Data governance is a data management framework that ensures data is accurate, accessible, consistent, and protected. For Chief Information Officers (CIOs), it’s also the strategic blueprint that communicates how data is handled and protected across the organization.
Governance ensures that data can be used effectively, ethically, and in compliance with regulations while implementing policies to safeguard against breaches or misuse. As a CIO, mastering data governance requires a delicate balance between maintaining trust, privacy, and control of valuable data assets while investing in innovation and long-term business growth.
Ultimately, successful business innovation depends on data innovation. CIOs can build a collaborative, innovative culture based on data governance where every executive stakeholder feels a closer ownership of digital initiatives.
Partnerships for data governance: the CIO priority in 2024
In 2024, Gartner forecasts that CIOs will be increasingly asked to do more with less: with tighter budgets and a watchful eye on efficiency needed to meet growing demands around digital leadership, delivery, and governance.
CIOs find themselves at a critical moment that requires managing a complex digital landscape and operating model and taking responsibility and ownership for technology-enabled innovation around data, analytics, and artificial intelligence (AI).
These emerging priorities demand a new approach to data governance. CIOs and other C-suite executives must rethink their collaboration strategies. By tapping into domain expertise and building communities of practice, organizations can cut costs and reduce operational risks. This transformation helps reposition CIOs as vital strategic partners within their organizations.
Among the newest tools for CIOs is AI-generated synthetic data, which stands out as a game-changer. It sparks innovation and fosters trusted relationships between business divisions, providing a secure and versatile base for data-driven initiatives. Synthetic data is fast becoming an everyday data governance tool used by AI-savvy CIOs.
What is AI-generated synthetic data?
Synthetic data is created using AI. It replicates the statistical properties of real-world data but keeps sensitive details private. Synthetic data can be safely used instead of the original data — for example, as training data for building machine learning models and as privacy-safe versions of datasets for data sharing.
This characteristic is invaluable for CIOs who manage risk and cybersecurity, work to contract with external parties for innovation or outsourced development, or lead teams to deploy data analytics, AI, or digital platforms. This makes synthetic data a tool to transform data governance throughout organizations.
Synthetic data can be safely used instead of the original data—for example, as training data for building machine learning models and as privacy-safe versions of datasets for data sharing.
Synthetic data use cases are far-reaching, particularly in enhancing AI models, improving application testing, and reducing regulatory risk. With a synthetic data approach, CIOs and data leaders can drive data democratization and digital delivery without the logistical issues of data procurement, data privacy, and traditionally restrictive governance controls.
Synthetic data is an artificial version of your real data
Synthetic data is NOT
mock data
Synthetic data is smarter than data anonymization
Three CIO strategies for improved delivery with synthetic data
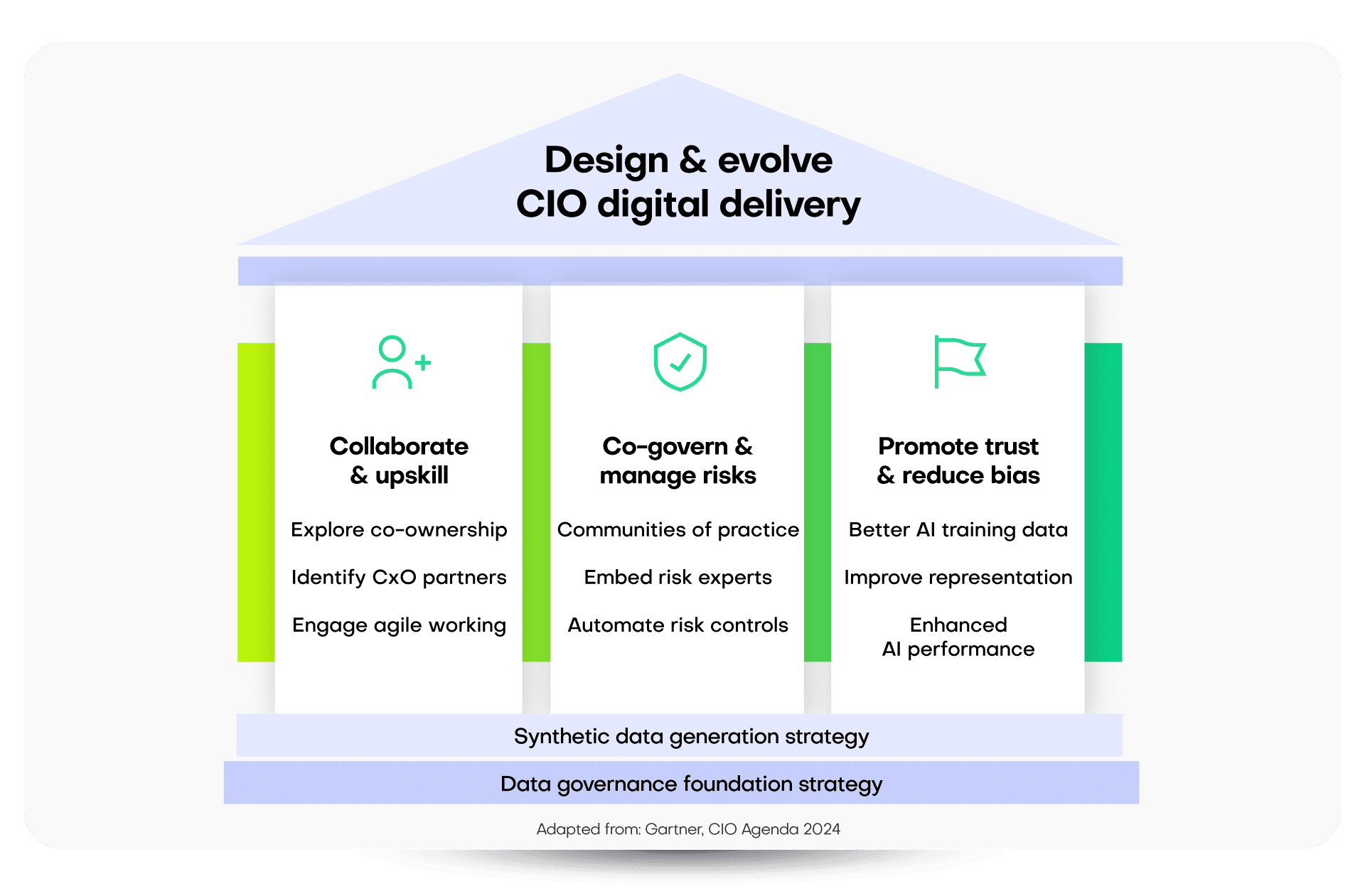
To understand the impact of synthetic data on data governance, consider the evolving role of CIOs:
- Traditional Role: 55% of CIOs surveyed maintain complete control over their digital and technical domains.
