis run. However, strong privacy tests have been developed based on the similarity of synthetic and actual data subjects, and we’ve made these an integral part of MOSTLY AI. Thus, every single time a user performs a data synthesis run, the platform conducts several fully automated tests for potential privacy leakage to help confirm the continuous valid working of the system.
Simply speaking, synthetic data shall be as close as possible, but not too close to actual data. So, accuracy and privacy, can both be understood as concepts of (dis)similarity, with the key difference being that the former is measured at an aggregate level and the latter at an individual level. But, what does it mean for a data record to be too close? How can one detect whether synthetic records are indeed statistical representations as opposed to overfitted/memorized copies of actual records? Randomly selected actual holdout records can help answer these questions by serving as a proper reference since they stem from the same target distribution but have not been seen before. Ideally, the synthetic subjects are indistinguishable from the holdout subjects, both in terms of their matching statistical properties, and their dissimilarity to the exposed training subjects. Thus, while synthetic records shall be as close as possible to the training records, they must not be any closer to them than what would be expected from the holdout records, as this would indicate that individual-level information is leaked rather than general patterns learned.
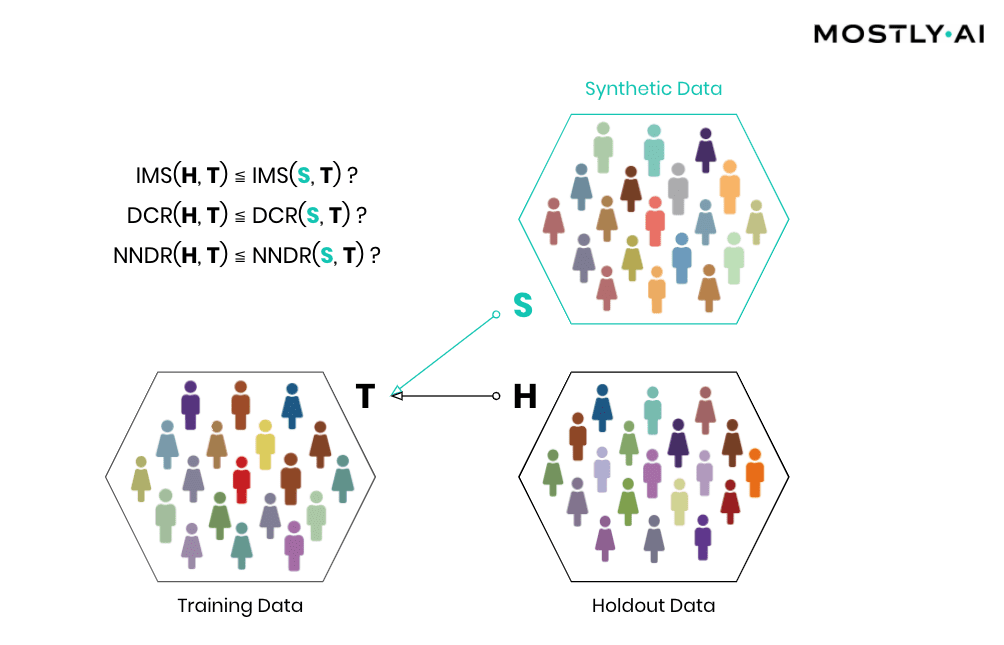
Then, how can the individual-level similarity of two datasets be quantified? A first, natural candidate is to investigate the number, respectively the share, of identical matches between these (IMS = identical match share). We thus have statistical tests automatically be performed that verify that the synthetic dataset does not have significantly more matches with the training data than what would be expected from a holdout data.
Important: the existence of identical matches within a synthetic dataset is in itself not an indicator for a privacy leak but rather needs to be assessed in the context of the dataset, as is done with our statistical tests. E.g., a dataset that exhibits identical matches within the actual data itself, shall also have a similar share of identical matches with respect to the synthetic data. Analogous to that metaphorical monkey typing the complete works of William Shakespeare by hitting random keys on a typewriter for an infinite time, any random data generator will eventually end up generating any data records, including the full medical history of yours. However, as there is no indication which of the generated data points actually exist and which not, the occurrence of such matches in a sea of data is of no use to an attacker. Yet further, these identical matches must NOT be removed from the synthetic output, as such a filter would 1) distort the resulting distributions, but more importantly 2) would actually leak privacy, as it would reveal the presence of a specific record in the training data by it being absent from a sufficiently large synthetic dataset!
But one has to go further and not only consider the dissimilarity with respect to exact matches but also with respect to the overall distribution of their distance to closest records (DCR). Just adding noise to existing data in a high-dimensional data space does not provide any protection, as has been laid out in the seminal Netflix paper on reidentification attacks (see also Part I). Taking your medical record, and changing your age by a couple of years, still leaks your sensitive information and makes that record re-identifiable, despite the overall record not being an exact match anymore. Out of an abundance of caution and to provide the strictest guarantees, one, therefore, shall demand that a synthetic record is not systematically any closer to an actual training record than what is again expected from an actual holdout record. On the other hand, if similar patterns occur within the original data across subjects, then the same (dis-)similarity shall be present also within the synthetic data. Whether the corresponding DCR distributions are significantly different can then be checked with statistical tests that compare the quantiles of the corresponding empirical distribution functions. In case the test fails, the synthetic data shall be rejected, as it is too close to actual records, and thus information on real individuals can potentially be obtained by looking for near matches within the synthetic population.
While checking for DCR is already a strong test, it comes with the caveat of measuring closeness in absolute terms. However, the distance between records can vary widely across a population, with Average Joes having small DCRs and Weird Willis (=outliers) having very large DCRs. E.g., if Weird Willi is 87 years old, has 8 kids, and is 212 cm tall, then shifting his height by a couple of centimeters will do little for his privacy. We have therefore developed an advanced measure that normalizes the distance to the closest record with respect to the overall density within a data space region, by dividing it by the distance to the 2nd closest record. This concept is known as the Nearest Neighbor Distance Ratio (NNDR) and is fortunately straightforward to compute. By checking that the NNDRs for synthetic records are not systematically any closer than expected from holdout records, one can thus provide an additional test for privacy that also protects the typically most vulnerable individuals, i.e., the outliers within a population. In any case, all tests (IMS, DCR, and NNDR) for a synthetic dataset need to pass in order to be considered anonymous.
Conclusion
We founded MOSTLY AI with the mission to foster an ethical data and AI ecosystem, with privacy-respecting synthetic data at its core. And today, we are in an excellent position to enable a rapidly growing number of leading-edge organizations to safely collaborate on top of their data for good use, to drive data agility as well as customer understanding, and to do so at scale. All while ensuring core values and fundamental rights of individuals remain fully protected.
