Table of Contents
What is data bias?
Data bias is the systematic error introduced into data workflows and machine learning (ML) models due to inaccurate, missing, or incorrect data points which fail to accurately represent the population. Data bias in AI systems can lead to poor decision-making, costly compliance issues as well as drastic societal consequences. Amazon’s gender-biased HR model and Google’s racially-biased hate speech detector are some well-known examples of data bias with significant repercussions in the real world. It is no surprise, then, that 54% of top-level business leaders in the AI industry say they are “very to extremely concerned about data bias”.
With the massive new wave of interest and investment in Large Language Models (LLMs) and Generative AI, it is crucial to understand how data bias can affect the quality of these applications and the strategies you can use to mitigate this problem.
In this article, we will dive into the nuances of data bias. You will learn all about the different types of data bias, explore real-world examples involving LLMs and Generative AI applications, and learn about effective strategies for mitigation and the crucial role of synthetic data.
Data bias types and examples
There are many different types of data bias that you will want to watch out for in your LLM or Generative AI projects. This comprehensive Wikipedia list contains over 100 different types, each covering a very particular instance of biased data. For this discussion, we will focus on 5 types of data bias that are highly relevant to LLMs and Generative AI applications.
- Selection bias
- Automation bias
- Temporal bias
- Implicit bias
- Social bias
Selection bias
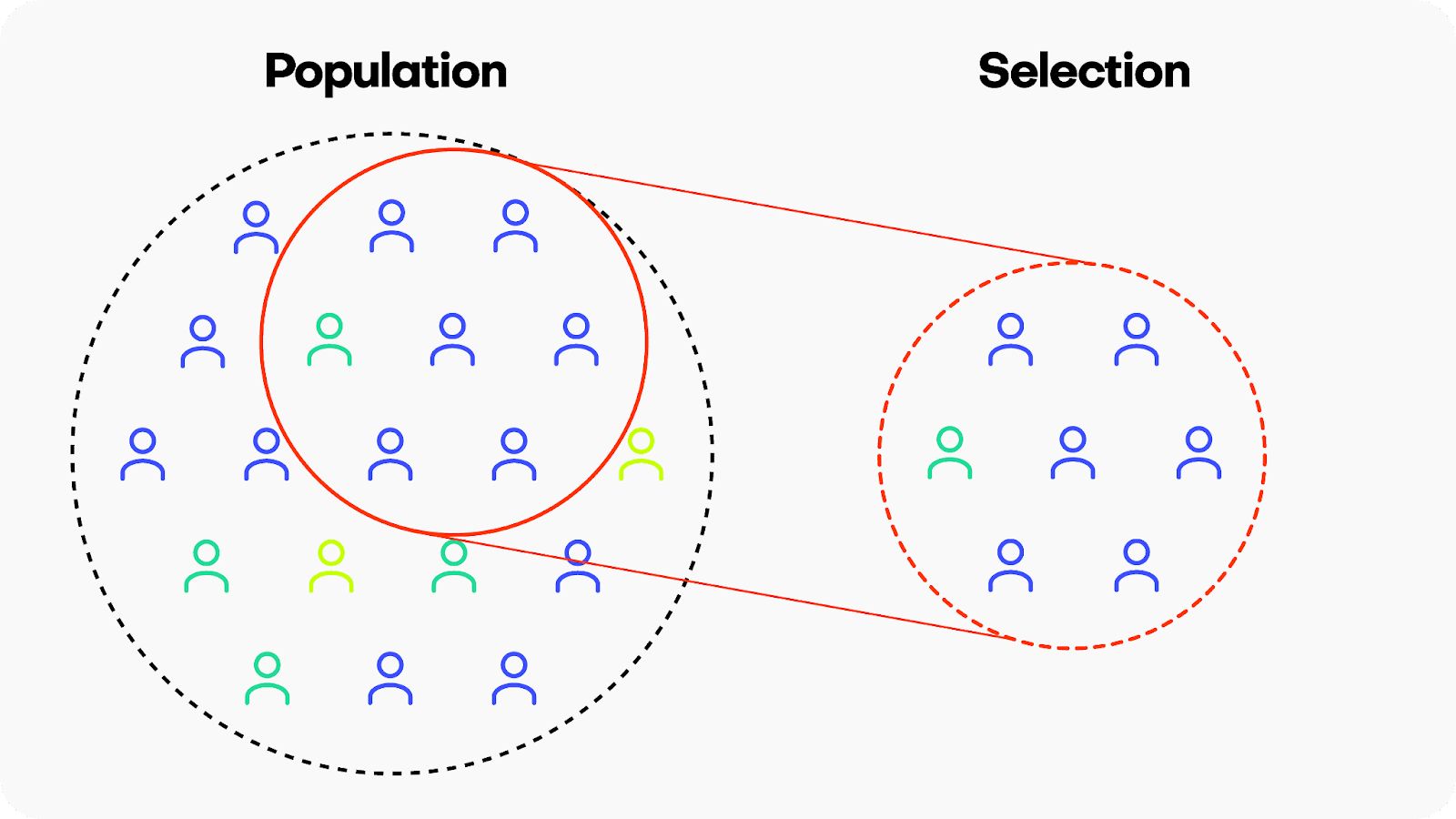
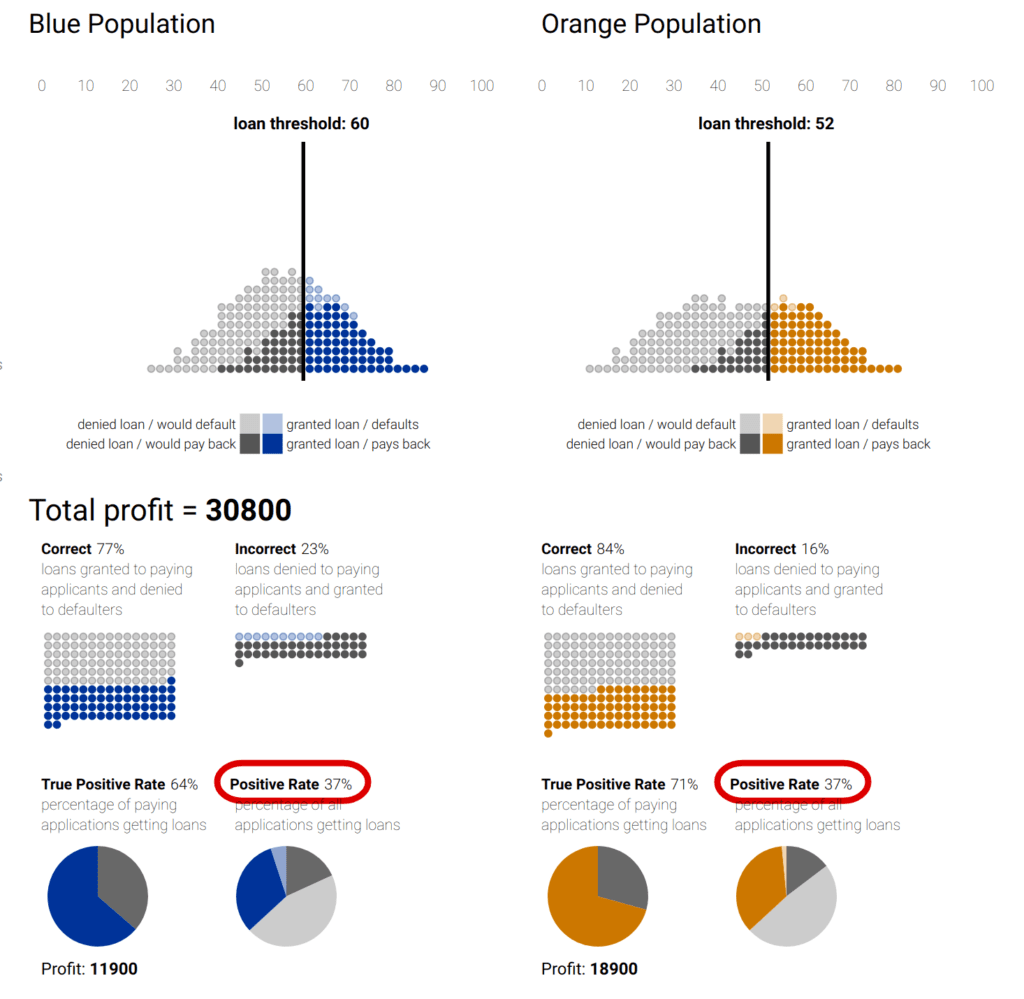
Selection bias occurs when the data used for training a machine learning model is not representative of the population it is intended to generalize to. This means that certain groups or types of data are either overrepresented or underrepresented, leading the model to learn patterns that may not accurately reflect the broader population. There are many different kinds of selection bias, such as sampling bias, participation bias and coverage bias.
Example: Google’s hate-speech detection algorithm Perspective is reported to exhibit bias against black American speech patterns, among other groups. Because the training data did not include sufficient examples of the linguistic patterns typical of the black American community, the model ended up flagging common slang used by black Americans as toxic. Leading generative AI companies like OpenAI, Anthropic and others are using Perspective daily at massive scale to determine the toxicity of their LLMs, potentially perpetuating these biased predictions.
Solution: Invest in high-quality, diverse data sources. When your data still has missing values or imbalanced categories, consider using synthetic data with rebalancing and smart imputation methods.
Automation bias

Automation bias is the tendency to favor results generated by automated systems over those generated by non-automated systems, irrespective of the relative quality of their outputs. This is becoming an increasingly relevant type of bias to watch out for as people, including top-level business leaders, may rush to implement automatically generated AI applications with the underlying assumption that simply because these applications use the latest, most popular tech their output will be inherently more trustworthy or performant.
Example: In a somewhat ironic overlap of generative technologies, a 2023 study found that some Mechanical Turk workers were using LLMs to generate the data which they were being paid to generate themselves. Later studies have since shown that training generative models on generated data can create a negative loop, also called “the curse of recursion”, which can significantly reduce output quality.
Solution: Include human supervision safeguards in any mission-critical AI application.
Temporal or historical bias
Temporal or historical bias arises when the training data is not representative of the current context in terms of time. Imagine a language model trained on a dataset from a specific time period, adopting outdated language or perspectives. This temporal bias can limit the model's ability to generate content that aligns with current information.

Example: ChatGPT’s long-standing September 2021 cut-off date is a clear example of a temporal bias that we have probably all encountered. Until recently, the LLM could not access training data after this date, severely limiting its applicability for use cases that required up-to-date data. Fortunately, in most cases the LLM was aware of its own bias and communicated it clearly with responses like "'I'm sorry, but I cannot provide real-time information".
Solution: Invest in high-quality data, up-to-date data sources. If you are still lacking data records, it may be possible to simulate them using synthetic data’s conditional generation feature.
Implicit bias
Implicit bias can happen when the humans involved in ML building or testing operate based on unconscious assumptions or preexisting judgments that do not accurately match the real world. Implicit biases are typically ingrained in individuals based on societal and cultural influences and can impact perceptions and behaviors without conscious awareness. Implicit biases operate involuntarily and can influence judgments and actions even when an individual consciously holds no biased beliefs. Because of the implied nature of this bias, it is a particularly challenging type of bias to address.
Example: LLMs and generative AI applications require huge amounts of labeled data. This labeling or annotation is largely done by human workers. These workers may operate with implicit biases. For example, in assigning a toxicity score for specific language prompts, a human annotation worker may assign an overly cautious or liberal score depending on personal experiences related to that specific word or phrase.
Solution: Invest in fairness and data bias training for your team. Whenever possible, involve multiple, diverse individuals in important data processing tasks to balance possible implicit biases.
Social bias
Social bias occurs when machine learning models reinforce existing social stereotypes present in the training data, such as negative racial, gender or age-dependent biases. Generative AI applications can inadvertently perpetuate biased views if their training data includes data that reflects societal prejudices. This can result in responses that reinforce harmful societal narratives. As ex-Google researcher Timit Gebru and colleagues cautioned in their 2021 paper: “In accepting large amounts of web text as ‘representative’ of ‘all’ of humanity [LLMs] risk perpetuating dominant viewpoints, increasing power imbalances and further reifying inequality.”
Example: Stable Diffusion and other generative AI models have been reported to exhibit socially biased behavior due to the quality of their training datasets. One study reported that the platform tends to underrepresent women in images of high-performing occupations and overrepresent darker-skinned people in images of low-wage workers and criminals. Part of the problem here seems to be the size of the training data. Generative AI models require massive amounts of training data and in order to achieve this data volume, the selection controls are often relaxed leading to poorer quality (i.e. more biased) input data.