- Shift to Partnership: Conversely, 12% of CIOs now share responsibilities for digital delivery, embracing equal partnerships with their business counterparts.
The real surprise from Gartner’s findings comes from the actual outcomes of these reported digital projects, with a stark, inverse relationship between pure CIO ownership and the ability to meet or exceed project targets. Indeed, only 43% of digital initiatives meet this threshold when CIOs are in complete control, versus 63% for projects where the CIO co-leads delivery with other CxO executives.
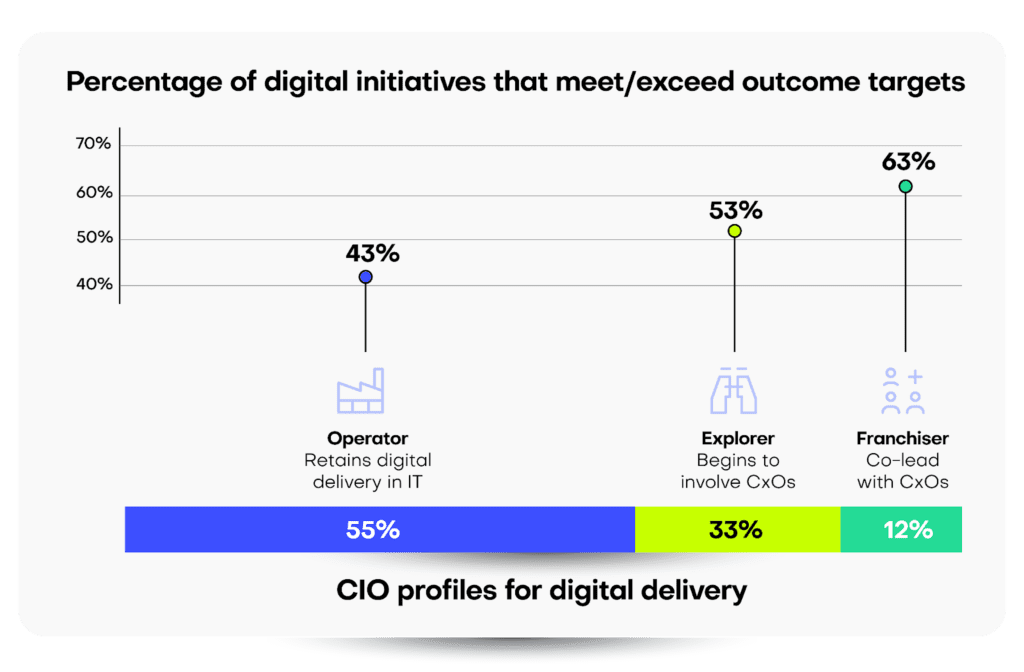
When CIOs retain full delivery control, only 43% of digital initiatives meet or exceed their outcome targets.
So, how can CIOs leverage synthetic data to drive successful business innovation across the enterprise? What steps should a traditional Chief Information Officer take to move from legacy practices to an operating model that shares leadership, delivery, and data governance?
Strategy 1: Upskilling with synthetic data
Enhancing collaboration between CIOs and business leaders
As business and technology teams work more closely together to develop digital solutions, synthetic data can bridge the gap between these groups.
To educate and equip business leaders with the skills they need to co-lead digital initiatives, there are shared challenges to overcome. Pain points are no longer simply an “IT issue,” and new, agile ways of working are needed that share responsibility between previously siloed teams.
In these first steps, synthetic data can feel like uncharted territory, with great opportunities to democratize data across the organization and recreate real-world scenarios without compromising privacy or confidentiality.
As business and technology teams work more closely together to develop digital solutions, synthetic data can bridge the gap between these groups, offering safe and effective development and testing environments for new platforms or applications or providing domain experts with valuable insights without risking the underlying data assets.
Strategy 2: Risk management through synthetic data
Creating safe, collaborative spaces for cross-functional teams
Synthetic data alleviates the risk typically associated with sharing sensitive information, while enabling partners access to the depth of data required for meaningful innovation and delivery.
A shared responsibility model democratizes digital technology delivery, with synthetic data serving as common ground for various CxOs to collaborate on business initiatives in a safe, versatile environment.
Communities of practice (CoPs) ensure that autonomy is balanced with a collective feedback structure that can collect and centralize best practices from domain experts without overburdening a project with excessive bureaucracy.
This approach can also extend beyond traditional organizational boundaries—for example, contracting with external parties. Synthetic data alleviates the risk typically associated with sharing sensitive information (especially outside of company walls) while enabling partners access to the depth of data required for meaningful innovation and delivery.
Strategy 3: Cultural shifts in AI delivery
Using synthetic data to promote ethical AI practices
Feeding AI models better training data leads to more precise personalization, stronger fraud detection capabilities, and enhanced customer experiences.
Business demand for AI far outstrips supply on CIOs’ 2024 roadmaps. Synthetic data addresses this challenge by:
- Promoting Trust: Synthetic data allows precise control over its generation process. This enables analysts to investigate outlier data points thoroughly. Additionally, it aids data scientists in explaining and stress-testing AI models to guarantee fair representation and consistent reliability for diverse use cases.
- Reducing Bias: Synthetic data generation can rebalance data distribution across data categories without losing integrity or detail.
- Enhanced Performance: Feeding AI models better training data leads to more precise personalization, robust fraud detection capabilities, and improved customer experiences.
However, adopting synthetic data in co-led teams isn’t just a technical approach; it’s cultural, too. CIOs can lead from the front and underscore their commitment to social responsibility by promoting ethical data practices to challenge data bias or representation issues. Shlomit Yanisky-Ravid, a professor at Fordham University’s School of Law, says that it’s imperative to understand what an AI model is really doing; otherwise, we won’t be able to think about the ethical issues around it. “CIOs should be engaging with the ethical questions around AI right now,” she says. “If you wait, it’s too late.”
The data governance journey for CIOs: From technology steward to C-suite partner
A successful digital delivery operating model requires a rethink in the ownership and control of traditional CIO responsibilities. Who should lead an initiative? Who should deliver key functionality? Who should govern the resulting business platform?
The results from Gartner’s survey provide some answers to these questions. They point clearly to the effectiveness of shared responsibility — working across C-suite executives for delivery versus a more siloed approach.