Anonymization is hard - synthetic data is the solution. MOSTLY AI's synthetic data platform is the world’s most accurate and most secure offering in this space. So, reach out to us and learn more about how your organizations can reap the benefits of their data assets, while knowing that their customers’ trust is not put at any risk.
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
The very first question commonly asked with respect to Synthetic Data is: how accurate is it? Seeing, then, the unparalleled accuracy of MOSTLY AI's synthetic data platform in action, resulting in synthetic data that is near indistinguishable from real data, typically triggers the second, just as important question: is it really private? In this blog post series we will dive into the topic of privacy preservation, both from a legal as well as a technical perspective, and explain how external assessors unequivocally come to the same conclusion: MOSTLY AI generates truly anonymous synthetic data, and thus any further processing, sharing or monetization becomes instantly compliant with even the toughest privacy regulations being put in place these days.
What is anonymous data? A historical perspective
So, what does it mean for a dataset to be considered private in the first place? A common misconception is that any dataset that has its uniquely identifying attributes removed is thereby made anonymous. However, the absence of these so-called “direct identifiers”, like the full names, the e-mail addresses, the social security numbers, etc., within a dataset provides hardly any safety at all. The simple composition of multiple attributes taken together is unique and thus allows for the re-identification of individual subjects. Such attributes that are not direct identifiers by themselves, but only in combination, are thus termed quasi-identifiers. Just how easy this re-identification is, and how few attributes are actually required, came as a surprise to a broader audience when Latanya Sweeney published her seminal paper entitled “Simple Demographics Often Identify People Uniquely” in the year 2000. In particular, because her research was preceded by the successful re-identification of publicly available highly sensitive medical records, that were supposedly anonymous. Notably, the simple fact that zip code, date-of-birth, and gender in combination are unique to 87% of the US population, served as an eye-opener for policy-makers and researchers alike. And as a direct result of Sweeney’s groundbreaking work, privacy regulations were adapted to provide extra safety. For instance, the HIPAA privacy rule that covers the handling of health records in the US was passed in 2003, and explicitly lists a vast number of attributes (incl. any dates), that are all to be removed to provide safety (see footnote 15 here). Spurred by the discovery of these risks in methods then considered state-of-the-art anonymization, researchers continued their quest for improved de-identification methods and privacy guarantees, based on the concept of quasi-identifiers and sensitive attributes.
However, the approach ultimately had to hit a dead end, because any seemingly innocuous piece of information, that is related to an individual subject, is potentially sensitive, as well as serves as a quasi-identifier. And with more and more data points being collected, there is no escape from adversaries combining all of these with ease to single out individuals, even in large-scale datasets. The futility of this endeavor becomes even more striking once you realize that it’s a hard mathematical law that one attempts to compete with: the so-called curse of dimensionality. The number of possible outcomes grows exponentially with the number of data points per subject, and even for modestly sized databases quickly surpasses the number of atoms in the universe. Thus, with a continuously growing number of data points collected, any individual in any database is increasingly distinctive from all others and therefore becomes susceptible to de-anonymization.
The consequence? Modern-day privacy regulations (GDPR, CCPA, etc.) provide stricter definitions of anonymity. They consider data to be anonymous if and only if none of the subjects are re-identifiable, neither directly nor indirectly, neither by the data controller nor by any third party (see GDPR §4.1). They do soften the definition, requiring that the re-identification attack needs to be reasonably likely to be performed (see GDPR Recital 26 or CCPA 1798.140(o)). However, these clauses clearly do NOT exempt from considering the most basic and thus reasonable form, the so-called linkage attacks, that simply require 3rd party data to be joined for a successful de-anonymization. And it was simple linkage attacks, that lead to the re-identification of Netflix users, the re-identification of NY taxi trips, the re-identification of telco location data, the re-identification of credit card transactions, the re-identification of browsing data, the re-identification of health care records, and so forth.
A 2019 Nature paper thus had to conclude:
“[..] even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR and seriously challenge the technical and legal adequacy of the de-identification release-and-forget model.”
Gartner projects that by 2023, 65% of the world’s population will have its personal information covered under modern privacy regulations, up from 10% today with the European GDPR regulation becoming the de-facto global standard.
True anonymization today is almost impossible with old tools

And while thousands, rather millions of bits are being collected about each one of us on a continuous basis, only 33 bits of information turn out to be sufficient to re-identify each individual among a global population of nearly 8 billion people. This gap between how much data is captured and how much information can be at most retained is widening by the day, making it an ever-more pressing concern for any organization dealing with privacy-sensitive data.
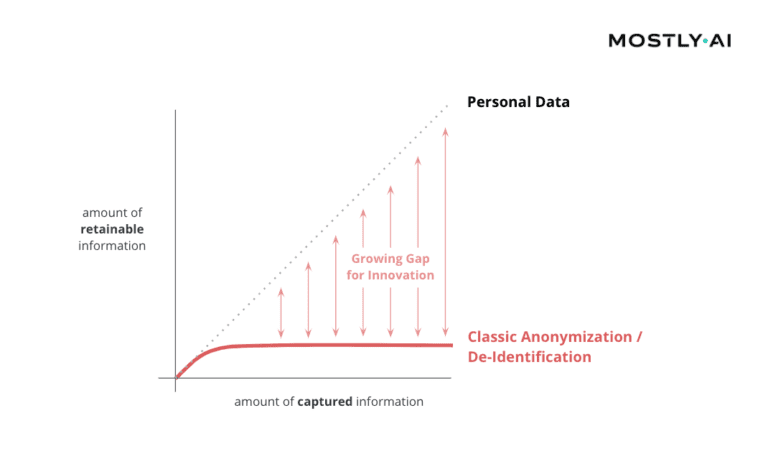
In particular, as this limitation is true for any of the existing techniques, and for any real-world customer data asset, as has already been conjectured in the seminal 2008 paper on de-anonymizing basic Netflix ratings:
“[..] the amount of perturbation that must be applied to the data to defeat our algorithm will completely destroy their utility [..] Sanitization techniques from the k-anonymity literature such as generalization and suppression do not provide meaningful privacy guarantees, and in any case fail on high-dimensional data.”
So, true anonymization is hard. Is this the end of privacy? No! But we will need to move beyond mere de-identification. Enter synthetic data. Truly anonymous synthetic data.
Head over to Part II of our blog post series to dive deeper into the privacy of synthetic data, and how it can be assessed.
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
What is AI-generated synthetic data?