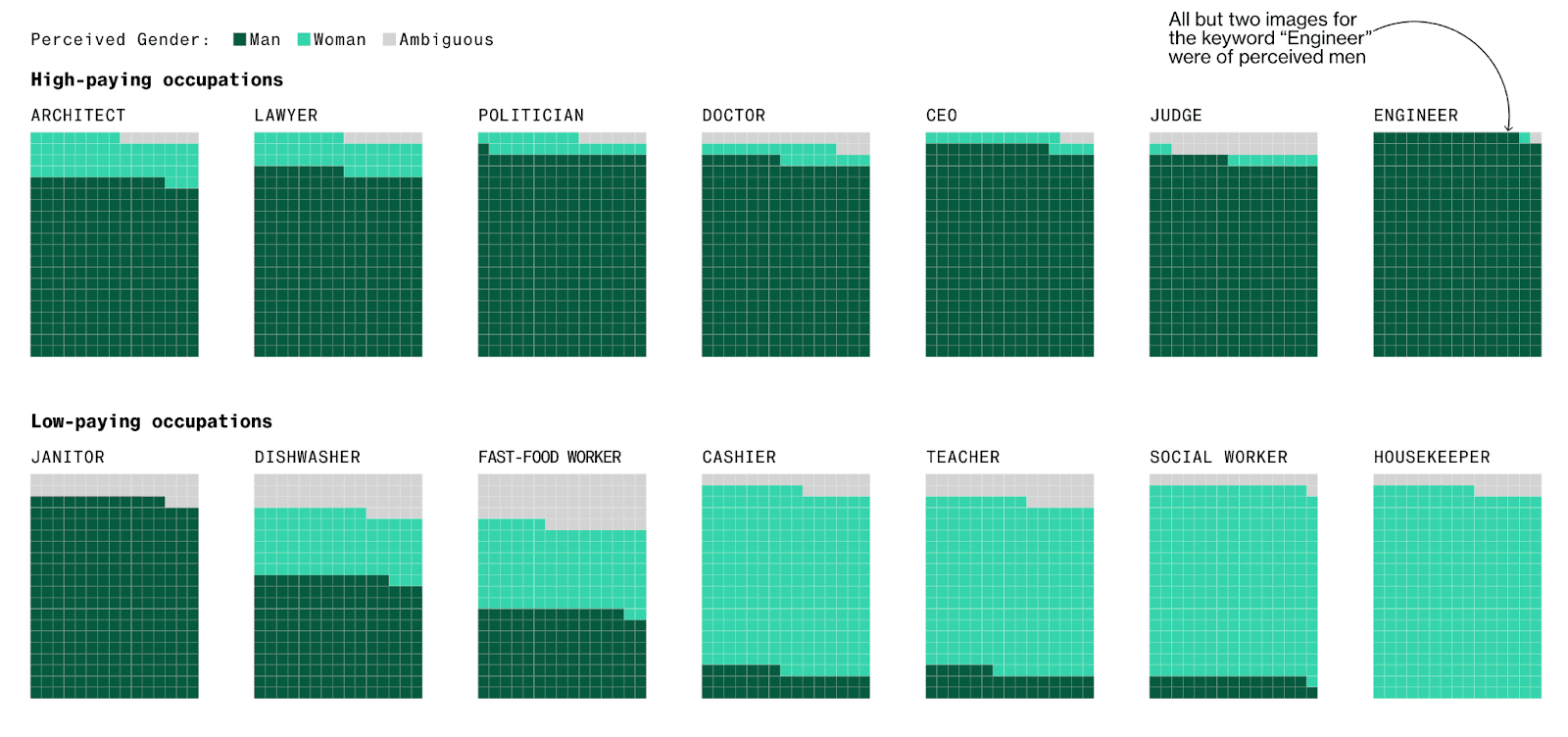
Solution: Invest in high-quality, diverse data sources as well as data bias training for your team. It may also be possible to build automated safeguarding checks that will spot social bias in model outputs.
Perhaps more than any other type of data bias, social bias shows us the importance of the quality of the data you start with. You may build the perfect generative AI model but if your training data contains implicit social biases (simply because these biases existed in the subjects who generated the data) then your final model will most likely reproduce or even amplify these biases. For this reason, it’s crucial to invest in high-quality training data that is fair and unbiased.
Strategies for reducing data bias
Recognizing and acknowledging data bias is of course just the first step. Once you have identified data bias in your project you will also want to take concrete action to mitigate it. Sometimes, identifying data bias while your project is ongoing is already too late; for this reason it’s important to consider preventive strategies as well.
To mitigate data bias in the complex landscape of AI applications, consider:
- Investing in dataset diversity and data collection quality assurances.
- Performing regular algorithmic auditing to identify and rectify bias.
- Including humans in the loop for supervision.
- Investing in model explainability and transparency.
Let’s dive into more detail for each strategy.
Diverse dataset curation
There is no way around the old adage: “garbage in, garbage out”. Because of this, the cornerstone of combating bias is curating high-quality, diverse datasets. In the case of LLMs, this involves exposing the model to a wide array of linguistic styles, contexts, and cultural nuances. For Generative AI models more generally, it means ensuring to the best of your ability that training data sets are sourced from as varied a population as possible and actively working to identify and rectify any implicit social biases. If, after this, your data still has missing values or imbalanced categories, consider using synthetic data with rebalancing and smart imputation methods.
Algorithmic auditing
Regular audits of machine learning algorithms are crucial for identifying and rectifying bias. For both LLMs and generative AI applications in general, auditing involves continuous monitoring of model outputs for potential biases and adjusting the training data and/or the model’s architecture accordingly.
Humans in the loop
When combating data bias it is ironically easy to fall into the trap of automation bias by letting programs do all the work and trusting them blindly to recognize bias when it occurs. This is the core of the problem with the widespread use of Google’s Perspective to avoid toxic LLM output. Because the bias-detector in this case is not fool-proof, its application is not straightforward. This is why the builders of Perspective strongly recommend continuing to include human supervision in the loop.
Explainability and transparency
Some degree of data bias is unavoidable. For this reason, it is crucial to invest in the explainability and transparency of your LLMs and Generative AI models. For LLMs, providing explanations and sources for generated text can offer insights into the model's decision-making process. When done right, model explainability and transparency will give users more context on the generated output and allow them to understand and potentially contest biased outputs.
Synthetic data reduces data bias
Synthetic data can help you mitigate data bias. During the data synthesization process, it is possible to introduce different kinds of constraints, such as fairness. The result is fair synthetic data, without any bias. You can also use synthetic data to improve model explainability and transparency by removing privacy concerns and significantly expanding the group of users you can share the training data with.
More specifically, you can mitigate the following types of data bias using synthetic data:
Selection Bias
If you are dealing with imbalanced datasets due to selection bias, you can use synthetic data to rebalance your datasets to include more samples of the minority population. For example, you can use this feature to provide more nuanced responses for polarizing topics (e.g. book reviews, which generally tend to be overly positive or negative) to train your LLM app.
Social Bias
Conditional data generation enables you to take a gender- or racially-biased dataset and simulate what it would look like without the biases included. For example, you can simulate what the UCI Adult Income dataset would look like without a gender income gap. This can be a powerful tool in combating social biases.
Reporting or Participation Bias
If you are dealing with missing data points due to reporting or participation bias, you can use smart imputation to impute the missing values in a high-quality, statistically representative manner. This allows you to avoid data loss by allowing you to use all the records available. Using MOSTLY AI’s Smart Imputation feature it is possible to recover the original population distribution which means you can continue to use the dataset as if there were no missing values to begin with.
Mitigating data bias in LLM and generative AI applications
Data bias is a pervasive and multi-faceted problem that can have significant negative impacts if not dealt with appropriately. The real-world examples you have seen in this article show clearly that even the biggest players in the field of AI struggle to get this right. With tightening government regulations and increasing social pressure to ensure fair and responsible AI applications, the urgency to identify and rectify data bias at all points of the LLM and Generative AI lifecycle is only becoming stronger.
In this article you have learned how to recognise the different kinds of data bias that can affect your LLM or Generative AI applications. You have explored the impact of data bias through real-world examples and learned about some of the most effective strategies for mitigating data bias. You have also seen the role synthetic data can play in addressing this problem.
If you’d like to put this new knowledge to use directly, take a look at our hands-on coding tutorials on conditional data generation, rebalancing, and smart imputation. MOSTLY AI's free, state-of-the-art synthetic data generator allows you to try these advanced data augmentation techniques without the need to code.
For a more in-depth study on the importance of fairness in AI and the role that synthetic data can play, read our series on fair synthetic data.
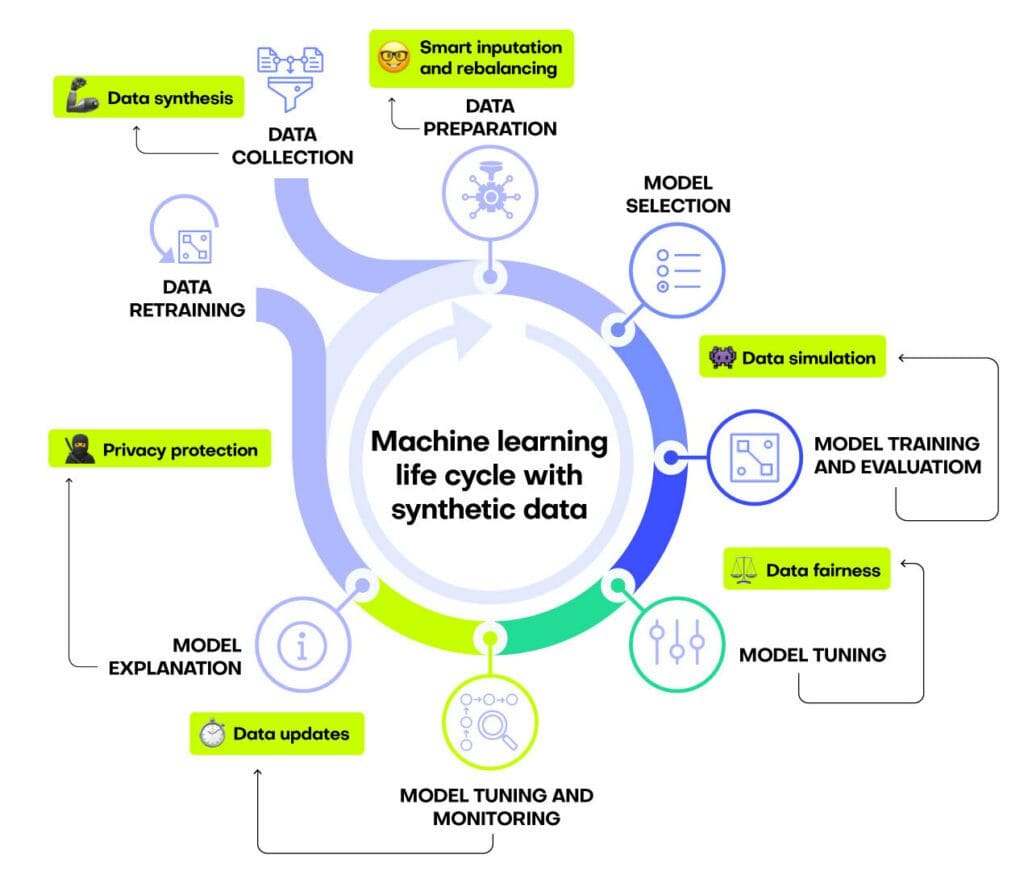
Machine learning and AI applications are becoming more and more common across industries and organizations. This makes it essential for more and more developers to understand not only how machine learning models work, but how they are developed, deployed, and maintained. In other words, it becomes crucial to understand the machine learning process in its entirety. This process is often referred to as “the machine learning life cycle”. Maintaining and improving the quality of a machine learning life cycle enables you to develop models that consistently perform well, operate efficiently and mitigate risks.
This article will walk you through the main challenges involved in ensuring your machine learning life cycle is performing at its best. The most important factor is the data that is used for training. Machine learning models are only as good as the data that goes into them; a classic example of “garbage in, garbage out”.
Synthetic data can play a crucial role here. Injecting synthetic data into your machine learning life cycle at key stages will improve the performance, reliability, and security of your models.
What is a machine learning life cycle?
A machine learning life cycle is the process of developing, implementing and maintaining a machine learning project. It includes both the collection of data as well as the making of predictions based on that data. A machine learning life cycle typically consists of the following steps:
- Data Collection
- Data Preparation
- Model Selection
- Model Training and Evaluation
- Model Tuning
- Model Deployment and Monitoring
- Model Explanation
- Model Retraining
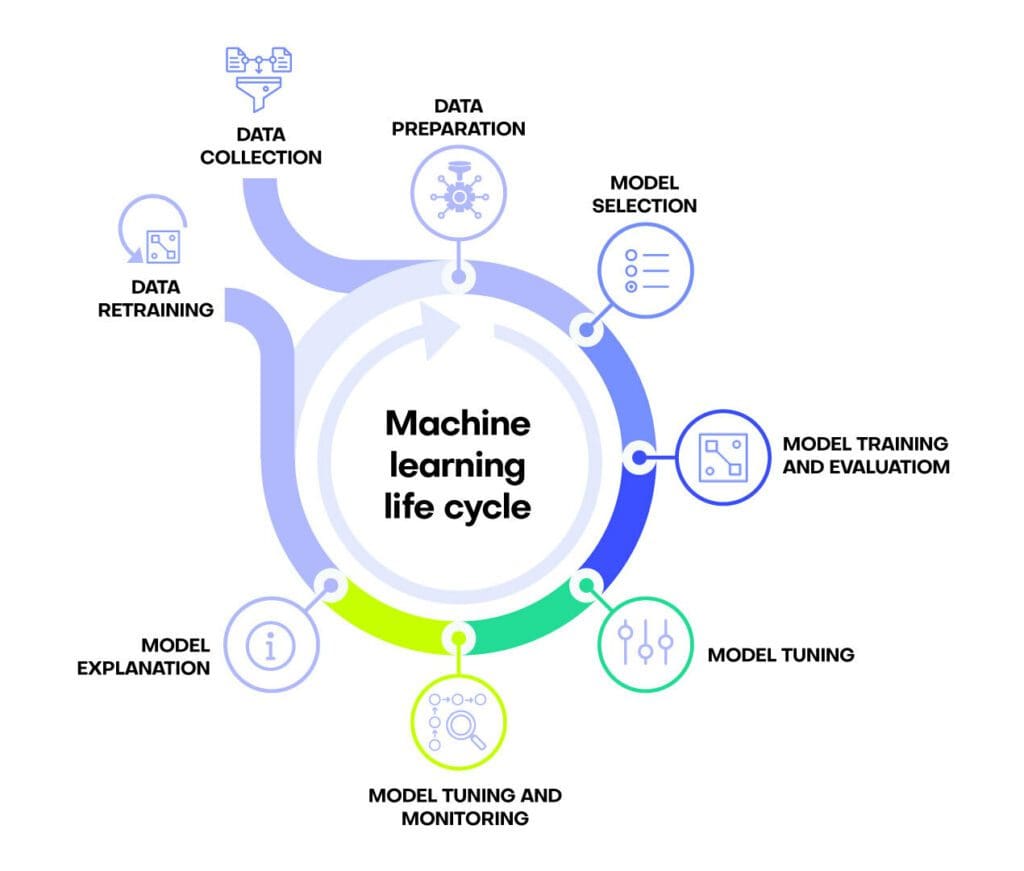
In reality, the process of a machine learning life cycle is almost never linear. The order of steps may shift and some steps may be repeated as changes to the data, the context, or the business goal occur.