Here’s how CIOs can navigate this journey:
- Encourage experimentation: Build a culture that embraces synthetic data to achieve rapid prototyping and iterative feedback for digital delivery.
- Bridge the IT-Business divide: Use synthetic data to democratize data and share digital delivery responsibilities across the C-suite.
- Expand collaboration: When data privacy or intellectual property concerns restrict data sharing, synthetic data can enable collaboration, allowing for innovation or external partnerships without increased risks.
Ultimately, successful business innovation depends on data innovation. CIOs can build a collaborative, innovative culture based on data governance where every executive stakeholder feels a closer ownership of digital initiatives.
Synthetic data enables different departments to innovate without direct reliance on overburdened IT departments. When real-world data is slow to provision and often loaded with ethical or privacy restrictions, synthetic data offers a new approach to collaboration and digital delivery.
With these strategic initiatives on the corporate agenda for 2024 and beyond, CIOs must find new and efficient ways to deliver value through partnerships while building stronger strategic relationships between executives.
Advancing data governance initiatives with synthetic data
For CIOs ready to take the next step, embracing synthetic data within a data governance strategy is just the beginning. Discover more about how synthetic data can revolutionize your enterprise!
Get in touch for a personalized demo
The European Union’s Artificial Intelligence Act (“AI Act”) is likely to have a profound impact on the development and utilization of artificial intelligence systems. Anonymization, particularly in the form of synthetic data, will play a pivotal role in establishing AI compliance and addressing the myriad challenges posed by the widespread use of AI systems.
This blog post offers an introductory overview of the primary features and objectives of the draft EU AI Act. It also elaborates on the indispensable role of synthetic data in ensuring AI compliance with data management obligations, especially for high-risk AI systems.
Notably, we focus on the European Parliament’s report on the proposal for a regulation of the European Parliament and the Council, which lays down harmonized rules on Artificial Intelligence (the Artificial Intelligence Act) and amends certain Union Legislative Acts (COM(2021)0206 – C9-0146/2021 – 2021/0106(COD)). It's important to note that this isn't the final text of the AI Act.
The first comprehensive regulation for AI compliance
The draft AI Act is a hotly debated legal initiative that will apply to providers and deployers of AI systems, among others. Remarkably, it is set to become the world's first comprehensive mandatory legal framework for AI. This will directly impact researchers, developers, businesses, and citizens involved in or affected by AI. AI compliance is a brand new domain that will transform the way companies manage their data.
The choice: AI compliance or costly consequences
Much like the GDPR, failure to comply with the AI Act's obligations can have substantial financial repercussions: maximum fines for non-compliance under the draft AI Act can be nearly double those under the GDPR. Depending on the severity and duration of the violation, penalties can range from warnings to fines of up to 7% of the offender's annual worldwide turnover.
Additionally, national authorities can order the withdrawal or recall of non-compliant AI systems from the market or impose temporary or permanent bans on their use. AI compliance is set to become a serious financial issue for companies doing business in the EU.
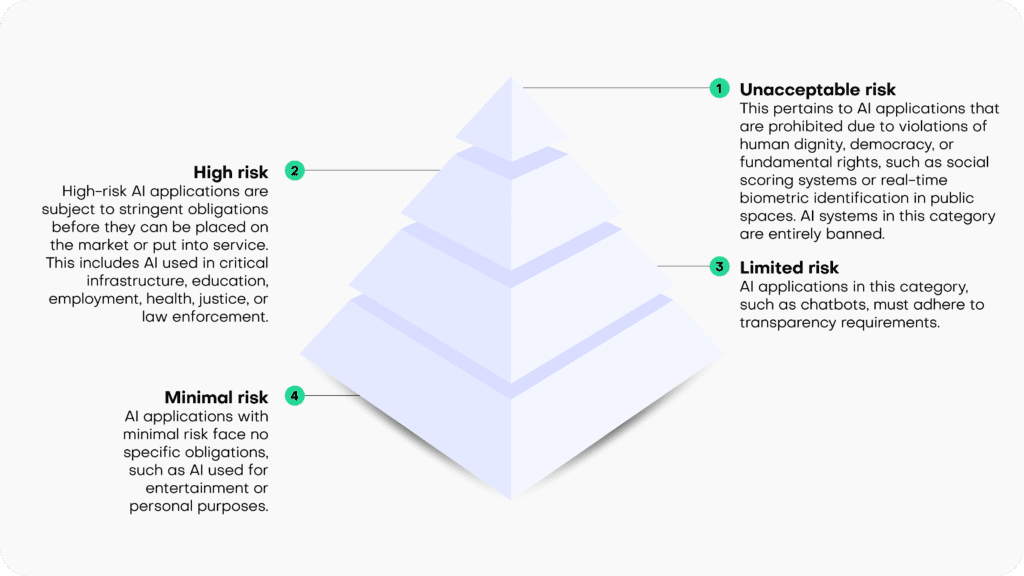
Risk-based classification
The draft EU AI Act operates on the principle that the level of regulation should align with the level of risk posed by an AI system. It categorizes AI systems into four risk categories:
- Unacceptable risk: This pertains to AI applications that are prohibited due to violations of human dignity, democracy, or fundamental rights, such as social scoring systems or real-time biometric identification in public spaces. AI systems in this category are entirely banned.
- High risk: High-risk AI applications are subject to stringent obligations before they can be placed on the market or put into service. This includes AI used in critical infrastructure, education, employment, health, justice, or law enforcement.
- Limited risk: AI applications in this category, such as chatbots, must adhere to transparency requirements.
- Minimal risk: AI applications with minimal risk face no specific obligations, such as AI used for entertainment or personal purposes.
Synthetic solutions for AI compliance
The draft AI Act focuses its regulatory efforts on high-risk AI systems, imposing numerous obligations on them. These obligations encompass ensuring the robustness, security, and accuracy of AI systems. It also mandates the ability to correct or deactivate the system in case of errors or risks, as well as implementing human oversight and intervention mechanisms to prevent or mitigate harm or adverse impacts, as well as a number of additional requirements.
Specifically, under the heading “Data and data governance”, Art. 10 sets out strict quality criteria for training, validation and testing data sets (“data sets”) used as a basis for the development of “[h]igh-risk AI systems which make use of techniques involving the training of models with data” (which likely encompasses most high-risk AI systems).
According to Art 10(2), the respective data sets shall be subject to appropriate data governance and management practices. This includes, among other things, an examination of possible biases that are likely to affect the health and safety of persons, negatively impact fundamental rights, or lead to discrimination (especially with regard to feedback loops), and requires the application of appropriate measures to detect, prevent, and mitigate possible biases. Not surprisingly, AI compliance will start with the underlying data.