MOSTLY AI’s synthetic data platform is based on a groundbreaking machine learning technology, ready to create privacy regulation compliant, highly accurate synthetic versions of datasets. The synthetic data versions generated by MOSTLY AI retain up to 99% of the information contained in the original, yet real individuals are impossible to re-identify. The implications for the financial industry and the ways in which this technology can be applied are manifold.
Large financial institutions and banks have always been among the most conservative users of technology and for a good reason. Nowhere else is data so rich and so risky, so full of hidden stories and telltale patterns. What makes these oceans of information so valuable is precisely what makes them so sensitive. And customers are well aware of this. 87% of Americans consider credit card data moderately or extremely private, whereas only 68% consider health and genetic information private. In other words, people are shyer about their wallets than their medical secrets.
Considering this sentiment, it is not surprising that financial businesses guard their customers’ data very carefully. Customers demand and reward this scrutiny. With the advance of data-driven services, personal relationships are no longer the main driver of trust. Instead, one of the biggest drivers of loyalty for banking customers is the ability to trust their bank in protecting their personal data.
The great banking dilemma: innovation versus data-privacy
Source: Raconteur, The World of Fintech
Customers in the financial world are hungry for cutting edge innovations. Data is the fuel required by technologies to make these advances. New disrupting fintech players have been making these innovations happen with Revolut, Monzo, Transferwise and others picking the low hanging fruits left untouched by traditional institutions. So far, the great data gateways at banks and large financial organizations have been closed and heavily guarded for security reasons.
While security remains a high priority, it is now possible to open those gateways without jeopardizing safety by letting synthetic copies of your valuable data assets do its magic for the financial industry. MOSTLY AI's enterprise-grade synthetic data platform is changing the game by offering a safe, trustworthy and compromise-free solution for using previously untapped data assets, bridging the gap between technological ambitions and real-world possibilities.
How does AI-generated synthetic data work and why is it superior to data masking?
By creating synthetic copies from your valuable data assets, such as credit card transaction records, client identity repositories, purchase records of financial products or high value investment portfolios, you can unlock rich and as yet untouched stories of human behavior, while also preserving their complexity. For example, when it comes to spending money, shopping behavior is surprisingly easy to predict by training machine learning algorithms on credit card data.
Researchers of this study used anonymized datasets. There are different approaches to traditional anonymization, but they have one thing in common: a lot of valuable data gets thrown away to prevent re-identification of customers. With synthetic data, these algorithms can account for much broader and deeper insights, while anonymization methods come with serious limitations, very often rendering datasets effectively useless.
No matter how thorough the process to remove sensitive bits of data was, it is still shockingly easy to re-identify datasets anonymized with traditional techniques. MOSTLY AI’s synthetic data platform satisfies two seemingly opposing needs: it provides a true reflection of real life data, yet is impossible to re-identify - hence the revolutionary nature of this technology. The potentials are huge. There are just so many stories hidden in behavioral datasets ready to be discovered with the right tools. Customer behavior can be used to value companies, to predict credit risk, to build data-driven services and to guide marketing efforts, just to mention a few examples of how magical machine learning algorithms can be when fed with good quality datasets of financial behavior.
So what are the most important ways in which financial organizations can benefit from using synthetic data in 2020?
#1 Make the most of AI and cloud computing technologies
Machine learning algorithms are hungry beasts when it comes to data and computing power. Banks and financial institutions often miss out on these innovative technologies, because uploading sensitive data to cloud platforms is just out of the question for privacy reasons. A synthetic version of a sensitive dataset can stand in for the purpose of training algorithms, which - once trained - can be brought back to the premises and used on the original data.
In addition, synthetic data can improve the performance of machine learning algorithms by as much as 15% by providing significantly more samples than otherwise available in the original data and by upsampling minority classes that would otherwise remain underrepresented.
In other cases, existing datasets are simply too small to be used for modelling purposes. Recessions for example are too rare to study without putting the data on synthetic steroids. Similarly, credit risk assessment models usually need to be tested against extreme events, such as surprise election outcomes, like the Brexit referendum or the 2016 US presidential election, where polls failed to predict results. These extreme events lack enough data points and AI-generated synthetic data can fill in this gap to improve the training of crucial models, such those applied to predict credit risk by conducting more thorough stress-testing.
MOSTLY AI' synthetic data platform can scale up existing data and build more robust datasets out of all rare events, like in the early days of a product launch or in case of a rarely purchased, but high value service. Similarly, high quality AI-generated data provides excellent input for the initial training of robo-advisor programs before launching fully automated financial adviser platforms.
#2 Create products and services that genuinely meet customer needs
And not just in-house either. Synthetic data benefits product and service development as it brings meaningful insights into the design process. Safely sharing the synthetic version of datasets with innovation partners, third party service providers and researchers also becomes possible, opening up new spaces of cooperation and co-creation. Networks of interconnected services and products are the future of banking and synthetic data will play an important role in setting up these complex ecosystems.
During API development and testing, it’s crucial to provide quality sandbox environments for developers, complete with realistic data, so by the time a service goes live, apps developed by third parties are prepared for all types of consumer behavior. Synthetic data help engineers ensure that their software works in various planned and unplanned scenarios, significantly reducing product downtimes after a launch. Synthetic test data is easy to create and provides a realistic and privacy-compliant drop-in placement for production data.
#3 Share banking data with third parties in a safe way
Synthetic data makes safe, no-risk monetization of data possible. Although third-party data sharing is the biggest challenge for historically cautious financial players, it is now a real possibility and it will soon be the backbone of financial services. Whether it’s raw data through an API or in the form of synthetic datasets, this future is here and institutions need to step up their game or risk losing out to disruptors. These new players are ready to take the leap. NGOs and other charities working on improving the lives of particular at-risk groups or society at large could also benefit from access to synthetic financial datasets. Such cooperations could earn banks and financial institutions a huge amount of publicity and scientific credit at research communities. Using synthetic data sandboxes for POC processes can speed up processes and save huge amounts on data provisioning costs.
#4 Improve fraud detection processes
Detecting fraud doesn’t have to be a costly and tedious manual process - there is no need to look at specific transactions to train algorithms, only patterns to see if the amounts justify an audit or are perfectly in line with what’s expected. Synthetic data can do this with high accuracy in a quick and painless way by generating unique and rare fraud patterns that your automation can use for fraud detection.
However, the advantages don’t end there. Fraud detection datasets are usually highly imbalanced and so traditional machine learning often are challenged. MOSTLY AI is also able to fix class imbalances engraved in an original dataset and thus help downstream models to perform better.
Synthetic data can boost the performance of fraud detection and AML models, leading to a more accurate detection of positive cases.