There are plenty of resources out there that describe the traditional machine learning life cycle. Each resource may have a slightly different way of defining the process but the basic building blocks of a machine learning life cycle are commonly agreed upon. There’s not much new to add there.
This article will focus on how you can improve your machine learning life cycle using synthetic data. The article will discuss common challenges that any machine learning life cycle faces and show you how synthetic data can help you overcome these common problems. By the end of this article, you will have a clear understanding of how you can leverage synthetic data to boost the performance of your machine learning models.
The short version: synthetic data can boost your machine learning life cycle because it is:
- high-quality,
- high-availability, and
- privacy-proof.
Read on to learn more 🧐
The role of synthetic data in your ML life cycle
Every machine learning life cycle encounters some, if not all, of the problems listed here:
- A lack of available training data, often due to privacy regulations
- Missing or imbalanced data, which will impact the quality of the downstream machine learning model
- Biased data, which will impact the fairness of the downstream machine learning model
- Data drift, which will impact model performance over time
- Inability to share models or results due to privacy concerns
Let’s take a look at each one of these problems and see how synthetic data can support the quality of your machine learning life cycle in each case.
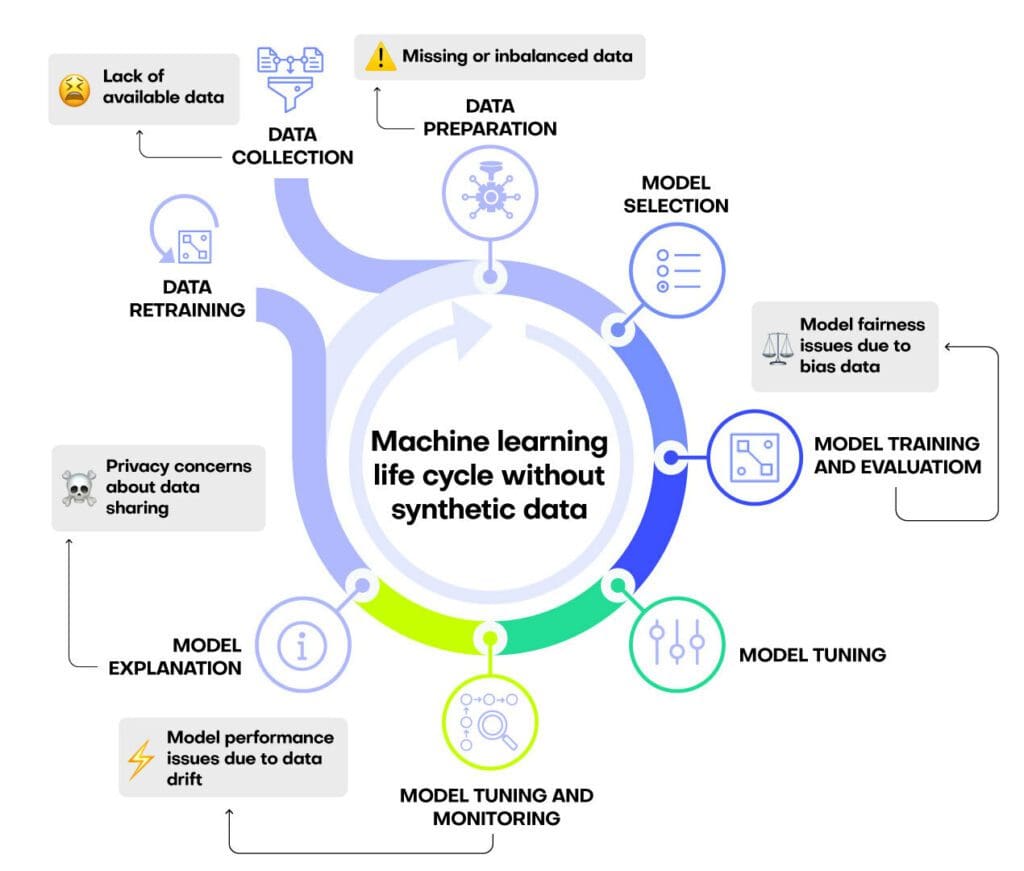
Data collection
The problem starts right at the first step of any machine learning project: data collection. Any machine learning model is only as good as the data that goes into it and collecting high-quality, usable data is becoming more and more difficult. While the overall volume of data available to analysts may well be exploding, only a small fraction of this can actually be used for machine learning applications. Privacy regulations and concerns obstruct many organizations from using available data as part of their machine learning project. It is estimated that only 15-20% of customers consent to their data being used for analytics, which includes training machine learning models.
Synthetic data is infinitely available. Use synthetic data to generate enough data to train your models without running into privacy concerns.
Once your generator has been trained on the original dataset it is able to generate as many rows of high-quality, synthetic data as you need for your machine learning application. This is a game-changer as you no longer have to scrape together enough high-quality rows to make your machine learning project work. Make sure to use a synthetic data generator that performs well on privacy-preservation benchmarks.
Data preparation
Real-world data is messy. Whether it’s due to human error, sensor failure or another kind of anomaly, real-world datasets almost always contain incorrect or missing values. These values need to be identified and either corrected or removed from the dataset. The first option (correction) is time-intensive and painstaking work. The second option (removal) is less demanding, but can lead to a decrease in the performance of the downstream machine learning model as it means removing valuable training data.
Even if the data sourcing is somehow perfect – what a world that would be! – your machine learning lifecycle may still be negatively impacted by an imbalanced dataset. This is especially relevant for classification problems with a majority and a minority class in which the minority class needs to be identified.
Fraud detection in credit card transactions is a good example of this: the vast majority of credit card transactions are perfectly acceptable and only a very small portion of transactions are fraudulent. It is crucial to credit card companies that this very small portion of transactions is properly identified and dealt with. The problem is that a machine learning model trained on the original dataset will not have enough examples of fraudulent behavior to properly learn how to identify them because the dataset is imbalanced.
Synthetic data can be better than real. Use synthetic data to improve the quality of your original dataset through smart imputation and synthetic rebalancing.
Model training and evaluation
Many machine learning models suffer from embedded biases in the training data which negatively impact the model’s fairness. This can have negative effects on both societal issues as well as on companies’ reputation and profit. In one infamous case investigated by ProPublica, a machine learning model used by the U.S. Judicial system was shown to make biased decisions according to defendants’ ethnicity. This led to incorrect predictions on the likelihood of defendants to re-offend which in turn affected their access to early probation or treatment programs.
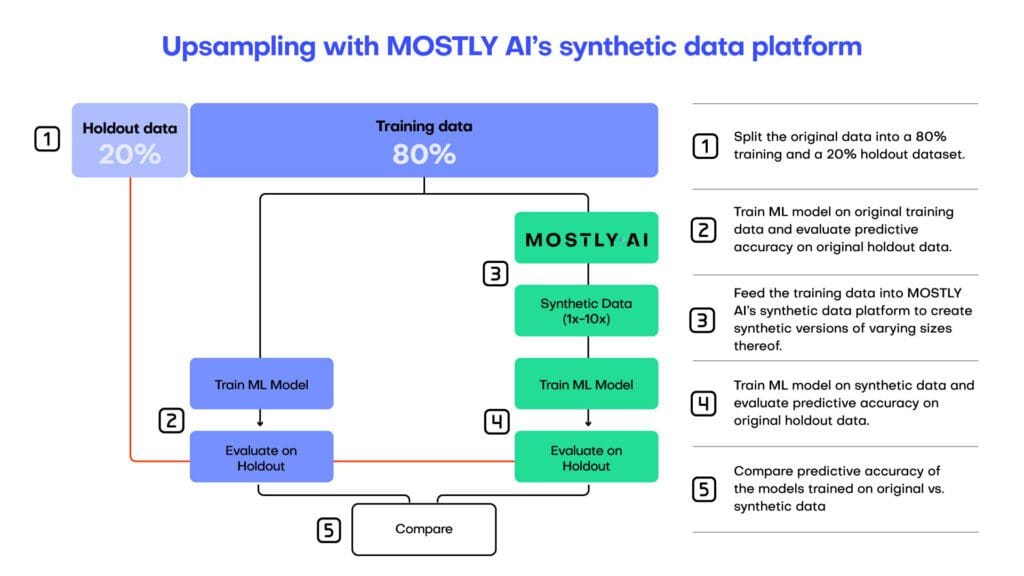
While there is no single cause for biased training data, one of the major problems is a lack of sufficient training data, leading to certain demographic groups being underrepresented. As we have seen, synthetic data can overcome this problem both because it is infinitely available and because imbalances in the data can be fixed using synthetic upsampling.
But biases in AI machine learning models are not always due to insufficient training data. Many of the biases are simply present in the data because we as humans are all biased to some degree and these human biases find their way into training data.
This is precisely where Fair Synthetic Data comes in. Fair Synthetic Data is data whose biases have been corrected through statistical tools such as demographic parity. By adding fairness constraints to their models, synthetic data generators are able to ensure these statistical measures of fairness.
Synthetic data can increase data fairness. Use synthetic data to deal with embedded biases in your dataset by increasing the size and diversity of the training data and ensuring demographic parity.
Model tuning and maintenance
Once a machine learning model has been trained, it needs to be tuned in order to boost its performance. This is generally done through hyperparameter optimization in order to find the model parameter values that yield the best results. While this is a useful tool to enhance model performance, the improvements made tend to be marginal. The improvements are ultimately limited by the quality and quantity of your training data.
If you are working with a flexible capacity machine learning model (like XGBoost, LightGBM, or Random Forest), you may be able to use synthetic data to boost your machine learning model’s performance. While traditional machine learning models like logistic regression and decision trees have a low and fixed model capacity (meaning they can’t get any smarter by feeding them more training data), modern ensemble methods saturate at a much later point and can benefit from more training data samples.
In some cases, machine learning model accuracy can improve up to 15% by supplementing the original training data with additional synthetic samples.
Once your model performance has been fine-tuned, it will need to be maintained. Data drift is a common issue affecting machine learning models. As time passes, the distributions in the dataset change and the model is no longer operating at maximum performance. This generally requires a re-training of the model on updated data so that it can learn to recognize the new patterns.
Synthetic data can increase model accuracy. Use synthetic data to boost flexible-capacity model performance by providing additional training samples and to combat data drift by generating fresh data samples on demand.
Model explanation and sharing
The final step of any machine learning life cycle is the explanation and sharing of the model and its results.
Firstly, the project stakeholders are naturally interested in seeing and understanding the results of the machine learning project. This means presenting the results as well as explaining how the machine learning model arrived at these results. While this may seem straightforward at first, this may become complicated due to privacy concerns.
Secondly, many countries have AI governance regulations in place that require access to both the training data and the model itself. This may pose a problem if the training data is sensitive and cannot be shared further. In this case, high-quality, representative synthetic data can serve as a drop-in replacement. This synthetic data can then be used to perform model documentation, model validation and model certification. These are key components of establishing trust in AI.
Synthetic data safeguards privacy protection. Use synthetic data to support Explainable AI efforts by providing highly-representative versions of sensitive training datasets.
The role of synthetic data in your ML life cycle
Synthetic data can address key pain points in any machine learning life cycle. This is because synthetic data can overcome limitations of the original, raw data collected from ‘the real world’. Specifically, synthetic data can be highly available, balanced, and unbiased.
You can improve the quality of your machine learning life cycle by using synthetic data to:
- Generate sufficient training data without privacy concerns
- Improve data quality through smart imputation and synthetic rebalancing
- Improve data fairness by removing embedded biases
- Boost model accuracy through training sample generation and data updates
- Share and explain AI models without infringing on privacy regulations
If you’re looking for a synthetic data generator that is able to consistently deliver optimal privacy and utility performance, give synthetic data generation a try today and let us know what you think – the first 100K rows of synthetic data are on us!
Historically, synthetic data has been predominantly used to anonymize data and protect user privacy. This approach has been particularly valuable for organizations that handle vast amounts of sensitive data, such as financial institutions, telecommunications companies, healthcare providers, and government agencies. Synthetic data offers a solution to privacy concerns by generating artificial data points that maintain the same patterns and relationships as the original data but do not contain any personally identifiable information (PII).
There are several reasons why synthetic data is an effective tool for privacy use cases:
- Privacy by design: Synthetic data is generated in a way that ensures privacy is built into the process from the beginning. By creating data that closely resembles real-world data but without any PII, synthetic data allows organizations to share information without the risk of exposing sensitive information or violating privacy regulations.
- Compliance with data protection regulations: Synthetic data helps organizations adhere to data protection laws, such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA). Since synthetic data does not contain PII, organizations can share and analyze data without compromising user privacy or breaching regulations.
- Collaboration and data sharing: Synthetic data enables organizations to collaborate and share data more easily and securely. By using synthetic data, researchers and analysts can work together on projects without exposing sensitive information or violating privacy rules.
However, recent advancements in technology and machine learning have illuminated the vast potential of synthetic data, extending far beyond the privacy use case. A recent paper from Boris van Breugel and Michaela van der Schaar describes how AI-generated synthetic data moved beyond the data privacy use case. In this blog post, we will explore the potential of synthetic data beyond data privacy applications and the direction in which MOSTLY AI's synthetic data platform has been developing, including new features beyond privacy, such as data augmentation and data balancing, domain adaptation, simulations, and bias and fairness.
Data augmentation and data balancing
Synthetic data can be used to augment existing datasets, particularly when there is just not enough data or there is an imbalance in data representation. Already back in 2020 we showed that by simply generating more synthetic data than was there in the first place, it’s possible to improve the performance of a downstream task.
Since then, we have seen more and more interest in utilizing synthetic data to boost the performance of machine learning models. And there are two distinct approaches that one can take to achieve this: either amplifying existing data by creating more synthetic data (as we did in our research) and only working with the synthetic data or mixing real and synthetic data.