Pursuant to Art 10 (3), data sets shall be “relevant, sufficiently representative, appropriately vetted for errors and as complete as possible in view of the intended purpose” and shall “have the appropriate statistical properties […]“.
Art 10(5) specifically stands out in the data governance context, as it contains a legal basis for the processing of sensitive data, as protected, among other provisions, by Art 9(1) GDPR: Art 10(5) entitles high-risk AI system providers, to the extent that is strictly necessary for the purposes of ensuring negative bias detection and correction, to exceptionally process sensitive personal data. However, such data processing must be subject to “appropriate safeguards for the fundamental rights and freedoms of natural persons, including technical limitations on the re-use and use of state-of-the-art security and privacy-preserving [measures]“.
Art 10(5)(a-g) sets out specific conditions which are prerequisites for the processing of sensitive data in this context. The very first condition, as stipulated in Art 10(5)(a) sets the scene: the data processing under Art 10 is only allowed if its goal, namely bias detection and correction “cannot be effectively fulfilled by processing synthetic or anonymised data”. Conversely, if an AI system provider is able detect and correct bias by using synthetic or anonymized data, it is required to do so and cannot rely on other “appropriate safeguards”.
The distinction between synthetic and anonymized data in the parliamentary draft of the AI Act is somewhat confusing, since considering the provision’s purpose, arguably only anonymized synthetic data qualifies as preferred method for tackling data bias. However, since anonymized synthetic data is a sub-category of anonymized data, the differentiation between those two terms is meaningless, unless the EU legislator attempts to highlight synthetic data as the preferred version of anonymized data (in which case the text of the provision should arguably read “synthetic or other forms of anonymized data”).
Irrespective of such details, it is clear that the EU legislator clearly requires the use of anonymized data for the processing of sensitive data as a primary bias detection and correction tool. It looks like AI compliance cannot be achieved without effective and AI-friendly data anonymization tools.
Recital 45(a) supports this (and extends the synthetic data use case to privacy protection and also addresses AI-system users, instead of only AI system providers):
“The right to privacy and to protection of personal data must be guaranteed throughout the entire lifecycle of the AI system. In this regard, the principles of data minimization and data protection by design and by default, as set out in Union data protection law, are essential when the processing of data involves significant risks to the fundamental rights of individuals.
Providers and users of AI systems should implement state-of-the-art technical and organizational measures in order to protect those rights. Such measures should include not only anonymization and encryption, but also the use of increasingly available technology that permits algorithms to be brought to the data and allows valuable insights to be derived without the transmission between parties or unnecessary copying of the raw or structured data themselves.”
The inclusion of synthetic data in the draft AI Act is a continuation of the ever-growing political awareness of the technology’s potential. This is underlined by a recent statement made by the EU Commission’s Joint Research Committee: “[Synthetic data] not only can be shared freely, but also can help rebalance under-represented classes in research studies via oversampling, making it the perfect input into machine learning and AI models."
Synthetic data is set to become one of the cornerstones of AI compliance in the very near future.
At MOSTLY AI we talk about data privacy a lot. And we were even the first in the world to produce an entire rap dedicated to data privacy!
But what really is data privacy? And what is it not? This blog post aims to provide a clear understanding of the definition of data privacy, its importance, and the various measures being taken to protect it.
The data privacy definition
Data privacy, also referred to as information privacy or data protection, is the concept of safeguarding an individual's personal information from unauthorized access, disclosure, or misuse. It entails the application of policies, procedures, and technologies designed to protect sensitive data from being accessed, used, or shared without the individual's consent.
To fully understand data privacy we thus need to understand Personal information first. Personal information, often referred to as personally identifiable information (PII), is any data that can be used to identify, locate, or contact an individual directly or indirectly.
Personal information encompasses a wide range of data points, including but not limited to, an individual's name, physical address, email address, phone number, Social Security number, driver's license number, passport number, and financial account details. Moreover, personal information can extend to more sensitive data such as medical records, biometric data, race, ethnicity, and religious beliefs. In the digital realm, personal information may also include online identifiers like IP addresses, cookies, or device IDs, which can be traced back to a specific individual.
In essence, data privacy is all about the protection of personal information. Why is that important?
Why is data privacy important?
Even if you don’t care about data privacy at all, the law cares. With numerous data protection regulations and laws in place, such as the General Data Protection Regulation (GDPR) in the European Union, it is essential for organizations to adhere to these regulations to avoid legal consequences. Gartner predicts that by 2024, 75% of the global population will have its personal data covered under privacy regulations.
Many companies have realized that data privacy is not only a legal requirement, but something customers care about too. In the Cisco 2022 Consumer Privacy Survey, 76 percent of respondents said they would not buy from a company who they do not trust with their data. Ensuring data privacy helps maintain trust between businesses and their customers and can become an important competitive differentiation.
Data privacy is an important element of cybersecurity. Implementing data privacy measures often leads to improved cybersecurity, as organizations take steps to safeguard their systems and networks from unauthorized access and data breaches. This helps to ensure that sensitive personal information such as financial data, medical records, and personal identification details are protected from identity theft, fraud, and other malicious activities.
And in case you’re still not convinced, how about this: The right to privacy or private life is enshrined in the Universal Declaration of Human Rights (Article 12) – data privacy is a Human Right! Data privacy empowers individuals to have control over their personal information and decide how it is used, shared, and stored.

How to protect data privacy in an organization?
Every company, every business is collecting and working with data. To ensure data privacy there is not one thing that a company needs to do, but many things.
Foremost data privacy needs to start from the top in an organization because leadership plays a critical role in establishing a culture of privacy and ensuring the commitment of resources to implement robust data protection measures. When executives and top management prioritize data privacy, it sends a clear message throughout the organization that protecting personal information is a fundamental aspect of the company's values and mission. This commitment fosters a sense of shared responsibility, guiding employees to adhere to privacy best practices, comply with relevant regulations, and proactively address potential risks.
Once the support from the top management is established, data privacy needs to be embedded in an organization. This is typically achieved through implementing privacy policies. Organizations should have clear privacy policies outlining the collection, use, storage, and sharing of personal information. These policies should be easily accessible and comprehensible to individuals.
These policies define certain best practices and standards when it comes to data privacy. Companies that take data privacy seriously follow these, for example:
- Data minimization: Collecting only the necessary data for the intended purpose, and not retaining it longer than required, helps reduce the risk of unauthorized access or misuse.