#5 Make life easier for yourself and your organization
The lengthy and often overly complicated legalities of sharing data can make such efforts virtually impossible, even when the data lake’s access privileges only have to be granted to another department in your organization. A familiar and painful situation for those working in large institutions: by the time the permission arrives, the business need is not met in time. To speed up and simplify data-driven operations, the use of synthetic data can do wonders, doing away with the need to get the blessings of the legal department and providing access to datasets for any number of colleagues, even across borders or within tight budget constraints and deadlines. Since it doesn't classify as personal data, synthetic data can be shared across international borders even after the landmark ruling of Schrems II.
The takeaway: AI-generated synthetic data is a must-have in finance
In summary, AI-powered synthetic data is a privacy-preserving way for financial institutions to use advanced machine learning services and algorithms, to develop data-driven products, such as robo-advisors, to monetize their data reserves, to improve fraud detection, to fix historically biased datasets and to simplify data sharing in-house, with partners and third parties. Simply put, it’s a must-have technology for financial power houses, whose very existence rests on and will increasingly be governed by the data economy. GDPR/CCPA compliant behavioral data is an asset, which needs to be actively cultivated and harvested for the benefit of customers and institutions alike. Find out more about synthetic data use cases in finance!
Feature image by tuetyi.com
Learn how innovators outrun competitors in banking!
Accelerating digital transformation has been at the top of the agenda for financial institutions. Download our ebook to find out how AI-generated synthetic data can give your organization a competitive edge.
Don't break things
In the first part of this PrivacyTech in Banking series, I looked into the effect that privacy has on data-driven innovation in the financial services industry. Moving fast and breaking things is extremely bad advice when it comes to privacy. The main reason why privacy turns out to be a killer of your data-driven innovation project lies in the fact that privacy is closely related to trust - the most valuable asset a financial institution has (to lose). But privacy protection stays tricky even if the banks don’t try to cut corners.
In this blog post, I would like to look into the seemingly magical solution to all privacy problems: anonymization - and its evil twin pseudonymization. But first things first, let’s talk about anonymization.
Let’s talk about Anonymization
GDPR defines anonymous information as “…information which does not relate to an identified or identifiable natural person or [as] personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable”. Hence if there is no way to (re-)identify the customer, the information is anonymous and isn’t beholden to privacy regulations anymore. From a privacy perspective, anonymous data is free to use, share, and monetize. Problem solved. Right? Well, not quite.
Only a little bit re-identifiable
When we talk about anonymization we need to distinguish between anonymous data, as described in the previous paragraph, and the classical anonymization techniques which are used to make private data less personal but maintain the semantics and syntax.
Some widely known classical anonymization methods include randomization, noise injection, tokenization, suppression, shuffling, generalization, etc. Normally multiple anonymization techniques are combined into a more or less standardized anonymization design process that results in less personal data.
One of the biggest general misconceptions about anonymization today is that anonymized data is equal to anonymous data. Anonymity is a binary class. Data is either anonymous or it isn’t. If the data subject can be re-identified - with more or less effort - no matter how sophisticated your anonymization process is - then that data ISN’T anonymous. And guess what, the majority of anonymized data isn’t anonymous.
Have I just revealed something novel? Actually no, the truth about anonymization has been here for a while, it’s just not evenly distributed. More and more anonymization practitioners are getting vocal about the fact that calling less personal data ‘anonymous’ creates a false sense of security that gives people tacit permission to share data without worrying about privacy.
Understanding the Privacy-Utility Trade-off
So how big is the utility gap between “less personal data” (or data that was anonymized through classical anonymization) and truly anonymous data?
Most of the classical anonymization techniques in use today cannot produce truly anonymous data. Instead, they are making data less personal - all while trying to retain as much data utility as possible. The more information that gets masked or obfuscated, the weaker insights of the datasets and vice versa. This is the so-called privacy-utility trade-off.

In the era of big data, however, anonymization is getting much more difficult and large-scale datasets - with often hundreds or thousands of attributes - uncover the shortcomings of classical anonymization methods. Today the “privacy - utility trade-off” has reached the paradox state where the entire utility of a dataset can be destroyed (making it completely useless for the intended application scenario) and still, the data won’t be anonymous (see below).

Looking for trouble with anonymized (but not anonymous) data
In the next section of this blog post, I would like to look deeper into two big problems anonymization is facing when it comes to re-identification of data subjects:
- Problem #1 can be described as “I still don’t know who you are, but I can definitely identify you as a unique data subject in the dataset”
- Problem #2 is sitting on top of problem #1 and is putting the final nail into the coffin of classical anonymization techniques. It can be described as “If I link your anonymized data with additional data, all it takes is one matching record to definitely identify you and all of your data in the anonymized dataset”
Let’s look a bit more in-depth into both problems and put them into a banking perspective.
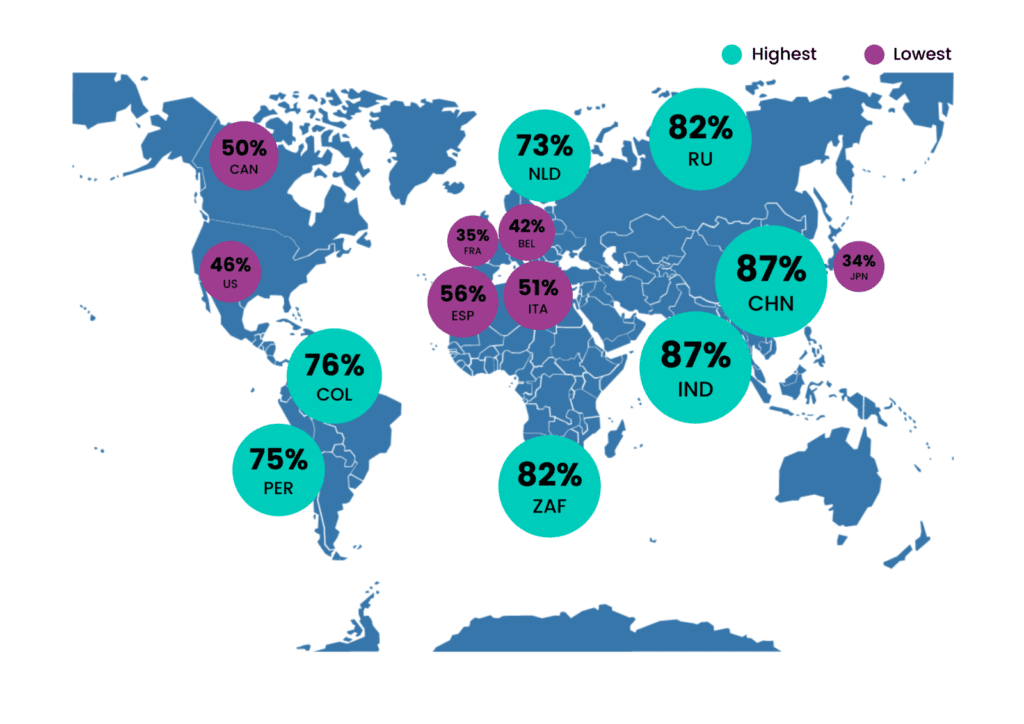
Problem #1: A few data points is all it takes to make an individual unique
We all are more special than we think we are. The richness and high granularity of our (recorded) behavior are what make us so unique. Big data is a blessing when it comes to understanding and anticipating customer behavior (utility) but it’s a curse when it comes to anonymization (privacy).