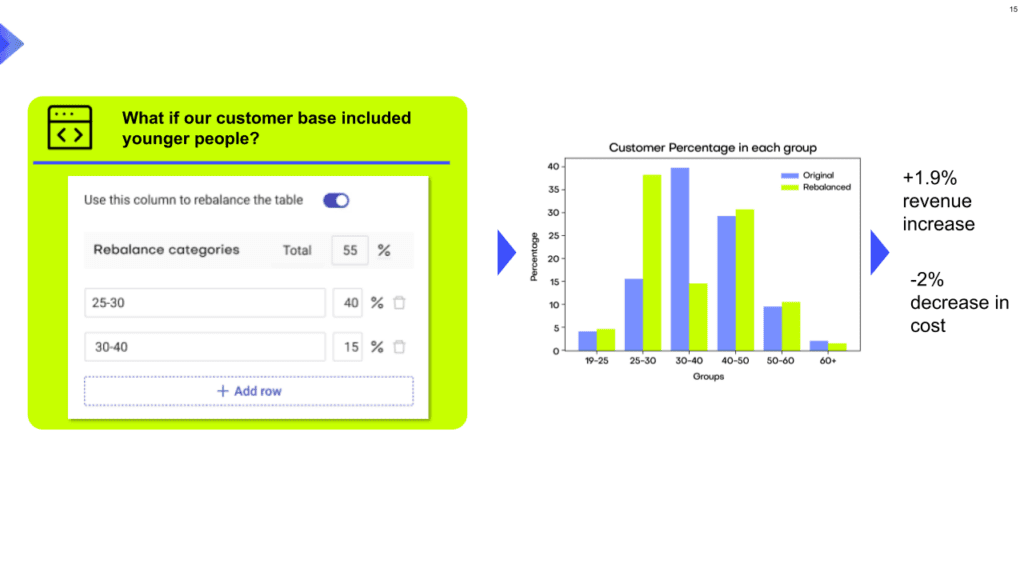
But synthetic data can also help with highly imbalanced datasets. In the realm of machine learning, imbalanced datasets can lead to biased models that perform poorly on underrepresented data points. Synthetic data generation can create additional data points for underrepresented categories, effectively balancing the dataset and improving the performance of the resulting models. We recently published a blog post on data augmentation with details about how our platform can be used to augment existing datasets.
Domain adaptation
In many cases, machine learning models are trained on data from one domain but need to be applied to a different domain where no or not enough training data exists, or where it would be costly to obtain that data. Synthetic data can bridge this gap by simulating the target domain's data, allowing models to adapt and perform better in the new environment. One of the advantages of this approach is that the standard downstream models don’t need to be changed and can be compared easily.
This has applications in various industries. We currently see the most applications of this use case in the unstructured data space. For example, when generating training material for autonomous vehicles, where synthetic data can be generated to simulate different driving conditions and scenarios. Or, similarly, in medical imaging, synthetic data can be generated to mimic different patient populations or medical conditions, allowing healthcare professionals to test and validate machine learning algorithms without the need for vast amounts of real-world data, which can be challenging and expensive to obtain.
However, the same approach and benefits hold true for structured, tabular data as well and it’s an area where we see great potential for structured synthetic data in the future.
Data simulations
But what happens if there is no real-world data at all to work with? Synthetic data can help in this scenario too. Synthetic data can be used to create realistic simulations for various purposes, such as testing, training, and decision-making. Companies can develop synthetic business scenarios and simulate customer behavior.
One example is the development of new marketing strategies for product launches. Companies can generate synthetic customer profiles that represent a diverse range of demographics, preferences, and purchasing habits. By simulating the behavior of these synthetic customers in response to different marketing campaigns, businesses can gain insights into the potential effectiveness of various strategies and make data-driven decisions to optimize their campaigns. This approach allows companies to test and refine their marketing efforts without the need for expensive and time-consuming real-world data collection.
In essence simulated synthetic data holds the potential of being the realistic data that every organization wishes to have: data that is relatively low-effort to create, cost-efficient, and highly customizable. This flexibility will allow organizations to innovate, adapt, and improve their products and services more effectively and efficiently.
Bias and fairness
Bias in datasets can lead to unfair and discriminatory outcomes in machine learning models. These biases often stem from historical data that reflects societal inequalities and prejudices, which can inadvertently be learned and perpetuated by the algorithms. For example, a facial recognition system trained on a dataset predominantly consisting of light-skinned individuals may have difficulty accurately identifying people with darker skin tones, leading to misclassifications and perpetuating racial bias. Similarly, a hiring algorithm trained on a dataset with a higher proportion of male applicants may inadvertently favor male candidates over equally qualified female candidates, perpetuating gender discrimination in the workplace.
Therefore, addressing bias in datasets is crucial for developing equitable and fair machine learning systems that provide equal opportunities and benefits for all individuals, regardless of their background or characteristics.
Synthetic data can help address these issues by generating data that better represents diverse populations, leading to more equitable and fair models. In short: one can generate fair synthetic data based on unfair real data. Already 3 years ago we showed this in our 5-part Fairness Blogpost Series that you can re-read to learn why bias in AI is a problem and how bias correction is one of the main potentials of synthetic data. There we also show the complexity and challenges of the topic including first and foremost how to define what is fair. We see an increasing interest in the market for leveraging synthetic data to address biases and fairness.
There is no question about it: the potential of synthetic data extends far beyond privacy and anonymization. As we showed, synthetic data offers a range of powerful applications that can transform industries, enhance decision-making, and ultimately change the way we work with data. By harnessing the power of synthetic data, we can unlock new possibilities, create more equitable models, and drive innovation in the data-driven world.
Synthetic data is quickly becoming a critical tool for organizations to unlock the value of sensitive customer data while keeping the privacy of their customers protected and in compliance with data protection regulations such as GDPR and CCPA. It can be generated quickly in abundance and has been proven to drastically improve machine learning performance. As a result, it is often used for advanced analytics and AI training, such as predictive algorithms, fraud detection and pricing models.
According to Gartner, by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.
MOSTLY AI pioneered the creation of synthetic data for AI model development and software testing. With things moving so quickly in this space here are three trends that we see happening in AI and synthetic data in 2022:
1. Bias in AI will get worse before it gets better.
Most of the machine learning and AI algorithms currently in production, interacting with customers, making decisions about people have never been audited for fairness and discrimination, the training data has never been augmented to fix embedded biases. It is only through massive scandals that companies are finding out and learning the hard way that they need to pay more attention to biased data and to use fair synthetic data instead.
2. Companies’ data assets will freeze up due to regulations and declining customer consent.
Regulations all over the world are getting stricter every day; many countries have a personal data protection policy in place by now. Using customer data is getting increasingly difficult for a number of other reasons too - people are more privacy-conscious and are increasingly likely to refuse consent to using their data for analytics purposes. So companies literally run out of relevant and usable data assets. Companies will learn to understand that synthetic data is the way out of this dilemma.
3. Synthetic data will be standardized with globally recognized benchmarks for privacy and accuracy.
Not all synthetic data is created equal. To start off with, there is a world of difference between what we call structured and unstructured synthetic data. Unstructured data means images and text for example, while structured data is mainly tabular in nature. There are lots of open source and proprietary synthetic data providers out there for both kinds of synthetic data and the quality of their generators varies widely. It’s high time to establish a synthetic data standard to make sure that synthetic data users get consistently high-quality synthetic data. We are already working on structured synthetic data standards.
If you’d like to connect on these trends, we’re happy to set up an interview or write a byline on these topics for your publication. Please let us know - thanks.
MOSTLY AI has recently been mentioned in an excellent article about synthetic data by the MIT Technology Review. We are honored to have been featured and would like to elaborate on some topics Karen Hao, the renowned AI journalist, raised.
On synthetic data's potential for fair AI
As the article states, extrapolating new data from an existing data set indeed reproduces the biases embedded in the original. However, it is possible to augment the data to make it fairer via synthetization. For example, our team fixed the racial bias in the infamous Compas recidivism data set and reduced the racial difference in the data from 24% to a mere 1% by introducing demographic parity through the synthetization process. Thus, our research proves that it is indeed possible to synthesize near bias-free versions of your data.
According to Christo Wilson, an associate professor of computer science at Northeastern University, perfectly balanced data sets don't automatically translate into perfectly fair AI systems. They don't. That is exactly why you need synthetic data. Simply upping subject numbers for minorities or removing sensitive categories like race does not solve the issue. Synthetization, on the other hand, is capable of fixing biases in a holistic way, regenerating data to reflect reality not as it is but as we would like to see it.
As long as you are aware of your biases and your definition of fairness is solid and fits the specific case you are looking at, you can create a data set that satisfies these constraints. If you are curious and would like to know more, check out our fair synthetic data research poster presented at the ICLR 2021 machine learning conference!
Synthetic data for explainable AI
The article quotes one of our favorite ethical AI activists, Cathy O'Neil: 'As regulators confront the need to test AI systems for legal compliance, it could be the only approach that gives them the flexibility they need to generate on-demand, targeted testing data.' Indeed, the role of synthetic data is about to become even more pronounced with the upcoming AI regulations looming over Europe and elsewhere. Synthetic data can provide local interpretability to AI systems, essentially functioning as a window into the workings of an algorithm. If you are curious about how synthetic data can power explainable AI in practical terms, check out our recent synthetic data for XAI manifesto!
To the future of synthetic data and beyond
Cathy O'Neil says, 'Synthetic data is likely to get better over time, but not by accident.' We couldn't agree more, and our world-class team of scientists and engineers is constantly working on just that. If you would like to be there when synthetic data breakthroughs happen, sign up for the MOSTLY AI newsletter!
Last year MOSTLY AI has introduced and demonstrated the groundbreaking idea of generating fair synthetic data. I.e., data, that is representative of the real world, but that has unwanted biases, unwanted relations, surgically removed from it at the same time. Machine learning models that are then trained on fair synthetic data will be fair by design. It’s a thought-provoking paradigm shift, that will allow organizations to govern not only Privacy but also Fairness within AI at its source, that is the AI training data itself.
Fast forward to today, we are excited to see many things happening around fairness:
- The broad public interest in fairness and AI bias has drastically picked up, resulting in media coverage, documentaries, books, public debates, analyst reports, etc.
- The regulators are becoming active, with most notably the European Commission proposing an AI regulation, that explicitly demands that training data shall be fair & representative. US regulators are expected to follow suit, particularly within high-risk domains, like finance and health care.
- Leading AI conferences, like the ICLR, expand beyond accuracy and dedicate workshops to ethics, like Responsible AI or Synthetic Data for Privacy.
Speaking of ICLR, we had the honor to present our work on fair synthetic data at this year’s conference. This is another recognition of our work, which was already featured by Andrew Ng, IEEE Spectrum, Forbes, Slate, and many more. While the corresponding research paper is now available on arxiv.org, and the Fair Synthetic Data poster is accessible here, we summarize the key take aways once more:
- MOSTLY AI’s technology allows to generate Synthetic Data that is both statistical representative as well as fair - in the sense that it adheres to provided fairness constraints
- The trade-off between representativeness and fairness can be explicitly controlled for.
- Hidden proxy variables (e.g., body height serving as proxy for gender, or ZIP codes for race), which pose a significant challenge in combating biases, are successfully controlled for.
- And fairness can be established while only marginally impacting the downstream machine learning utility. One thus does not need to compromise significantly on accuracy in the pursuit of Ethical AI. Find out how to create fair synthetic data from our earlier blog post!

Last but not least, and as further testimony to the validity of the approach, Amazon just published a paper on fast fair synthetic data as well. And as their study leverages the same US census data as our paper, it allows for a direct comparison of results. We always knew that the quality of our synthetic data is unparalleled, but even we were amazed to see the effectiveness of our approach, as we excel on every single available dimension of realism, accuracy, as well as fairness:
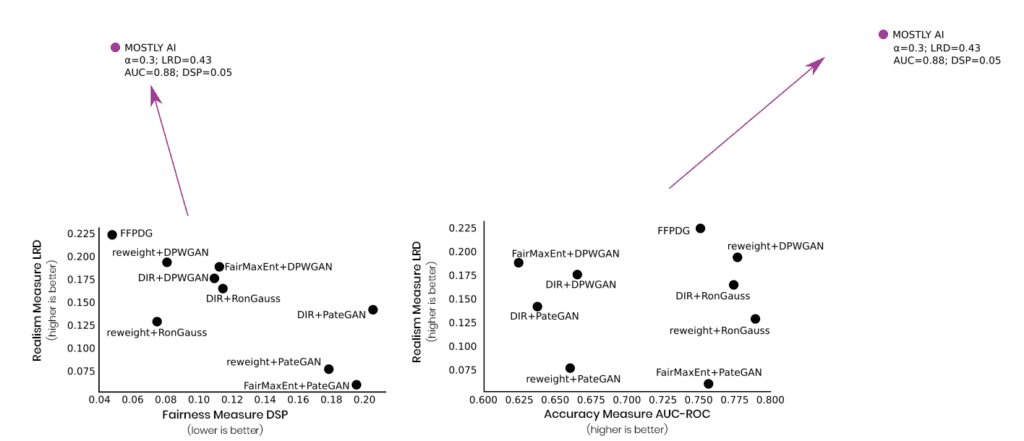
So, if Ethical AI is a priority for your organization or you deploy AI algorithms that directly impact the lives of individuals, then talk to us, and let’s discuss how we can get you started with fair synthetic data today. If you would like to learn more about fair synthetic data, read our Fairness Series!
Co-Authors: Alexandra Ebert & Daniel Soukup
In the previous part of this series, we have discussed two risks entailed in the rise of digitalization and artificial intelligence: the violation of the privacy and fairness of individuals. We have also outlined our approach to mitigate privacy and fairness risks with bias-corrected synthetic data: this allows for privacy-preserving data sharing and also aids the fair treatment of customers (data subjects) in downstream analysis and machine-learning tasks. (By the way, if you would like to experiment with fair synthetic data yourself, you can download the datasets we created at the bottom of the page.)
If you would like to dig deeper into algorithmic fairness and the potential risks in machine learning systems, we can highly recommend The Ethical Algorithm book by M. Kearns and A. Roth. For a more technical viewpoint, check out fairmlbook.org to find lecture notes, videos, and other great resources.
In this blog post, we take a deeper dive into our approach to de-bias synthetic data. For now, we focus on statistical parity as a fairness measure and show in detail the effects of our approach in two settings:
- the Adult US census data set, which is an extract of the 1994 US Census database, and
- the Compas recidivism data set that was the focus of ProPublica’s high profile machine bias study.