- Data anonymization: Data anonymization is the process of removing or obfuscating personally identifiable information from datasets. The goal of data anonymization is to protect the privacy of individuals whose data is included in the dataset. Anonymized data can be shared more freely than non-anonymized data, as the risk of exposing sensitive information is greatly reduced.
- Encryption: Encrypting sensitive data ensures that even if unauthorized access occurs, the information remains unreadable and unusable.
- Access control: Implementing strict access control measures, such as strong passwords and multi-factor authentication, helps prevent unauthorized individuals from accessing sensitive data.
An entire industry around best practices and how these can be ensured (and audited!) has emerged.: Regularly auditing and monitoring data privacy practices within an organization helps identify any potential vulnerabilities and rectify them promptly.
The two most recognized standards and audits are ISO 27001 and SOC 2. ISO 27001 is a globally recognized standard for information security management systems (ISMS), providing a systematic approach to managing sensitive information and minimizing security risks. By implementing and adhering to ISO 27001, organizations can showcase their dedication to maintaining a robust ISMS and assuring stakeholders of their data protection capabilities.
On the other hand, SOC 2 (Service Organization Control 2) is an audit framework focusing on non-financial reporting controls, specifically those relating to security, availability, processing integrity, confidentiality, and privacy. Companies undergoing SOC 2 audits are assessed on their compliance with the predefined Trust Services Criteria, ensuring they have effective controls in place to safeguard their clients' data.
By leveraging ISO 27001 and SOC 2 standards and audits, organizations can not only bolster their internal security and privacy practices but also enhance trust and credibility with clients, partners, and regulatory bodies, while mitigating risks associated with data breaches and non-compliance penalties. We at MOSTLY AI have heavily invested in this space and are certified under both ISO 27001 and SOC 2 Type.
Lastly, let’s turn to the human again: the employees. Numbers are floating around the Internet that claim to show that 95% of all data breaches happen due to human error. Although the primary source for this number could not be identified, it’s probably correct. Therefore, educating employees about data privacy best practices and the importance of protecting sensitive information plays a crucial role in preventing breaches caused by human error.
Data privacy is everyone's business
Data privacy is an essential aspect of our digital lives, as it helps protect personal information and maintain trust between individuals, businesses, and governments. By understanding the importance of data privacy and implementing appropriate measures, organizations can reduce the risk of data breaches, ensure compliance with data protection laws, and maintain customer trust. Ultimately, data privacy is everyone's responsibility, and it begins with awareness and education.
Policies are designed for far-reaching, societal-level impact. We expect them to be solidly evidence-based and data-driven. The pandemic highlighted how much we rely on (and that we oftentimes still lack) good quality data that is comprehensive and easy to access across nation, states, research groups and different institutions.
However, the status quo of data anonymization and data sharing, especially in healthcare and policy applications, severely limit the amount of information that can be retained. Finding better ways to collaborate on data without compromising privacy is key for policy makers, researchers and businesses across Europe. As part of this mission, the European Commission’s Joint Research Centre thoroughly looked into the opportunity AI-generated synthetic data presents for privacy-safe data use. They concluded with a very strong endorsement for synthetic data in their final report:
Synthetic data will be the key enabler for AI
- "[Synthetic data] can become the unifying bridge between policy support and computational models, by unlocking the potential of data hidden in silos; thus becoming the key enabler of AI in business and policy applications in Europe."
- "Resulting data not only can be shared freely, but also can help rebalance under-represented classes in research studies via oversampling, making it the perfect input into machine learning and AI models"
It is very cost efficient to use synthetic data for privacy protection
- "Synthetic data change[s] everything from privacy to governance"
- “Synthetic data eliminates the bureaucratic burden associated with gaining access to sensitive data"
- "among the privacy-preservation technique studies analysed, data synthesis gave the best price/effort ratio."
Synthetic data is a mature privacy enhancing technology (PET) that is ready to be deployed
- "Synthetic data have proven great potential and are the go-to methods ready to be deployed in real-life scenarios. Policy applications can now be researched and developed with little risk involved."
- "Commercial solutions still beat the available research and open source solutions by a huge margin at the time of writing."
- "A robust commercial solution for hierarchical data synthesis was offered by the company MOSTLY.AI to test the synthesis quality. The results, available in the accompanying archive both as a PDF report and CSV files with the data correlations, are impressive."
Synthetic data improves fairness, diversity and inclusion
- “...policy makers will have the opportunity to create radically new policy instruments based on more detailed less biased population data.”
- "policy support can embrace diversity by stopping averaging out, and thus marginalisation of under-represented minorities by shifting away from aggregate-level statistics; capture the full diversity within the population, and start coping with its complexity, rather than continue ignoring it."
Synthetic data facilitates open data, data democratization, and data literacy
- "Data democratization – a new type of Open Data would emerge from the shift towards the synthetic data"
- "synthetic data in policy making process will enable involvement of much broader communities [..] same goes for algorithmic governance"
- "Data literacy is today as what was computer literacy in 1990s. Synthetic data have potential to accelerate their learning path towards data-driven decision & policy making by making available data closer to the people’s perspective."
Why is not everyone in the EU using synthetic data (yet)?
With such strong proof for the maturity, quality and cost-efficiency of AI-generated synthetic data, it begs the question why not every European institution or private sector organization rich in sensitive data is using synthetic data yet? Particularly, as the European Commissions’s JRC report pointed out, that synthetic data not only helps with privacy protection, but also with accelerating AI adoption, democratizing data access, improving AI fairness and facilitating much-needed data literacy across Europe.
Looking at the EU Commission’s strategy for AI and their Digital Decade, this indeed seems to be an interesting question. According to their AI strategy, it’s the EU’s ambition to “become a global leader in developing cutting-edge, trustworthy AI” and to “ensur[e] that AI is human-centric”. But to ensure widespread adoption of AI amongst European institutions and businesses, it’s self-evident that broad access to high-quality, yet privacy-safe data is a necessity. The same holds true for two of the four main goals that the EU Commission set for itself as part of their Digital Decade. One is the digital transformation of businesses, the other a “digitally skilled population and highly skilled digital professionals”. But: a business that cannot quickly access and innovate with its data (while ensuring compliance with European data protection law) cannot digitally transform. And a European workforce, that cannot openly access granular data simply cannot become data literate, let alone highly digitally skilled.