Researchers could prove that 80% of total customers could be re-identified by only 3 random credit card transactions when only the merchant and the date of the transaction were revealed. Recently, I personally participated in a project where a big bank tried to reproduce these findings. The bank was surprised to find that 70% of their customers could be re-identified by only 2 random payment card transactions.
Consider, neither merchant nor date of transaction are considered PII attributes. And still, these unique behavioral traces can be used as a fingerprint to definitely identify someone. These so-called indirect identifiers are deeply interwoven with customer data and can’t be easily removed.
Problem #2: Sometimes all it takes is a single data point
The process of keeping anonymized data separate from any additional customer information is already very difficult for a single organization. Privacy sensitive data is queried daily across different business units and is stored and used in different contexts. One matching record of two queries is all it takes to re-identify a customer.
This problem grows even bigger if we look at how the data flows between different legal entities that share a relationship with the same customer. As this blog post series is focusing on the banking industry let’s take the example of the payment card process and the famous 4-corner model to demonstrate the multi-party anonymization challenge.
At the moment when the customer makes the purchase with the payment card, the privacy-sensitive data is moved and processed by many different legal entities: acquirer, merchant, card issuer, card scheme, payment facilitators, etc. Many of the aforementioned stakeholders collect and store the record of the same payment transaction and would be able to easily re-identify a customer if they would get an anonymized dataset of another party in their hands. Sharing anonymized data outside of the organization means looking for trouble.
How not to monetize financial data
Talking about trouble, let’s look into an example of what happens when a company shares not-as-anonymous-as-expected financial data with third parties. Selling credit card data is a big business across the world, especially in the United States. This February an internal document of the largest financial data broker in the US leaked to the public acknowledging that the consumer payment data could be unmasked, respectively re-identified.
The leaked document revealed what type of data the financial data broker shares with its business customers, how the data is managed across its infrastructure, and the specific anonymization techniques used to protect the privacy of the payment cardholders. To cut the story short - the shared data was not at all anonymous - it was only pseudonymized. But what is pseudonymization after all and why do I refer to it as the anonymization’s evil twin?
Pseudonymization ≠ Anonymization
According to GDPR pseudonymization stands for “the processing of personal data in such a way that the data can no longer be attributed to a specific data subject without the use of additional information.” GDPR also states that“…data which have undergone pseudonymization, which could be attributed to a natural person by the use of additional information, should be considered to be information on an identifiable natural person.” Therefore pseudonymized data are considered to be personal data and must comply with the GDPR.
During the pseudonymization, all personally identifiable information (PII) like name, address, or social security number is identified and either removed, masked, or replaced with other values. The rest of the data (not direct PII) stays the same. This means that pseudonymized data still contain parts of identifiable information hidden in the non-PII attributes. This is also the reason why GDPR considers pseudonymization to be only a data protection technique and it is not considered to be a part of anonymization techniques.
Bullshit Anonymization
Using pseudonymization as a synonym to anonymization is wrong and it makes an already complicated situation only worse but it happens all the time within the banking industry. Re-identifying customers from data that has been anonymized by classical anonymization techniques is getting easier and easier - but re-identifying customers from pseudonymized data is child’s play. Remember the story about the financial data broker from above who was selling pseudonymized data?
The opinions of two academic researchers interviewed in the original news article commenting on the level of anonymization are spot on. The less diplomatic one reads “This is bullshit 'anonymization'” and the moderate one states “the data in itself seems to me to only be pseudonymized”. Now add one and one together and ask yourself how many poorly anonymized or only pseudonymized datasets are circulating within your organization at this very moment?
When classical anonymization techniques and pseudonymization fail
Faced with huge legal and reputational risks and aware that classical privacy methods fail to guarantee privacy protection, banks are extremely reluctant to use, share, and monetize customer data. Zero-Trust policies are replacing castle-and-moat approaches. Each access to customer data has to be previously mapped and restricted to the bare minimum.
Access to customer data gets scarce and only reserved for a few vetted data scientists and data engineers. This leads to bottlenecks and prevents or impedes many important activities within the bank: data-driven innovation, product development, and testing with as-production-like-as-possible data, startup co-operations, as well as the easy setup of sandboxes for open banking. Data Security and Data Privacy Officers become the inhibitors of the progress and take the blame for the insufficiencies of classical privacy methods.
Is this the harsh reality banks have to get used to? Are there privacy methods at sight that could change the current paradigm that privacy protection always comes at the cost of data utility? Can we keep the Zero-Trust policies in place while at the same time creating innovation sandboxes for internal teams and partner networks to create value from high-quality anonymous data? In my next blog post, I will answer these questions and look into a new privacy method that lets you have the cake and eat it too. Stay tuned.
Last Thursday the European Court of Justice published their verdict on the so-called Schrems II case: See the full ECJ Press Release or The Guardian for a summary. In essence, the ECJ invalidated with immediate effect the EU-US Privacy Shield and clarified the obligations for companies relying on Standard Contractual Clauses (SCC) for cross-border data sharing. This verdict, the culmination of a year-long legal battle between data privacy advocates, national data protection authorities, and Facebook, came to many observers as a surprise. In particular, as the Privacy Shield has been established as a response to yet another ECJ ruling made in 2015, that already recognized the danger of US surveillance for EU citizens (see here for a timeline of events). However, the ECJ makes the case that the Privacy Shield is not effective in protecting the personal data of European citizens, a recognized fundamental right, in particular with respect to (known or unknown) data requests by US intelligence agencies, like the NSA.
Let’s take a step back: Personal data is protected within the EU based on the General Data Protection Regulation (GDPR) and other previous regulations (e.g. Charter of Fundamental Rights). With this unified regulation, it is relatively easy to move personal data across borders within the European Union. However, data transfer to a third country, in principle, may only take place if the third country in question ensures an adequate level of data protection. The data exporter needs to ensure that this adequate level of data protection is given. Because this is difficult and cumbersome to do on an individual basis, the data transfer to the US has been granted a particular exemption via the EU-US Privacy Shield in 2016. It is this exemption that has now been recognized as being invalid from its beginning.