Read the other parts of the series:
- Part 1 - Why Bias in AI is a Problem & Why Business Leaders Should Care
- Part 2 - 10 Reasons For Bias In AI And What To Do About It
- Part 3 - We Want Fair AI Algorithms – But How To Define Fairness?
- Part 4 - Tackling AI Bias At Its Source – With Fair Synthetic Data
Statistical Parity as a Measure of Fairness
Let’s start with a quick reminder: a data set or algorithm being unfair usually refers to some kind of imbalance. A rather intuitive measure for such an imbalance is the so-called statistical or demographic parity. In mathematical terms, we can describe it as follows: consider a population that can be split into groups by a sensitive attribute S, such as gender, skin color, age or any other property. Then consider another target attribute T that contains sensitive information on the population such as income, whether or not people spent time in prison or credit history.
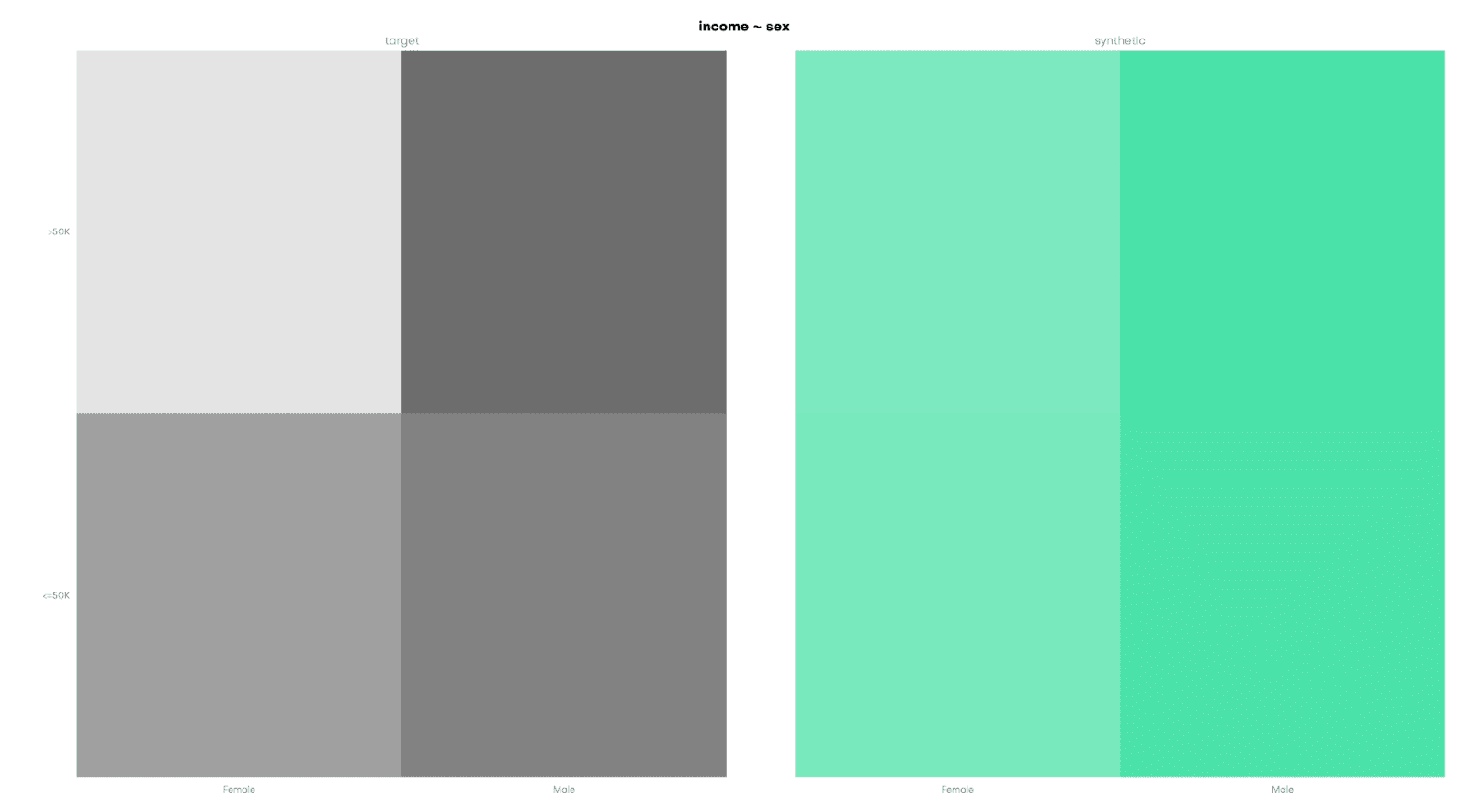
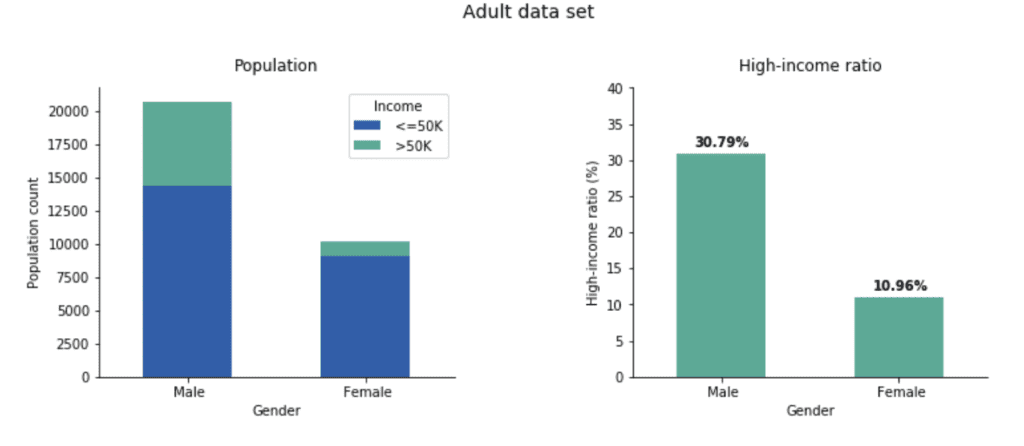
In the Adult data set, we select the sensitive attribute (S) gender, either “female” or “male”, and the target attribute (T) income, which is either “>50k” or “<=50k”.
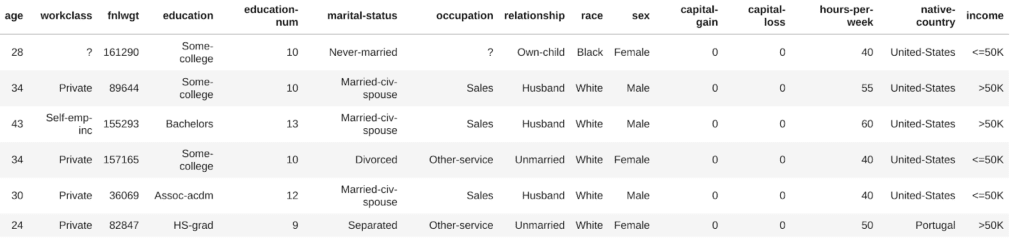
In this example, statistical parity is satisfied when the number of females that earn more than 50K divided by the total count of females equals the number of males earning more than 50K divided by the total number of males:

In other words, the probability that a randomly chosen male is a high earner should be the same as the probability of a random female being a high earner. Also, note that when these two fractions are equal for the high-income segment (“>50K”) then this automatically holds true for the low-income segment (“<=50K”) as well.
In the real world, unfortunately, the equality above does not hold true. A simple visualization of the data set reveals a strong imbalance between females and males (Fig 2).
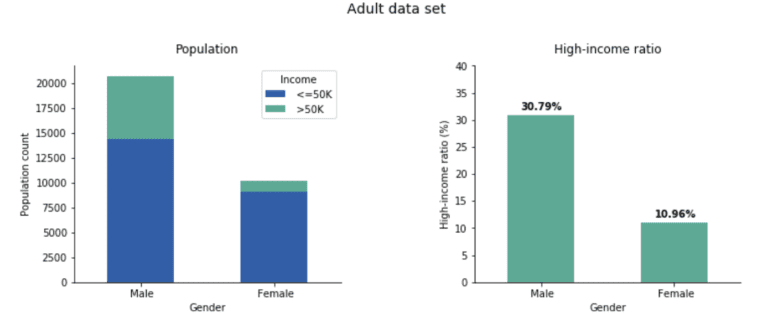
Only 10.96% of women are in the high-income range while among men, the fraction is 30.79%, almost three times higher. In the remainder of the blog post, we show how to create a fair, synthetic version of the Adult data set that removes the income gap between these two gender groups.
Though being intuitive, parity has limitations especially in the context of fair algorithmic decision making. We are aware of these shortcomings, some of which we mentioned in our fairness definitions post already, and we will discuss alternative fairness measures at the end of this blog post.
Generating a Fair Dataset
One of the first ideas to try when creating a fair data set for machine learning is to drop the sensitive column. In the presented case that’s the “sex” attribute. At first sight, this sounds like a good and easy-to-implement solution but, unfortunately, it can actually cause more harm than good. On one hand, what makes this approach fail can be so-called proxy or hidden proxy columns. Imagine we know which neighborhood a person lives in, the brand and model of the person’s mobile phone, the car this person drives, where this person buys her/his clothes, etc. Given some of the above information, we humans can make a pretty educated guess on this person’s sex, skin color, and other attributes. And since algorithms are better in analyzing patterns like this, they will definitely detect these correlations and exploit them, leading again to unfair predictions and decisions. We could actually go one step further and say that leaving the “sex” column in the data set is better for fairness because it offers a clear handle to enforce fairness constraints such as statistical parity. To give another example from criminal justice, women on average are less likely to commit future violent crimes than men with similar criminal records. So, a gender-neutral assessment can overestimate a woman’s recidivism risk.
Our synthetic data platform's community version is free to use and leverages deep neural networks to produce synthetic data. In order to generate fair synthetic data, we add a fairness constraint to the model parameter optimization during training. Sticking with the Adult data set, we penalize the violation of statistical parity within every mini-batch by increasing the training loss by a number that is proportional to the difference between the fraction of women and the fraction of men in the high-income segment. A very similar approach for training fair classifiers is described in a paper by P. Manisha and S. Gujar and an implementation can be found at Y. Shavit’s github repo.
In more general terms, adding the fairness constraint expands the objective of our software from generating accurate and private synthetic data to generating accurate, private, and fair synthetic data.
Private and Fair Synthetic Data
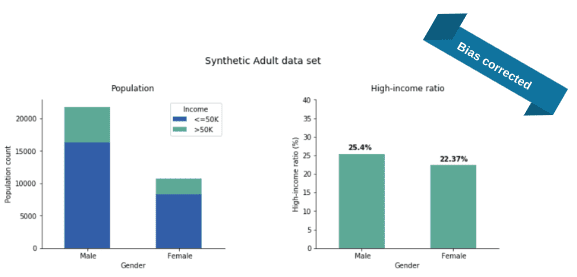
After feeding the Adult data set to our software and training it with the additional parity fairness constraint in place, we generate a synthetic fair version of the Adult data set. Once we evaluate the income distribution, we see a major change: the income gap almost disappeared (Fig 3).
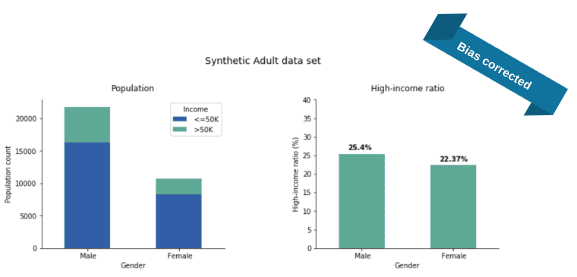
Actually, we repeated the whole process 50 times and the plotted numbers are the average ratios over these independent runs. The income-ratios slightly varied across the 50 experiments but this variance (rooted in the stochastic nature of our training and generation process) was quite small: 1.2% and 1.3% for the Male and Female ratios, respectively. As apparent from the plots, the synthesis corrected the income gap: 25% of the synthetic males are high earners (instead of the real 30%) and 22% of the synthetic females are high earners (while the original value was 11% only).
With regards to parity, it is common to compare not just the difference but the fraction of high-income male ratio to high-income female ratio (that is, we divide the two sides of the above equation). This fraction is called the disparate impact and it is an industry-standard to ask for at least 0.8, the so-called four-fifth rule. In the original data set, this fraction is roughly 10/30 = 0.33, a quite severe disparate impact violation but the bias-corrected synthetic data is at 22/25 = 0.88, well over the threshold.