Thus we at MOSTLY AI strongly support the call to action of the European Commission’s JRC on what shall be done next. "More important than focusing on how to synthesize data is:
- what can we achieve with the new data available at scale,
- how to convince data owners to unleash their coveted data to the broadest audience,
- and how to accommodate this massive new ability into the policy formulation and assessment." [formatting and bulletpoints by the author]
With synthetic data, the technology is already there. It’s mature, cost-efficient, accurate and ready to be deployed. What is left to do by policy makers, if they really want the EU to excel on its path towards digital transformation and widespread development and adoption of human-centric, trustworthy AI, is to open up the access to data - and AI-generated synthetic data will be the single-most valuable tool to help the regulators to do that.
What if the EU would use open synthetic data to fight cancer?
Synthetic images are already playing a crucial role in the training of computer vision models designed to detect tumors and cancer cells. Just like synthetic tabular data, synthetic images can improve the accuracy of AI-powered decision support tools dramatically. For example, Michigan Medicine's neurosurgery team increased the accuracy of their AI models from 68% to 96% with synthetic training data. How? Simply put, the more images the model can look at, the better it gets at detecting pathologies. Synthetic data generation allowed them to upsample the number of images available for model training.
What has been done using synthetic images can be extrapolated to other data types, such as structured tabular data. Rebalancing imbalanced datasets or using synthetic data to augment datasets can help improve model accuracy not just for cancer detection but also for other rare diseases or events, such as lockdowns, unusual energy consumption patterns or recessions.
Data sharing is also key here. Medical research is often plagued with the difficulty of sharing or obtaining large enough datasets where the correlations weren’t destroyed by old data anonymization techniques, like aggregation or data masking. Researchers in different countries should be able to work on the same data in order to arrive at the same conclusions, without endangering the privacy of patients.
To date, there is no open synthetic cancer dataset available in the EU that can be freely accessed by researchers and policymakers. But what if? What if the valuable raw data that was already collected about millions of European cancer patients would be synthesized and - for the very first time - made available to a broad group of researchers? Just imagine the advances in healthcare our society could achieve. With MOSTLY AI's synthetic data platform this can become a reality.
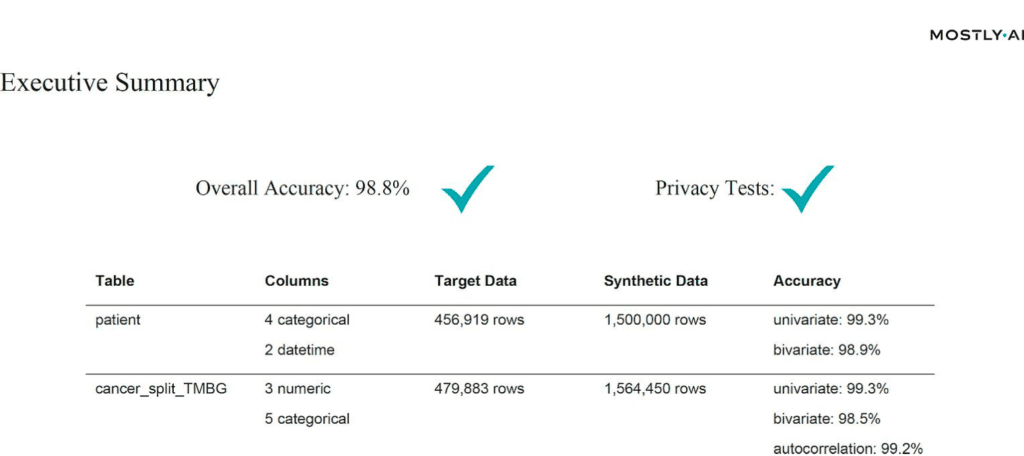
The EU Commission’s JRC used MOSTLY AI's synthetic data generator for synthetic cancer data - with impressive results
For their study on synthetic data, the Joint Research Center leveraged MOSTLY AI's synthetic data platform to train on half a million of real-world cancer records. They then generated 2 million highly accurate, yet truly anonymous synthetic cancer patient records. Chapter 6 of the report includes the details of their analysis. But to summarize in their own words, “the results [...] are impressive.”
“The resulting dataset has shown astonishing level of realism (are we looking at the original or the synthetic data?) while maintaining all the privacy test. Resulting data not only can be shared freely, but also can help rebalance under- represented classes in research studies via oversampling, making it the perfect input into machine learning and AI models.”
In particular, compared to an open-source alternative, MOSTLY AI could show its strength with its high level of automation. While the open-source solution required several person-months in an attempt to clean up the sample data, MOSTLY AI’s solution delivered out-of-the-box with top-in-class accuracy and rule adherence:
“Commercial solutions still beat the available research and open source solutions by a huge margin at the time of writing”
We are very proud to have created a synthetic data generator that stands up under such close scrutiny and are convinced that in the coming years synthetic data will be an even more valuable tool for policymakers - in the EU and beyond.
TL;DR: Synthetic financial data is the fuel banks need to become AI-first and to create cutting-edge services. In this report, you can read about:
- banking technology trends in 2022 from superapps to personalized digital banking
- data privacy legislations affecting the banking industry in 2022
- the challenges in AI/ML development, testing and data sharing that synthetic data can solve
- the most valuable data science and synthetic data use cases in banking: customer acquisition and advanced analytics, mortgage analytics, credit decisioning and limit assessment, risk management and pricing, fraud and anomaly detection, cybersecurity, monitoring and collections, churn reduction, servicing and engagement, enterprise data sharing, and synthetic test data for digital banking product development
- synthetic data engineering: how to integrate synthetic data in financial data architectures
Table of Contents
- Banking technology trends
- The state of data privacy in banking in 2022
- The most valuable synthetic data use cases in banking
- Synthetic data for AI, advanced analytics, and machine learning
- Synthetic data for enterprise data sharing
- Synthetic test data for digital banking products
- How to integrate synthetic data generators into financial systems?
- The future of financial data
Banks and financial institutions are aware of their data and innovation gaps and AI-generated synthetic data is their best bet. According to Gartner:
By 2030, 80 percent of heritage financial services firms will go out of business, become commoditized or exist only formally but not competing effectively.
A pretty dire prophecy, but nonetheless realistic, with small neobanks and big tech companies eyeing their market. There is no way to run but forward.
The future of banking is all about becoming AI-first and creating cutting-edge digital services coupled with tight cybersecurity. In the race to a tech-forward future, most consultants and business prophets forget about step zero: customer data. In this blog post, we will give an overview of the data science use cases in banking and attempt to offer solutions throughout the data lifecycle. We'll concentrate on the easiest to deploy and highest value synthetic data use cases in banking. We'll cover three clusters of synthetic data use cases: data sharing, AI, advanced analytics, machine learning, and software testing. But before we dive into the details, let's talk about the banking trends of today.