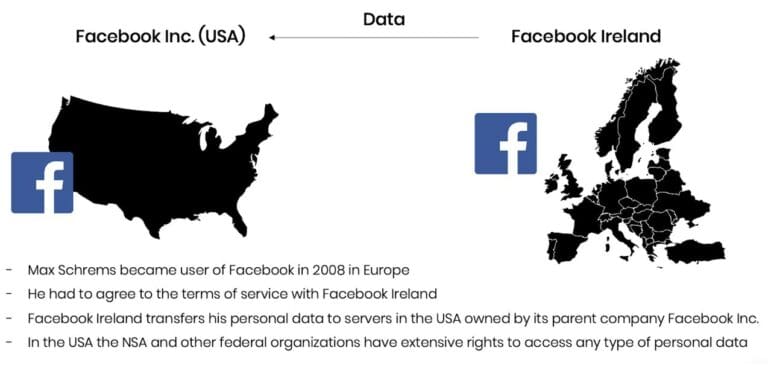
Max Schrems, privacy advocate and party in the case, expressed relief and satisfaction in a first reaction to this verdict. The non-profit organization NOYB, which he founded, shared their view on the ruling in their first reaction. In particular, the clear call to action towards national Data Protection Authorities was highly welcomed, as the GDPR relies on these in order to be truly effective. Several privacy law firms followed suit over the last couple of days and published their perspectives. E.g., Taylor Wessing also emphasizes that while standard contract clauses remain valid, they are not to be seen as a "panacea”. The obligations to assess the legality of a cross-border data transfer remain with the data exporter and data importer and need to be studied on a case-by-case basis, which typically incurs significant costs, time, as well as legal risks. As it has been shown by the ECJ verdict itself, even the European Commission was proven to be wrong in terms of their judgment when negotiating the Privacy Shield in the first place.
Bottom line is that this ruling will make it even more difficult for organizations to legally share any personal data of EU citizens from the EU to the US, as well as to other third countries. This impacts the sharing of customer data just as well as employee’s data for multinational organizations. And this ruling comes on top of a global trend towards tighter data sovereignty and data localization laws taking effect (see here).
All that being said, it is important to remember that none of this applies to non-personal data. While most existing anonymization techniques need to destroy vast amounts of information in order to prevent re-identification, it is the unique value proposition of synthetic data that finally allows for information to flow freely at granular level as needed, without infringing individuals’ fundamental right for privacy. Rather than sharing the original, privacy-sensitive data, organizations can thus share statistically representative data and circumvent the restrictions on personal data.
Our economy increasingly depends on the free flow of information. It’s broadly recognized, and yet, at the same time, the need for strong privacy is more important than ever before. Synthetic data is a solution that offers a viable way out of this dilemma.
Looking back at data-driven Innovation in Banking
Looking back at my years at a retail bank that involved developing new digital offerings, I often remember hearing the proverb “You can’t have your cake and eat it too.” Trade-offs are an integral part of innovation in a heavily regulated and risk-averse environment like banking.
Normally, you start with a really exciting idea. This later gets watered down by a series of trade-offs (security and legal requirements, infrastructure limitations, etc.) which then results in a super-secure and compliant outcome that fits perfectly into a bank’s infrastructure. But the offering itself is often “dead on arrival”. Hence, a large part of my job at that time consisted of applying lateral thinking methods: finding ways around the internal limitations in order to keep innovations alive.
Some of my most exciting projects back then were data monetization projects. We were asking ourselves how could our bank unlock the untapped utility hidden in credit and debit transactional data and transform it into added value for our private and corporate customers. The sky seemed to be the limit. But very soon we realized that the biggest limiting factor was much closer to earth. In fact, it was as close as the office of our bank’s data protection officer.
Innovation vs. Privacy
As you could imagine, a customer's data is subject to quite stringent data protection legislation. I’ll use GDPR as the most popular data protection regulation to explain the major challenges of data-driven innovation in banking, but using other regulations wouldn’t make a big difference to my arguments. Let’s look at three major privacy-related stumbling blocks that you have to get around if you want to succeed with your data-based innovation:
a. Legal basis
Everything starts with a legal basis for processing customer data. Most data-driven innovations require a previous customer’s consent. In addition to explicit consent, there are some other legitimate reasons for data processing, such as the “need to process the data in order to comply with a legal obligation”. But don’t expect that your idea will fall into one of those categories. Getting customer consent for data processing is a herculean challenge on its own. It’s essential to make sure that customer consent was given freely, specific to the data usage intent, informed, unambiguous, and able to be revoked at any time. Even the best marketing campaigns won’t get you more than 15-20% approval for your new service from your target group. Many predictive applications require a critical mass of data subjects, whose data are feeding the algorithms. Therefore ask yourself early whether you will be able to get a sufficient number of customers to consent.
b. Security and Confidentiality
With the legal basis fulfilled, a step not many ideas overcome, the next challenge awaits you: secure processing. The processing itself must guarantee appropriate security and confidentiality of the personal data. This is usually a mix of different security measures of data protection involving data access management over encryption to data anonymization – the seemingly magical solution that transforms personal data into non-personal, free to use data, as it falls outside GDPR’s scope.
These security and protection measures are a necessity for all phases of product development that require customer data. Data has to be protected throughout the product life cycle with permanently changing product features, product-related infrastructure and up/downstream applications. A compelling argument for privacy and data security “by design”, as building strong privacy and security processes into your new data-driven product right from the very beginning allows keeping the effort to a minimum – even in a constantly changing environment.
c. Public perception
However, having a legal basis for data processing and even privacy and data security by design doesn’t offer absolute protection against a public outrage. If your new product or service is perceived as unethical, manipulative, reinforcing biases and disbalances the power between the bank and its customers it will not take much to fail upon arrival. Mark Zuckerberg famously said in 2004: “You can be unethical and still be legal; that’s the way I live my life.” This type of thinking might be an option for a company like Facebook but it is definitely not an alternative for a bank that needs to be trusted by its customers
Sometimes it’s not even the question of ethics. One inept communication can destroy the trust you spent years building. Letting public imagination run wild with privacy related topics can end in a disaster like what happened with this Dutch bank in 2014. Faced with public outrage, the bank had to refrain from its initial intention to use customers’ spending habits for targeted ads.
Required by law or not, be transparent, ethical, and aware that more and more of your customers are becoming data and privacy literate. Are the short term gains of an insight worth the collective trust of your customers? Don’t forget that data privacy is a very sensitive topic that requires extremely clear communication and an in-depth ethical review.