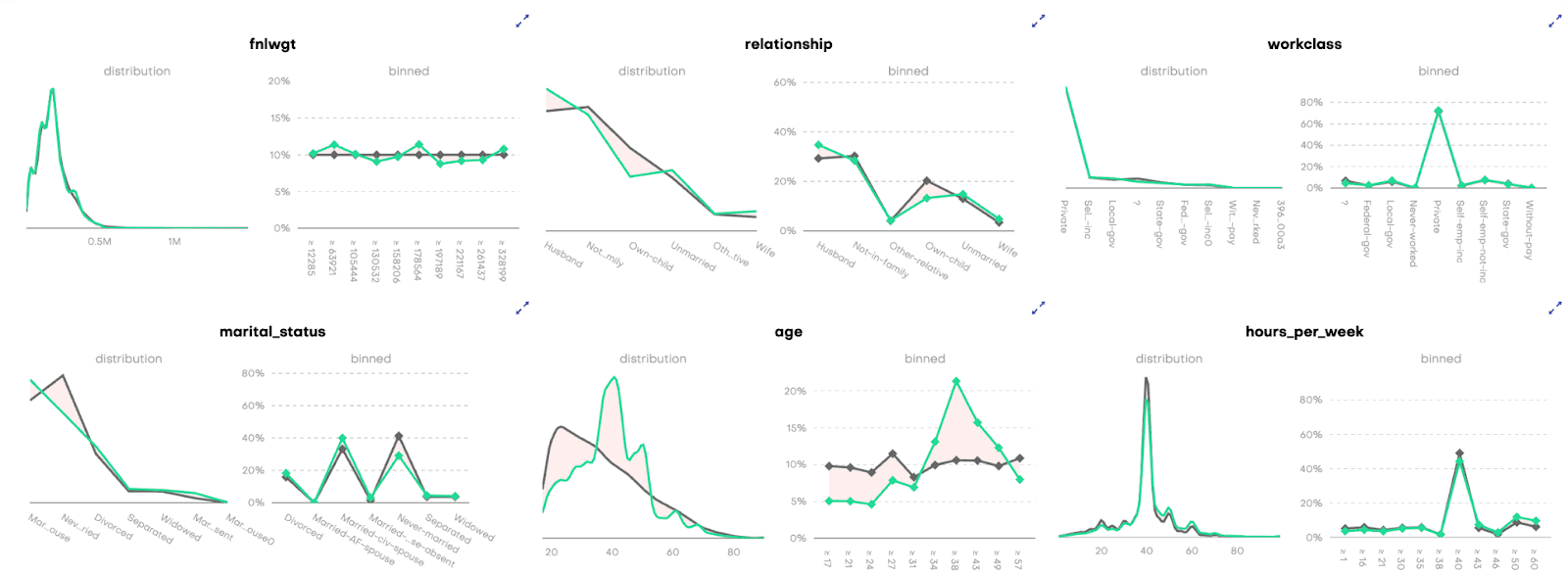
The additional parity constraint during model training does not diminish the quality and accuracy of the synthetic data. Univariate distributions of the synthetic-data attributes almost perfectly match their original counterparts (in Figure 4, we show only a selection). Please note that, while parity is modified to a large degree, both the population-wide male-to-female ratio, as well as the high-earner-to-low-earner ratios, are preserved.
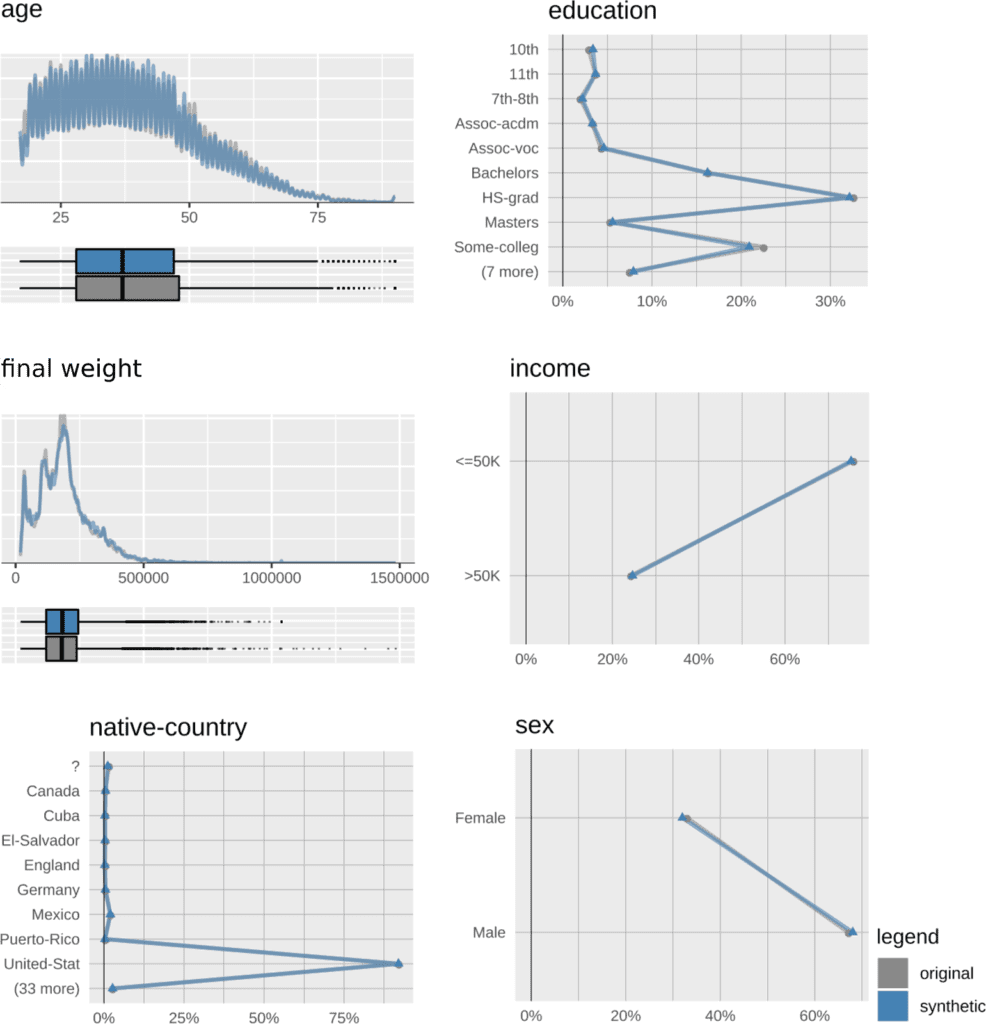
Also the bivariate correlations of the synthetic data, on first sight, seem to be in excellent agreement with the original data (Figure 5).

A closer look, however, reveals some detailed changes due to the inner workings of the fairness constraint. Given the statistical parity definition, “income” must not depend on “sex”, which means these two attributes should not be correlated.
While in the original data, there is a clear “sex”-”income” correlation (red circle in the left plot in Figure 5) this dependency is almost reduced to noise level in the fair, synthetic data (red circle in the right plot in Figure 5). Apart from the “sex”-”income” pair, no other correlation seems to be altered by applying the fairness constraint, at least not strong enough to show a visible effect on the correlation plot.
But what about proxy attributes, columns in the data set that are correlated with “sex” and “income”? Can they introduce unfairness through a backdoor, as they are not explicitly mentioned in the parity constraint? Recall that the “parity equation” (see Equation 1) contains the attributes “sex” and “income” only.
To visualize the effect of the parity constraint on proxy attributes, we add an artificial feature to the Adult data set named “proxy”. We generated this column so that it is strongly correlated with the attribute “sex”. For females, “proxy” equals to 1 in 90% of all cases and equals to 0 for the remaining 10%. For males, the percentages are swapped. Looking at this new data set, we see, first, the strong correlation between “sex” and “proxy” (the black arrow on the left-hand side plot of Figure 6). Second, as these two attributes are strongly linked, also their correlation to “income” is comparable (the red arrow on the left-hand side plot of Figure 6). Now, when we run our synthetic data solution with the fairness constraint in place on “sex” only, we find that in the fair synthetic data both correlations “sex”-”income” and “proxy”-”income” are almost reduced to noise level (the red arrow on the right-hand side plot of Figure 6). The latter finding shows that the parity constraint works as intended and accounts for (hidden) proxy attributes.

In the Adult data set, gender is not the only sensitive attribute: if we train our synthetic engine with “race” as a sensitive attribute, we get similarly impressive corrections (for this task, we used a simplified version of the data set filtering for Black/White subjects). In the original data, there are twice as many high earners in the White population than in the African American, but the ratios are almost exactly equal in our adjusted synthetic data (Figure 7).
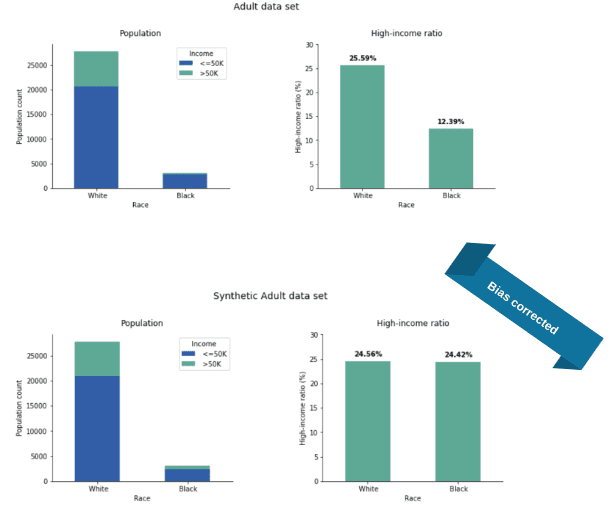
In summary, the introduction of (parity) fairness to our software solution shows very promising results. The quality and accuracy of the synthetic data remain high, the privacy of data subjects is protected, and parity-fairness is guaranteed. All these properties make private and fair synthetic data readily available for further application.
Mitigating Bias on More Than One Feature
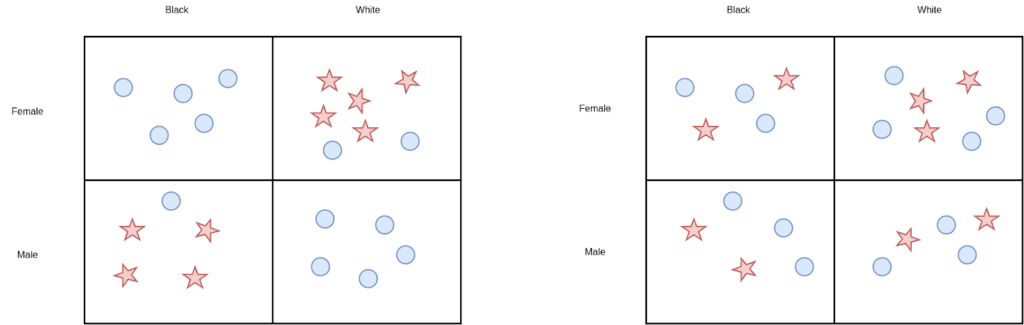
It is also a possibility to turn on the fairness loss on multiple sensitive attributes at the same time which we did for race and gender. In this case, one must be careful what ratios to optimize: if we were to simply put fairness losses independently on race and gender then the algorithm might fall into the mistake of “fairness gerrymandering”. That is, the new data set would look fair with respect to both gender and race individually, but we would see high imbalances when restricted to gender and race simultaneously (Figure 8).
Taking this into account, our solution gives synthetic data with significantly balanced high-income ratios across the four groups given by race and gender (Figure 9).
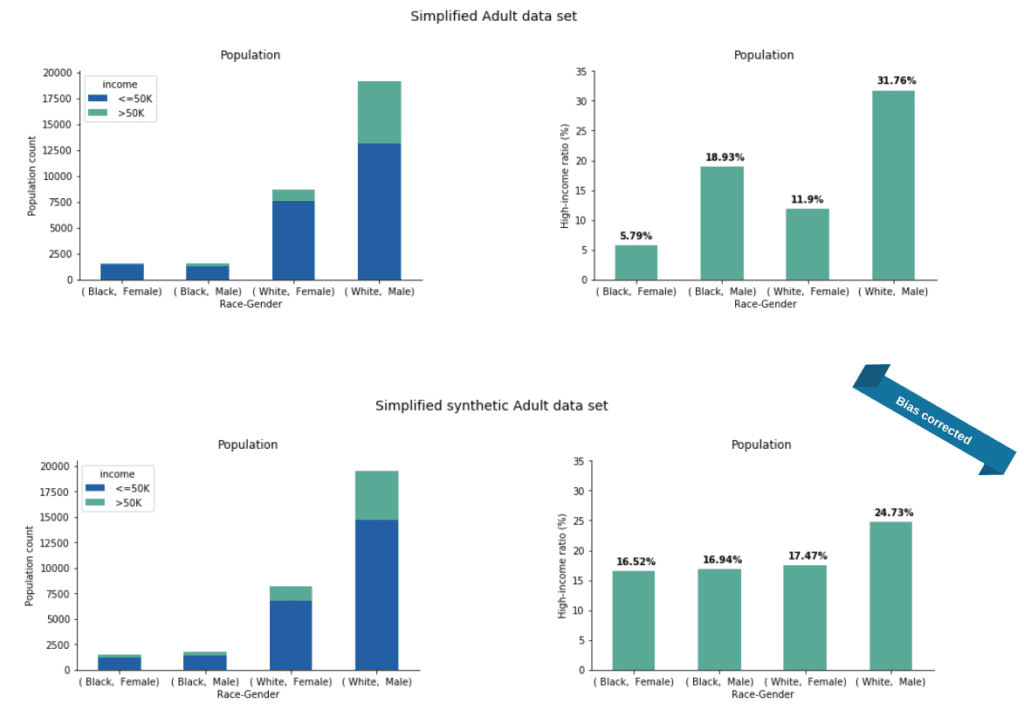
It is apparent that we did not achieve complete parity but this difference can be further lowered by giving higher weight to the fairness loss against the accuracy loss.
Fair Synthetic Data in Downstream Machine Learning Tasks
In the previous post, we introduced a scenario in which Got Big Data Company generates a fair synthetic dataset. This data set is handed to an external vendor, SmartUP AI, to develop new predictive models. As the data set is fair and synthetic, SmartUP AI does not need to take specific privacy measures nor does it need to apply any bias correction so they can work with standard, out-of-the-box models.
We demonstrate this with the Adult census data by fitting a simple linear model, logistic regression, which predicts the income level, high versus low, based on the other attributes. As we mentioned, there is no point in removing gender as an explanatory variable since the data set can contain other hidden proxies. We train two models, one on the original data set and one on the bias-corrected synthetic data. Both models are then tested on a holdout from the original data. Moreover, we repeated the model training procedure 50 times with independently generated synthetic data.