Banking technology trends
The pandemic accelerated digital transformation, and the new normal is here to stay. According to Deloitte, 44% of retail banking customers use their bank's mobile app more often. At Nubank, a Brazilian digital bank, the number of accounts rose by 50%, going up to 30 million. It is no longer the high-street branch that will decide the customer experience. Apps become the new high-touch, flagship branches of banks where the stakes are extremely high. If the app works seamlessly and offers personalized banking, customer lifetime value increases. If the app has bugs, frustration drives customers away. Service design is an excellent framework for creating distinctive personalized digital banking experiences. Designing the data is where it should all start.
A high-quality synthetic data generator is one mission-critical piece of the data design tech stack. Initially a privacy-enhancing technology, synthetic data generators can generate representative copies of datasets. Statistically the same, yet none of the synthetic data points match the original. Beyond privacy, synthetic data generators are fantastic data augmentation tools too. Synthetic data is the modeling clay that makes this data design process possible. Think moldable test data and training data for machine learning models based on real production data.
The rise of superapps is another major trend financial institutions should watch out for. Building or joining such ecosystems makes absolute sense if banks think of them as data sources. Data ecosystems are also potential spaces for customer acquisition. With tech giants entering the market with payment and retail banking products, data protectionism is rising. However, locking up data assets is counterproductive, limiting collaboration and innovation. Sharing data is the only way to unlock new insights. Especially for banks, whose presence in their customers' lives is not easy to scale unless via collaborations and new generation digital services. Insurance providers and telecommunications companies are the first obvious candidates. Other beyond-banking service providers could also be great partners, from car rental companies to real estate services, legal support, and utility providers. Imagine a mortgage product that comes with a full suite of services needed throughout a property purchase. Banks need to create a frictionless, hyper-personalized customer experience to harness all the data that comes with it.
Another vital part of this digital transformation story is AI adoption. In banking, it's already happening. According to McKinsey,
"The most commonly used AI technologies (in banking) are: robotic process automation (36 percent) for structured operational tasks; virtual assistants or conversational interfaces (32 percent) for customer service divisions; and machine learning techniques (25 percent) to detect fraud and support underwriting and risk management."
It sounds like banks are running full speed ahead into an AI future, but the reality is more complicated than that. Due to the legacy infrastructures of financial institutions, the challenges are numerous. Usually, there is no clear strategy or fragmented ones with no enterprise-wide scale. Different business units operate almost completely cut off with limited collaboration and practically no data sharing. These fragmented data assets are the single biggest obstacle to AI adoption. McKinsey estimates that AI technologies could potentially deliver up to $1 trillion of additional value in banking each year. It is well worth the effort to unlock the data AI and machine learning models so desperately need. Let's take a look at the number one reason or rather excuse banks and financial institutions hide behind when it comes to AI/AA/ML innovation: data privacy.
The state of data privacy in banking in 2022
Banks have always been the trustees of customer privacy. Keeping data and insights tightly secured has prevented banks from becoming data-centric institutions. What's more, an increasingly complex and restrictive legislative landscape makes it difficult to comply globally.
Let’s be clear. The ambition to secure customer data is the right one. Banks must take security seriously, especially in an increasingly volatile cybersecurity environment. However, this cannot take place at the expense of innovation. The good news is that there are tools to help. Privacy-enhancing technologies (PETs) are crucial ingredients of a tech-forward banking capability stack. It's high time for banking executives, CIOs, and CDOs to get rid of their digital banking blindspots. Banks must stop using legacy data anonymization tools that endanger privacy and hinder innovation. Data anonymization methods, like randomization, permutation, and generalization, carry a high risk of re-identification or destroy data utility.
Maurizio Poletto, Chief Platform Officer at Erste Group Bank AG, said in The Executive's Guide to Accelerating Artificial Intelligence and Data Innovation with Synthetic Data:
"In theory, in banking, you could take real account data, scramble it, and then put it into your system with real numbers, so it's not traceable. The problem is that obfuscation is nice, and anonymization is nice, but you can always find a way to get the original data back. We need to be thorough and cautious as a bank because it is sensitive data. Synthetic data is a good way to continue to create value and experiment without having to worry about privacy, particularly because society is moving toward better privacy. This is just the beginning, but the direction is clear."
Modern PETs include AI-generated synthetic data, homomorphic encryption, or federated learning. They offer the way out of the data dilemma in banking. Data innovators in banking should choose the appropriate PET for the appropriate use case. Encryption solutions should be looked at when necessary to unencrypt the original data. Anonymized computation, such as federated learning, is a great choice when models can get trained on users' mobile phones. AI-generated synthetic data is the most versatile privacy-enhancing technology with just one limitation. Synthetic datasets generated by AI models trained on original data cannot be reverted back to the original. Synthetic datasets are statistically identical to the original datasets they were modeled on. However, there is no 1:1 relationship between the original and the synthetic data points. This is the very definition of privacy. As a result, AI-generated synthetic data is great for specific use cases—advanced analytics, AI and machine learning training, software testing, and sharing realistic but unencryptable datasets. Synthetic data is not a good choice for use cases where the data needs to be reverted back to the original, such as information sharing for anti-money laundering purposes, where perpetrators need to be re-identified. Let's look at a comprehensive overview of the most valuable synthetic data use cases in banking!
The most valuable synthetic data use cases in banking
Synthetic data generators come in many shapes and forms. In the following, we will be referring to MOSTLY AI's synthetic data generator. It is the market-leading synthetic data solution able to generate synthetic data with high accuracy. MOSTLY AI's synthetic data platform comes with advanced features, such as direct database connection and the ability to synthesize complex data structures with referential integrity. As a result, MOSTLY AI can serve the broadest range of use cases with suitably generated synthetic data. In the following, we will detail the lowest hanging synthetic data fruits in banking. These are the use cases we have seen to work well in practice and generate a high ROI.
| CHALLENGES | HOW CAN SYNTHETIC DATA HELP? |
|---|---|
AI/AA/ML
|
|
TESTING
|
|
DATA SHARING
|
|
Synthetic data for AI, advanced analytics, and machine learning
Synthetic data for AI/AA/ML is one of the richest use case categories with many high-value applications. According to Gartner, by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated. Machine learning and AI unlocks a range of business benefits for retail banks.
- Advanced analytics improves customer acquisition by optimizing the marketing engine with hyper-personalized messages and precise next best actions.
- Intelligence from the very first point of contact increases customer lifetime value.