No lateral thinking will get you around privacy and data security requirements. Any mistake in the privacy design of your data-driven innovation could lead to a violation of data privacy legislation or, even worse, put your bank's most valuable asset at risk: customer trust.
Should you just give up being innovative?
There’s no “fail fast” in data privacy matters. There are so many moving parts, so many juggling balls to keep in the air concerning privacy and data security topics that at this point, most of the innovators within the bank will simply give up. Under those circumstances, you often have to choose between data-driven innovation and data privacy. You can’t have your cake and eat it too. Or can you?
More and more organizations are starting to understand that there is significant commercial value behind the ability to protect customer privacy. Because only customer data that can be used, shared, and monetized in a privacy-compliant way is commercially valuable data. Over the last few years, I’ve observed an entirely new market quietly developing with the goal of achieving the state-of-the-art privacy protection modern data-driven organizations require to operate and innovate with their customer data.
New Privacy Approaches enable Innovation
The three most promising new privacy approaches in this market are differential privacy, homomorphic encryption and AI-generated synthetic data.
Differential privacy is an abstract mathematical framework for privacy to find the maximum influence any single person can have on a given database query, algorithm, or any other statistical method to quantify privacy risk for individuals in the data set. In recent years applications of differential privacy have been used by tech giants like Google and Apple to run analytics on private data. Those applications faced some criticism from the privacy research community because they don’t reveal how they calculate differential privacy and some researchers argue that companies like Apple even sacrifice some privacy in order to increase data utility.
Homomorphic encryption is a class of encryption methods that enable computing on data while the data is encrypted. The data stays encrypted during the entire process of processing. The secret key doesn’t have to be shared with the entity that processes the data. The output of processing remains encrypted and can only be revealed by the owner of the secret key.
One of the most fascinating technologies in the PrivacyTech market is AI-generated synthetic data. It is artificially generated data that is based on a given real-world dataset. But even though synthetic data accurately resembles its real counterpart and its statistical properties, it does not include any customer’s actual information. Thus it is fully anonymous and exempt from GDPR.
To sum it up, these three new privacy protection techniques finally allow banks to leverage the utility hidden in customer data while at the same time providing the highest level of privacy protection. Privacy protection can’t be used as an excuse to not innovate with data anymore. Innovations in privacy protection are the key to fixing data-driven innovation.
This was the first part of a mini-series on PrivacyTech in banking. But before diving deeper into new privacy protection techniques and especially my favorite – synthetic data, in the next part, I will explore the shortcomings of various anonymization techniques frequently used at banks and the consequences involved. Your anonymized customer data isn’t as anonymous as you might think it is. Stay tuned...
We are facing an unprecedented crisis that has changed our daily life in several ways and that spans virtually all aspects of society. The coronavirus disease 2019 (COVID-19) outbreak, caused by a new strain of coronavirus, had its first infection in humans in late 2019. In the meantime, it has spread to 6 continents and affected over 5 million people worldwide. This gave rise to new challenges, both to our political leaders and ourselves and the social, economic, and political ramifications of this crisis are still to be fully appreciated.
On the other hand, innovation often emerges in response to extreme needs, and there are previous examples of societal crisis-induced shifts. The Black Death, in the 14th century, may have shifted the future of Europe by ending feudalism and starting the foundations of the Renaissance movement. World War II not only led to the increased participation of women in the labor force but also triggered technological innovations such as the jet engine, computers, the radar, and penicillin. In times like this, collective shifts in social attitudes were eventually transformed into policy shifts, with long-lasting effects in society.
To the extent that we can envision a positive aspect arising from the current pandemic, without forgetting the many lives lost, is that this may again be a time of opportunity and innovation. Indeed, different industries are already adjusting to the current needs and jumping in to help. From beermakers and distilleries that shifted production to hand sanitizers, to engineering companies and universities which developed and made new parts freely available, or even open-source ventilators – everyone is trying to do their part.
COVID-19 and the Global Big Data Problem
Over the last years, we have been gathering data in unprecedented amounts and speed. Since the start of the pandemic, this has been intensified. Relevant authorities are rushing to gather data on disease symptoms, virus tracking (affected people), availability of healthcare resources, among others, in an attempt to understand the outbreak and eventually control it. But there are two valuable tools that will guide our knowledge of the scale of the outbreak – testing and tracing. Testing is crucial for quickly identifying new cases, understanding how prevalent the disease is, and how it is evolving. Tracing, on the other hand, can give us contact networks. It can help to stop new cases by warning individuals of potential contact with infected people. This may be especially important in tracking the second wave and during the deconfinement.
Data has thus become the main resource to guide our collective survival strategy. At this stage, Big Data, machine learning, and artificial intelligence (AI) have the potential to make a difference by guiding political leaders and healthcare providers in the fight against the pandemic. Tech companies that used to profit from these technologies, are rallying to help governments and healthcare organizations cope with the situation. Previously unusual partnerships are already forming more frequently and more rapidly, namely between governmental or academic departments and private companies. Google and Apple, traditional competitors, have joined forces to create an API that would facilitate each countries’ tracing apps to work on both operating systems, and it is compliant with stricter privacy restrictions.
However, extracting useful knowledge from the data being collected will require a collaborative effort. In addition to the big data problem, we will need to form teams whose expertise span different areas. Within healthcare, academia, and industry, people are used to working in their own fields. However, this is an interdisciplinary problem, and expertise from computation and AI, as well as biomedical sciences, epidemiology, and demographic modeling will need to be merged to find effective solutions. Facebook’s Data for Good program has created and made available data maps and distribution of infected individuals and the density of at-risk populations. Public health researchers have used this information across Asia, Europe, and North America.
Big corporations mining our data have been at the forefront of privacy discussions in recent years. The outbreak may well be a blessing for big tech companies that saw mistrust against them grow over the past years, as people became increasingly aware of the misuse of private information. The situation is posed for them to provide a positive contribution to a global problem to which everyone can relate. Another important point is the adoption of Big Data and AI solutions which are set to increase, as data science teams all around the world are being called to crunch petabytes of data and build prediction models for decision-makers. These solutions, if made safely available, may help us find treatments sooner and design effective contingency plans to help counteract the negative consequences of the aftermath of the outbreak. In fact, officials are more open to adopting new measures in the face of great economic and social challenges.
Are We Entering a New Era of Digital Surveillance?