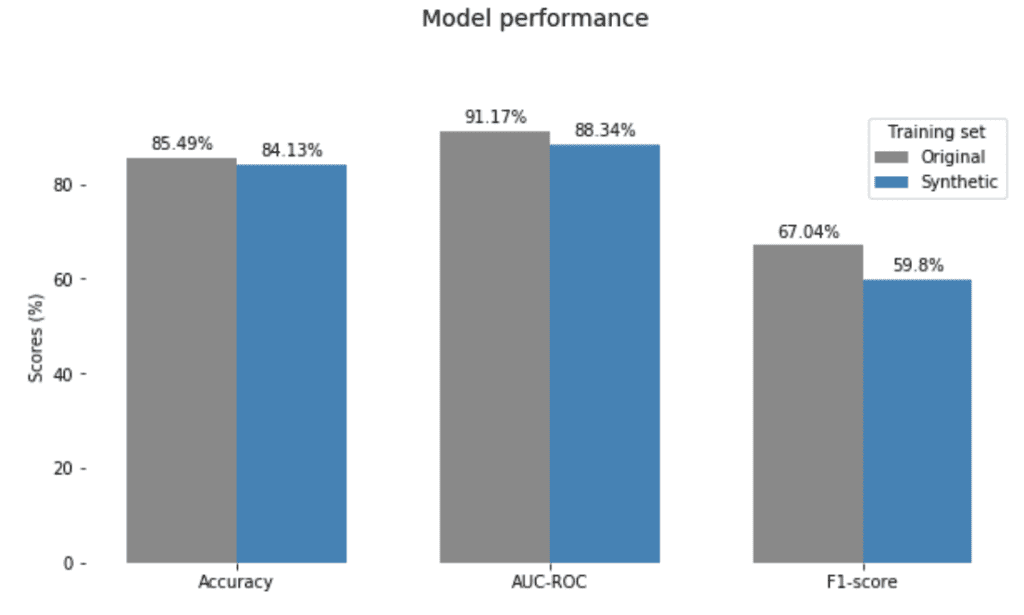
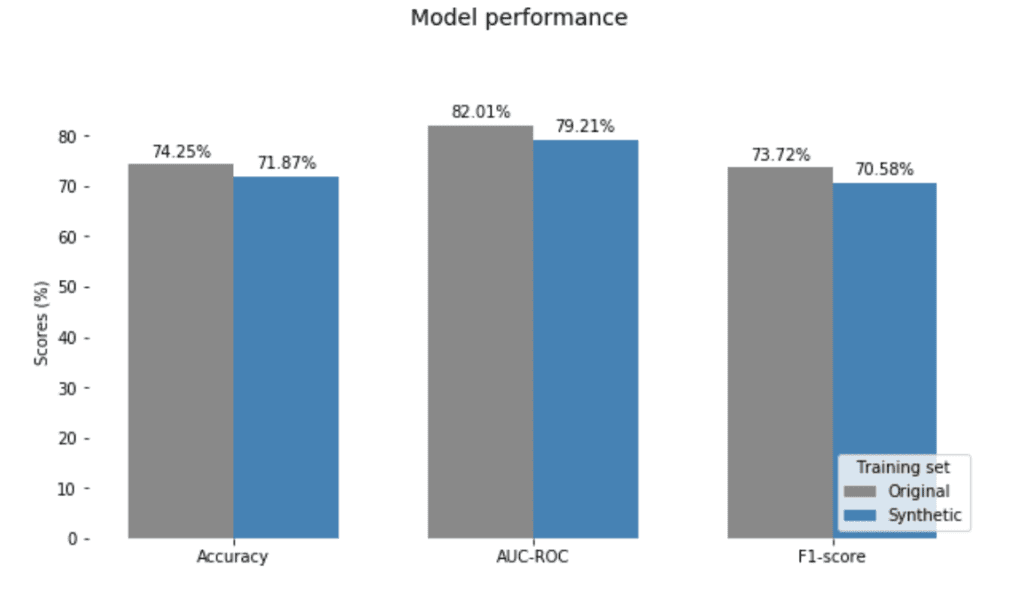
The charts in Figure 10 show the mean performance of the real and synthetic models over these experiments. The synthetically fitted models have very competitive performance and generalize well to the unseen real data. Also, we observed only minimal variance across the experiments (2%, 2% and 2.5% in Accuracy, AUC-ROC, and F1-score, respectively).
Moreover, the models trained on the synthetic data treat the classes of the sensitive attribute (gender, in this case) nearly equally. These predictive models output the probability of being high-income for any data point, so we can look at how these probabilities are distributed. Since there are more low-income samples, we expect these probabilities to be concentrated close to 0, both for females and males. However, for the model fitted on the original data, we see below that there is a much higher number of around-0 probabilities for females than males (Figure 11).
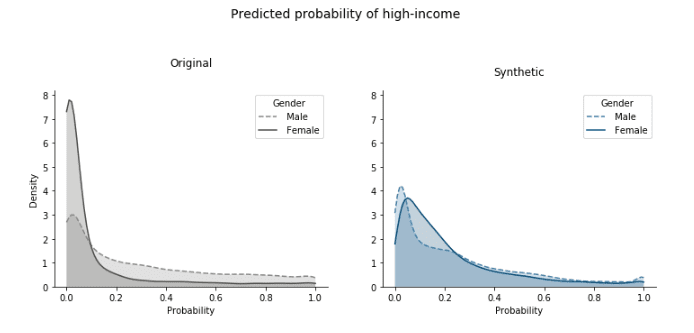
On the other hand, with the predictors trained on the synthetic data these distributions are brought very close together. This is exactly the group fairness that parity is designed to capture. The important thing to keep in mind though is that the predictive-model training itself did not involve any type of optimization to fairness and the evaluation is also on the biased original data. So this fair outcome is solely due to using bias-corrected synthetic data for the training.
Our results align with the findings of research conducted at Carnegie Mellon University into fair representations of data. We see that our fairness-constrained synthetic data solution learns to represent data points in a way that removes the dependencies between the sensitive and target attribute while preserving other relationships.
Correcting the Compas Data Set
We return briefly to the ProPublica study on algorithmic justice and the corresponding Compas data set (see our introductory fairness post). This data set contains information about defendants together with their predicted risk to re-offend, the so-called Compas score. We generate a parity-fair synthetic version of this data set with “race” as the sensitive attribute and the Compas score as the target variable. The original data set is heavily biased towards African Americans which in turn gets perfectly corrected in our synthetic data.
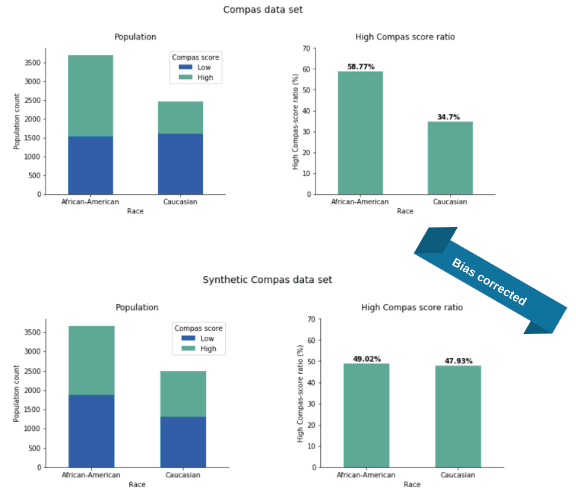
In the original Compas data set, the ratio of individuals with high Compas scores is 59% and 35% for African Americans and Caucasians, respectively. Quite impressively, our bias mitigated data reduced this gap to merely 1%, settling the values in the middle at 49% and 48%, respectively.
In the subsequent prediction task, we can achieve almost perfect equality between the predicted probabilities for high Compas score between the two classes of the sensitive attribute “race” (Figure 13).
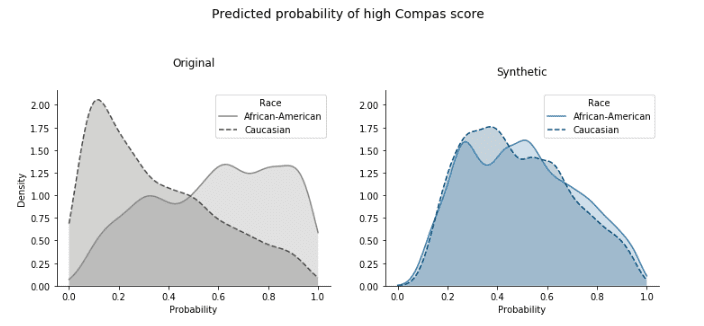
Looking at the classifier’s performance, this parity-correction comes with minimal compromise in predictive accuracy (Figure 14).
Alternative Fairness Definitions
While demographic parity is a very intuitive notion, it has certain limitations. As compared to other fairness definitions, there is a worse trade-off between satisfying parity and having high accuracy for the generated data. If your original data had a class imbalance then the parity-mitigated synthetic data or a classifier that is forced to satisfy parity cannot achieve the same level of accuracy as a predictor with no parity loss. Actually, the base-rate difference is a provable lower bound on the accuracy. Moreover, parity is a notion of group fairness, it equalizes outcomes across classes, while other approaches optimize for individual fairness focusing on treating similar individuals similarly. S. Corbett-Davies and S. Goel argue that all these approaches suffer from serious shortcomings and advocate a risk-based assessment that could better serve policymaking.
Since parity only considers the sensitive attribute and a single other variable, it is not designed to handle a situation involving both predictions and a ground-truth label (three variables all together). So, in a more nuanced approach to fairness, one aims to have a predictor model that makes the same mistakes with the same chance across the sensitive attribute classes.
Such notions include equal opportunity and equalized odds which we also tested in our synthesis process: our experiments showed that if we generate synthetic data sets with these fairness constraints then they also give rise to fair classifiers with respect to these stronger notions. We will share the details of these more technical results in a subsequent article.
Conclusions and How We Will Continue After #FairnessWeek
The notion of fairness (in particular, statistical parity) and synthetic data go together very well. Not only can we generate highly accurate synthetic data but we can also steer the generation to almost perfectly mitigate strong biases in the original data sets. The additional fairness constraint in the training loss of our generative models fine-tunes the correlation structure between attributes such that these biases are strongly reduced. Privacy and (parity) fairness are further preserved in downstream tasks: an out-of-the-box classifier model when trained on fair synthetic data makes fair predictions even on biased input.
Statistical parity has limitations, and, on a more general note, there is no concept of fairness or silver-bullet solution that is applicable to all possible use cases. While this was our last post of #FairnessWeek, we will definitely continue our work on fair synthetic data and mitigating bias in Artificial Intelligence. In an upcoming study, we will extend our approach to other fairness measures, such as equal false-positivity rate and equalized odds.
Co-Authors: Alexandra Ebert & Daniel Soukup
In the age of digitalization and the rise of artificial intelligence, more and more tasks in public and private organizations are managed or supported by computers and machine learning algorithms.
These include tasks such as data analysis, automated decision making, customer interaction services such as automated emails or chatbots, and recommendation systems. In general, we believe this is a good thing, as machine learning algorithms are fast, scalable, and can analyze way more complex data structures than humans. For example, there are studies showing that the adoption of automated underwriting in mortgage lending contributed to the increase of approval rates for minority and low-income applicants by 30% while improving the overall accuracy of default predictions.
However, machine learning algorithms typically require lots of training data and when this data contains sensitive information about real people, the stakes become extremely high. Two risks involve the violation of privacy and fairness: disclosing sensitive personal information and treating people unjustly during the decision-making process.
There are many well-documented cases of biased decision making that triggered an ongoing discussion about algorithmic fairness. A famous example is Google’s hate speech-detection algorithm that discriminated against African Americans. Researchers at the University of Washington found, that the algorithm was more likely to label their tweets as “hateful” or “offensive”. Not only was it biased against people of color, but also, as another study demonstrated, against well-known drag queens. Another case of bias in Artificial Intelligence was Amazon’s HR algorithm. The system was fed with 10 years worth of records of previous – and predominantly male – Amazon employees and thereby learned that being female poorly correlated with being a suitable candidate for a job at the tech company.
Now, in the cases above, algorithms systematically discriminate against a group based on its gender, race, or sexual orientation. If not addressed, these systemic biases end up in data sets that decision-making algorithms are trained on. Subsequently, the biased algorithms make unfair decisions, perpetuating, and actually amplifying the biases in our society.
We at MOSTLY AI believe in the positive powers of artificial intelligence to foster research and innovation. We will demonstrate that bias-corrected synthetic data can address both privacy and fairness concerns to allow for utilizing and democratizing big data assets while keeping the risks at a minimum. The current post will give a high-level overview of our work and in post 5 of our Fairness Series, we will discuss more technical aspects of our results as well as make our fair synthetic data sets available.
Read the other parts of the series:
- Part 1 - Why Bias in AI is a Problem & Why Business Leaders Should Care
- Part 2 - 10 Reasons For Bias In AI And What To Do About It
- Part 3 - We Want Fair AI Algorithms – But How To Define Fairness?
- Part 5 - Diving Deep Into Fair Synthetic Data Generation
From Privacy Protection To Promoting Fairness in AI
Our synthetic data platform, enables organizations to generate highly accurate, statistically representative synthetic data at scale such as synthetic customer records along with purchase histories. The software functions as an unlimited source of artificial individuals who have interacted with your business the same way as real people did historically. The synthetic data, however, can be shared safely without privacy concerns since these artificial people do not really exist and the privacy of your actual customers, the real data subjects, remains protected.
Synthetic data generation doesn’t need to stop at privacy protection though. As we generate the data from scratch, we can model and shape it to fit different needs. A beautiful example of this is NVIDIA’s styleGAN, where a conditional generation of synthetic images allows for adding smiles or sunglasses to faces, or changing hair and skin color.