China is the pivotal example of digital surveillance. The culture was already in place and was intensified during the outbreak. Thermal scans are a norm in public transportation, and security cameras that track every citizen's movements are widespread. This enables health officials to quickly track potential new cases as whoever shows high temperature is immediately detained and undergoes obligatory testing. Together with access to government-issued ID cards from every passenger, the police can quickly alert anyone that has been in contact with infected people, and instruct them to be quarantined.
This, coupled with the broad network of security cameras that track people breaching quarantine orders, enables authorities to have a tighter grip on the outbreak. Mobile phone data is also a rich source of information to track its citizens’ movements. Integrating data from “Close Contact Detector” apps and travel reports from telecom companies has enabled the country to build a strong response to the outbreak.
However, digital surveillance is on the rise worldwide. Other countries are considering implementing, or have already implemented, some version of location-data monitoring, including Belgium, UK, USA, China, South Korea, and Israel. The downside of such systems is a lack of privacy by design. Weak privacy laws in most countries, along with inadequate or insufficient anonymization technologies, expose the dangers of uncontrolled surveillance. In some countries, there have been concerning privacy violations, with personal health data being made public in Montenegro and Moldava, cyberattacks on hospital websites in Croatia and Romania, and imposed surveillance and phone tracking in Serbia.
Indeed, accessing mobile phone data has the potential to be a game-changer in the fight against the pandemic. Location data, that gather information of how people move through space over time, and contact tracing, identification of persons who may have come into contact with an infected person, are powerful sources of information that – if used in a correct and fair manner – could help monitor the progress of the pandemic by tracking how effective lockdown measures are and by helping to create a contact network.
Despite its intensive media coverage nowadays, the usage of location data is not new to fighting the spread of diseases. Prominent cases include the fight against malaria, dengue, and more recently, Ebola. Even though there was a commitment to tackle these problems by specific entities, like the Bill and Melinda Gates Foundation with the participation of Microsoft, these were not diseases that impacted the world on a global scale, therefore, no global solutions were pursued. But with high penetration rates (up to 90%), and reaching less developed countries, mobile phones can become a primary data source to tackle global crises.
Location data includes traditional Call Detail Records and high-frequency x-Detail Record (xDR), which provide real-time traffic information. Both are able to track the disease dynamics and are used by governmental agencies and industry, like Google or Facebook. Furthermore, there is already evidence where location data could help track a population’s compliance with social distancing measures. However, since this data includes social life habits, it is considered legally sensitive and subject to higher security standards and the requirement of the individual’s expressed consent.
Contact tracing is also a powerful source of information since it can trace and notify potentially infected people using contact lists, by tracking nearby cell phones via Bluetooth or GPS signals. This is potentially very effective, however, also problematic, as evidenced by this experiment where they estimated that 1% of London installing a malicious app could allow a digital attacker to track half of the London population without their consent.
But for this measure to be effective, we need a high penetration rate. Most people need to feel comfortable downloading and uploading content and personal information. Of course, in theory, this should be anonymized data where all personally identifiable information is removed. However, this Spatio-temporal data, is, unfortunately, very hard to anonymize. Research has shown that it is possible to re-identify 95% of individuals with only 4 places and times previously visited. Moreover, research from UCLouvain and Imperial College London built a model to evaluate deanonymization potential of a given dataset. For instance, 15 demographic attributes can render a unique 99.98% of a population the size of Massachusetts, which is made even easier for smaller populations. Other times it can be modified to track movements of groups of people, with no unique individual identifiers, referred to as aggregated data. But even aggregated data can be vulnerable to revealing sensitive information.
Thus, there is a need to find more effective ways to make this data safely available. There are currently a few privacy-oriented models enabling the secure anonymization of this data and we at MOSTLY AI are at the forefront of developing these solutions.
Fighting This Crisis Without Sacrificing Privacy
Many Asian countries learned to balance transparency with security and privacy from previous outbreaks. While there are clear compromises to be made, this should be done without risking personal identification. South Korea and Taiwan are examples of societies that have learned to leverage the power of digital data and the sharing of information to respond to pandemics. As a consequence of the SARS outbreak, they built a culture of trust where more flexible privacy regulations are adopted during times of epidemics, with clear consent from the population. Afterward, the data is owned again by the individuals that have the right to “be forgotten”.
The western world now has the opportunity to learn from the pandemic and use digital data to improve the rebound period. Even Margrethe Vestager, one of the forefront advocates for digital privacy laws, admits that tradeoffs have to be done during a time of crisis. However, this should not mean we enter a new age of digital surveillance.
Nowadays society seems primed for discussions around AI and data privacy, and the potential risks and benefits from new technologies. More people are aware of the possible dangers of uncontrolled information sharing and are therefore asking to be informed regarding the use and conditions of usage of their data. Most of us are debating the balance between ensuring a proper fight against the disease and ensuring our safety, versus blindly submitting to mass surveillance. What is the sweet spot? The final goal should be to track the virus and not surveil citizens.
The Global AI Ethics Consortium (GAIEC) on Ethics and the Use of Data and Artificial Intelligence in the Fight Against COVID-19 and other Pandemics has recently formed and is debating these issues. This consortium believes that there are potential risks in making decisions that will affect society in the long run based on problems affecting us in the present and forced by a health crisis. Their overall goal is to provide support and expertise in ethical questions relating to COVID-19, as well as to facilitate interaction by creating open communication avenues and possible collaborations.
As said before, the COVID-19 pandemic could be viewed as a call to action to determine how access to data could be improved. Since these issues require strong technical solutions, the innovations happening now could have an impact not only in times of crisis but also on how we see and act on modern society going forward.
Synthetic data is one of those technical solutions. Synthetic data, as the name suggests, is data that is artificially generated. Most often it is created by funneling real-world data through complex mathematical algorithms that capture the statistical features of the original information. It is highly accurate and as-good-as-real without being a copy of the original dataset. Due to the fact that synthetic data is generated completely from scratch, it is also fully anonymous and therefore ensures that individuals' privacy stays protected. Synthetic data is also exempt from data protection regulations; thus amenable to several opportunities for usage and sharing that are not possible with the original data. With our clients, we have seen that synthetic data makes data sharing easy while boosting collaborations - and we are convinced that synthetic data has tremendous potential to speed up our response to future crises.
Conclusion
This pandemic has tested the resilience and adaptability of governments and entire societies. And even though the world has overcome pandemics before, nowadays we have unprecedented tools that can turn the odds in our favor. We have the ability to gather and share data on a global scale. By upholding privacy rights and increasing transparency throughout the whole process, we may also increase people's trust and potentially change society’s relationship with these technologies. In fact, we can arise from the crisis with a more innovative, responsive and data-literate society, that is better equipped to handle similar emergencies in the future, as well as with strong collaborations that may go beyond the COVID-19 outbreak.