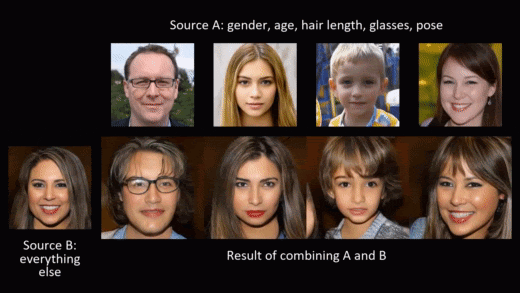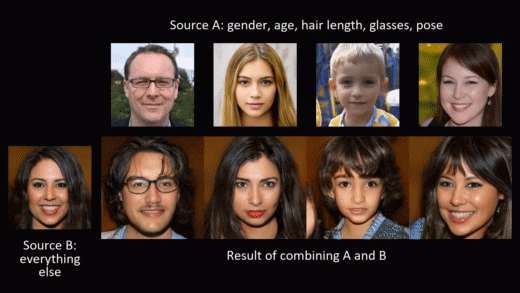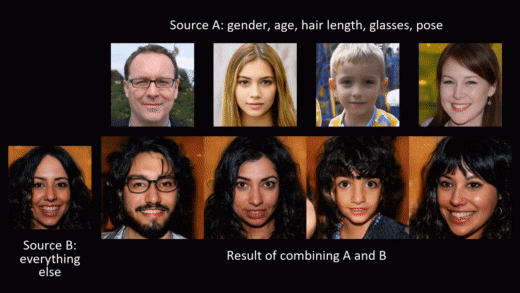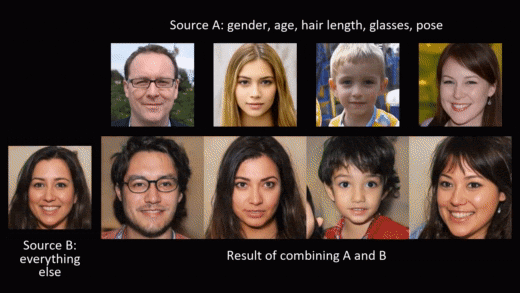
In this blog post, we want to leverage the possibility of modeling and shaping synthetic data to mitigate the second risk mentioned in the introduction: violation of fairness. The result is fair synthetic data that is fully anonymous and de-biased (in accordance with a specific fairness definition).
To Get Fair Synthetic Data You Need To Start With A Fairness Definition
Imagine a perfect world without any biases and discriminations, where attributes such as skin color or sex do not influence people’s lives either in a good nor a bad way. In such a world, the fraction of women among top management positions would equal those of men. Similarly, the fraction of women earning more than $50,000 per year would equal that of men and the fraction of African-Americans in US prisons would be the same as the fraction among Caucasians. This property comes under the name of statistical or demographic parity. The plot below shows how demographic parity is violated in the Adult US census data set with respect to gender and income.
Statistical parity is a very intuitive fairness measure and, in a perfect world with equal opportunities for everybody, it would be satisfied. There are many other, equally viable metrics but keep in mind that there is no single equation or approach that will perfectly fit vastly different scenarios. To truly address and derive actionable insight against bias, one needs a deep understanding of the underlying issues in each use-case. What we developed here is a flexible framework to generate synthetic data that satisfies fairness with respect to a given metric, focusing on parity for now and exploring other measures in a subsequent study.
How To Create A Fair Synthetic Dataset?
There are three points in the machine learning life cycle where you can mitigate bias: at the source, by changing your input data; during the modeling phase by using additional fairness constraints; and as a post-processing step, by revising the algorithm’s decisions in favor of a sensitive group. Naive data-level techniques, such as oversampling methods, have the risk of skewing important data distributions when mitigating imbalances. Our approach is a sort of hybrid, using fairness constraints on a generative model to produce fair synthetic data.
Now, the main objective of our Synthetic Data Platform is to generate new, synthetic data that is as accurate and as representative as the original data set. Under the hood, the software leverages deep neural networks that are trained to optimize an accuracy loss: this simply measures how well our model is reproducing the statistical distributions of the real data. Now, in order to get fair data, we can add a fairness constraint to this optimization step. To stick with the income example, for every mini-batch of data that enters during training, we penalize the violation of statistical parity by a number that is proportional to the difference between the fraction of women and the fraction of men in the high-income segment. We then adapt the model parameters with the objective to minimize both the accuracy loss and fairness constraint.
Using this approach, we successfully removed the income inequality with respect to gender from the synthetic version of the Adult data set. We did this with very little compromise on other aspects of data accuracy: for example, you can see we preserved the original Male/Female ratio perfectly.
How Organizations Can Benefit From Private And Fair Synthetic Data
One of our main motivations in working on fair synthetic data generation is the following scenario: imagine Got Big Data Company, a conscientious organization that aims to develop a new predictive model. To do so, they ask the help of a 3rd party vendor, SmartUp AI, and until recently, such collaborations involved allowing access to their sensitive database. Moreover, if Got Big Data Company wanted to address data bias then it required rather special know-how on the developer’s side. Here enters fair synthetic data: Got Big Data Company first generates a synthetic and hence private version of their original data set which is also fair with respect to the modeling task at hand. Next, the vendor, SmartUp AI, develops the predictive model on the synthetic data, just as they would for any task without having to be concerned about bias correction on their end. Then, these models are handed back to Got Big Data Company for use on actual customer data.
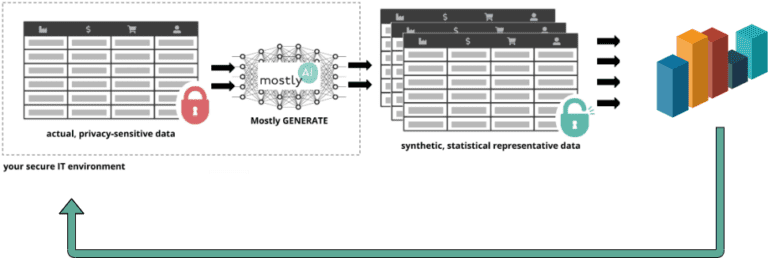
using the synthetic data ⇒ evaluate and deploy on real data.
We find that out-of-the-box predictive models trained on fair synthetic data treat the classes of the sensitive attribute near equally (e.g., female and male). This fair outcome is solely due to using parity-corrected synthetic data, there are no fairness constraints of the predictive models. In the next article, we will release our parity-corrected synthetic data and dive into the technical details of our approach and analysis of the generated data.
Conclusions
There are many inherent risks in automated decision making and in the use of data sets that do not reflect the world we strive to live in. Historical and measurement biases skew predictive models which in turn affect millions of people who are applying for loans or submitting job applications. As data scientists, engineers, and business leaders, we are responsible to address these issues as best as we can. At Mostly AI, we offer a two-in-one tool to utilize data sets that are often sensitive and biased at the same time. First, our fair synthetic data can be safely shared without leaking personal information. Second, having addressed bias-mitigation at the synthetic data generation phase, it enables organizations to utilize existing analytics and modeling pipelines without the need for costly anti-discrimination modifications. To learn more about how fair synthetic data is generated, continue with part 5 of our Fairness Series.
“One of the major challenges in making algorithms fair lies in deciding what fairness actually means,” said Dr. Chris Russell, who is leading the safe and ethical AI group at the Alan Turing Institute, in an interview with Wired. “Trying to understand what fairness means, and when a particular approach is the right one to use is a major area of ongoing research.” Fairness is a vastly complex concept and as people tend to have different values their interpretations of fairness differ as well. A mother might think it is fair if both of her children receive two pieces of chocolate. But instead of having two happy kids eating their chocolate, they start to quarrel. The older ones’ argument? He is much bigger and thus should have received a piece more than his brother. The little one’s opinion? It was him who helped dad do the dishes yesterday evening – therefore he is the one deserving more chocolate. Read the other parts of the series:- Part 1 - Why Bias in AI is a Problem & Why Business Leaders Should Care
- Part 2 - 10 Reasons For Bias In AI And What To Do About It
- Part 4 - Tackling AI Bias At Its Source – With Fair Synthetic Data
- Part 5 - Diving Deep Into Fair Synthetic Data Generation
Equal Treatment Versus Equal Access
In the private as well in the business context we oftentimes strive to achieve fairness by treating everybody exactly the same. An equal amount of chocolate. An equal amount of time to finish a test in school and – in an ideal world – also equal pay regardless of gender or race. The concept behind this is called equality. But what it fails to take into account is that not every one of us starts from the same place and that some might need different support than others do. Imagine three people of divergent height trying to get to the beautifully ripe, red apples on an apple tree. If you were to give a small pedestal to everyone, it would not really improve the situation for the smaller individuals:
Fair AI Requires A Mathematical Fairness Definition
In order to build fair machine learning systems, we need to precisely define and quantify what we mean by a fair outcome. There are several mathematical definitions that do just that and on a high level, these notions fall into two categories: group and individual fairness. Group fairness and parity constraints aim to achieve the same outcomes across different demographics, or more generally, a set of protected population classes. In other words, the population that receives a given assessment by the algorithm (let it be positive or negative) should reflect the whole population and its demographics. We can furthermore require that the types of mistakes the model makes and the severity of these errors should be evenly distributed across the population. These requirements are intuitive, easily applied across domains, and hence are the most widely used, and studied. At the same time, being fair with respect to parity can seem highly unfair from a single individual’s viewpoint. So individual fairness advocates treating similar individuals similarly. The ”Fairness through Awareness” approach is built on first defining a task-specific similarity measure between pairs of data subjects and using that to quantify how close predictions a randomized algorithm should give on two individuals. There are ways to combine group and individual fairness, such as learning fair representations (abstract transformations of the data points into high-dimensional numeric vectors) that could be used in downstream modeling tasks. Yet another approach develops individual risk scores and uses a thresholding policy to treat similarly risky individuals the same way. The list of fairness definitions goes on and on, but in all cases, one aims to find the most accurate model that still satisfies a given fairness constraint. But who exactly selects the protected classes and the requirements that should be met? We know that certain parity requirements are impossible to satisfy simultaneously. On the other hand, finding the right metric and risk scores for individual assessments can be very challenging and needs to be done on a case-by-case basis. As Hanna Wallach from Microsoft Research puts it “[…] issues relating to fairness and machine learning are fundamentally socio-technical, and they are not going to be addressed by computer scientists or developers alone”. So it is of utmost importance to include a diverse set of stakeholders in these decisions with an insight into the whole decision-making process.Demographic Parity – A Group-Fairness Measure
For defining and explaining in more detail group-fairness measures, let’s revisit David Weinberger’s tomato factory example. In this hypothetical factory, tomatoes are processed to end up in spaghetti sauce. An integral part of the factory is a machine learning algorithm that automatically analyzes tomatoes on the conveyor belt and classifies them into fresh and bad (or rotten) tomatoes. Fresh tomatoes are transferred into the “Acceptable” bin and ultimately end up in the spaghetti sauce, rotten tomatoes end up in the “Discard” bin and are thrown away. Consider there exist only two kinds of tomatoes worldwide: 80% of all tomatoes are red tomatoes and 20% of them are yellow. Apart from their appearance, there is no difference between red and yellow tomatoes. They taste the same, have the same shape, grow equally fast, and need equal amounts of care. They also have the same storage life which means they start to rot after the same time span. One of the most intuitive definitions of fairness is demographic (or statistical) parity. In case the tomato sorting machine learning algorithm satisfies demographic parity, we expect about 80% of red and 20% of yellow tomatoes within the “Acceptable” bin in the spaghetti factory. In other words, we expect the fractions of red and yellow tomatoes in the global population to be reflected in the “favorable” group of “Acceptable” tomatoes in the factory. An unfair algorithm, that “favors” red tomatoes and discriminates against yellow ones, would put more than 80% of red tomatoes in the “Acceptable” bin. In this example, demographic parity is a perfectly fine measure. However, as Dwork and co-workers pointed out, the notion of demographic parity has shortcomings and needs to be applied with great care. Imagine that our two hypothetical tomato sorts do differ in that yellow tomatoes tend to rot a little faster than red ones on their way to the factory. In that case, the fraction of red tomatoes in the “Acceptable” bin should be larger than 80% as more of the yellow tomatoes need to be discarded. Enforcing demographic parity in this scenario leads to two problems. First, it actually introduces some unfairness. To achieve demographic parity, say for a one-day batch of tomatoes processed in the factory, the algorithm needs to put some rotten yellow tomatoes into the “Acceptable” bin while, at the same time, prevent some of the perfectly fresh red tomatoes from going in there. The second shortcoming is related to the tension between accuracy and fairness. If the tomato sorting algorithm was what is called a perfect classifier (in practice a perfect classifier does not exist but for the sake of the argument let’s consider it does), it would not make any mistakes and place all tomatoes in the correct bin. As such, this algorithm is fair as it treats every single tomato the way the tomato “deserves”. Enforcing demographic parity on this perfect classifier would actually detune it – which clearly shows that there is a misalignment between optimizing a classifier and satisfying demographic parity. Therefore, demographic parity usually leads to larger costs in accuracy and, therefore, costs an organization more money than other fairness measures.Equality of False-negatives And Equalized Odds
The core problem of demographic parity is that it does not take into account the ground truth. It does not care whether or not tomatoes are “Acceptable”, it just requires the fractions of red and yellow tomatoes in the global population being represented in the “Acceptable” bin. There is a group of fairness measures that do take into account the ground truth by, for example, balancing or equalizing the errors the sorting algorithm makes for both sorts of tomatoes. One of the simplest examples in this context is the so-called equality of false-negatives measure that enforces constant false-negative rates across groups. In our tomato example, this means that fresh tomatoes – irrespective of their color – have the same probability of falsely ending up in the “Discard” bin. This measure only amends the errors made in the group of fresh tomatoes as only they can falsely end up in the “Discard” bin. An even stronger fairness notion that also mitigates errors in the group of rotten tomatoes is called equalized odds. It requires constant false-negative as well as true-negative rates across groups. This means that also the chances for rotten tomatoes ending up in the “Discard” bin is equal for red and yellow tomatoes. One big advantage of these types of fairness measures is that they allow for perfect decisions. For a perfect classifier, the false-negative and true-negative rates across all groups are 0% and 100%, respectively. This does not mean that the accuracy of a real-world classifier is not limited by an additional fairness constraint but it shows that, for example, equalized odds is usually better aligned with optimization than demographic parity.The Accuracy Versus Fairness Trade-Off
Fairness always comes at a cost: as we put an additional constraint on the model, we introduce a trade-off with accuracy. This is not a new phenomenon and a stark example relates to a fatal Uber accident in Tempe, Arizona. The autonomous vehicle system detected the pedestrian in time to stop but the developers had tweaked the emergency braking system in favor of not braking too much, balancing a trade-off between jerky driving and safety. Going back to bias, when we compare a model that maximizes total revenue, a fairness constrained model will probably promise less profit. You can explore these concepts with an interactive threshold classifier, including demographic parity and equal opportunity (that is, equal true positive rates), in a post from Google Research. By setting various global or group aware thresholds for giving out hypothetical loans, you can see how the bank’s profit and the distributions of loans across the population changes.