- Operating costs will be lower if decision-making in acquisition and servicing is supported with well-trained machine learning algorithms. Lower credit risk is also a benefit that comes from early detection of behaviors that signal a higher risk of default.
Automated, personalized decisions across the entire enterprise can increase competitiveness. The data backbone, the appropriate tools, and talent need to be in place to make this happen. Synthetic data generation is one of those capabilities essential for an AI-first bank to develop. The reliability and trustworthiness of AI is a neglected issue. According to Gartner:
65% of companies can't explain how specific AI model decisions or predictions are made. This blindness is costly. AI TRiSM tools, such as MOSTLY AI's synthetic data platform, provide the Trust, Risk and Security Management needed for effective explainability, ModelOps, anomaly detection, adversarial attack resistance and data protection. Companies need to develop these new capabilities to serve new needs arising from AI adoption.
From explainability to performance improvement, synthetic data generators are one of the most valuable building tools. Data science teams need synthetic data to succeed with AI and machine learning use cases. Here is how to use synthetic data in the most common AI banking applications.
CUSTOMER ACQUISITION AND ADVANCED ANALYTICS
CRM data is the single most valuable data asset for customer acquisition and retention. A wonderful, rich asset that holds personal data and behavioral data of the bank's future prospects. However, due to privacy legislation, up to 80% of CRM data tends to be locked away. Compliant CRM data for advanced analytics and machine learning applications is hard to come by. Banks either comply with regulations and refrain from developing a modern martech platform altogether or break the rules and hope to get away with it. There is a third option. Synthetic customer data is as good as real when it comes to training machine learning models. Insights from these type of analytics can help identify new prospects and improve sign-up rates significantly.
MORTGAGE ANALYTICS, CREDIT DECISIONING AND LIMIT ASSESSMENT
AI in lending is a hot topic in finance. Banks want to reach out to the right people with the right mortgage and credit products. In order to increase precision in targeting, a lot of personal data is needed. The more complete the customer data profile, the more intelligent mortgage analytics becomes. Better models bring lower risk both for the bank and for the customer. Rule-based or logistic regression models rely on a narrow set of criteria for credit decision-making. Banks without advanced behavioral analytics and models underserve a large segment of customers. People lacking formal credit histories or deviating from typical earning patterns are excluded. AI-first banks utilize huge troves of alternative data sources. Modern data sources include social media, browsing history, telecommunications usage data, and more. However, using these highly personal data sources in their original for training AI models is often a challenge. Legacy data anonymization techniques destroy the very insights the model needs. Synthetic data versions retain all of these insights. Thanks to the granular, feature-rich nature of synthetic data, lending solutions can use all the intelligence.
RISK MANAGEMENT AND PRICING
Pricing and risk prediction models are some of the most important models to get right. Even a small improvement in their performance can lead to significant savings and/or higher revenues. Injecting additional domain knowledge into these models, such as synthetic geolocation data or synthetic text from customer conversations, significantly improves the model's ability to quantify a customer's propensity to default. MOSTLY AI's ability to provide the accuracy needed to generate synthetic geolocation data has been proven already. Synthetic text data can be used for training machine learning models in a compliant way on transcripts of customer service interactions. Virtual loan officers can automate the approval of low-risk loans reliably.
It is also mission-critical to be able to provide insight into the behavior of these models. Local interpretability is the best approach for explainable AI today, and synthetic data is a crucial ingredient of this transparency.
FRAUD AND ANOMALY DETECTION
Fraud is one of the most interesting AI/ML use cases. Fraud and money laundering operations are incredibly versatile, getting more and more sophisticated every day. Adversaries are using a lot of automation too to find weaknesses in financial systems. It's impossible to keep up with rule-based systems and manual follow-ups. False positives cost a lot of money to investigate, so it's imperative to continuously improve precision aided with machine learning models. To make matters even more challenging, fraud profiles vary widely between banks. The same recipe for catching fraudulent transactions might not work for every financial institution. Using machine learning to detect fraud and anomaly patterns for cybersecurity is one of the first synthetic data use cases banks usually explore. The fraud detection use case goes way beyond privacy and takes advantage of the data augmentation possibility during synthesization. Maurizio Poletto, CPO at Erste Group Bank, recommends synthetic data upsampling to improve model performance:
Synthetic data can be used to train AI models for scenarios for which limited data is available—such as fraud cases. We could take a fraud case using synthetic data to exaggerate the cluster, exaggerate the amount of people, and so on, so the model can be trained with much more accuracy. The more cases you have, the more detailed the model can be.
Training and retraining models with synthetic data can improve fraud detection model performance, leading to valuable savings on investigating false positives.
MONITORING AND COLLECTIONS
Transaction analysis for risk monitoring is one of the most privacy-sensitive AI use cases banks need to be able to handle. Apart from traditional monitoring data, like repayment history and credit bureau reports, banks should be looking to utilize new data sources, such as time-series bank data, complete transaction history, and location data. Machine learning models trained with these extremely sensitive datasets can reliably microsegment customers according to value at risk and introduce targeted interventions to prevent defaults. These highly sensitive and valuable datasets cannot be used for AI/ML training without effective anonymization. MOSTLY AI's synthetic data generator is one of the best on the market when it comes to synthesizing complex time-series, behavioral data, like transactions with high accuracy. Behavioral synthetic data is one of the most difficult synthetic data categories to get right, and without a sophisticated AI engine, like MOSTLY AI's, results won't be accurate enough for such use cases.
CHURN REDUCTION, SERVICING, AND ENGAGEMENT
Another high-value use case for synthetic behavioral data is customer retention. A wide range of tools can be put to good use throughout a customer's lifetime, from identifying less engaged customers to crafting personalized messages and product offerings. The success of those tools hinges on the level of personalization and accuracy the initial training data allows. Machine learning models are the most powerful at pattern recognition. ML's ability to identify microsegments no analyst would ever recognize is astonishing, especially when fed with synthetic transaction data. Synthetic data can also serve as a bridge of intelligence between different lines of business: private banking and business banking data can be a powerful combination to provide further intelligence, but strictly in synthetic form. The same applies to national or legislative borders: analytics projects with global scope can be a reality when the foundation is 100% GDPR compliant synthetic data.
ALGORITHMIC TRADING
Financial institutions can use synthetic data to generate realistic market data for training and validating algorithmic trading models, reducing the reliance on historical data that may not always represent future market conditions. This can lead to improved trading strategies and increased profitability.
STRESS TESTING
Banks can use synthetic data to create realistic scenarios for stress testing, allowing them to evaluate their resilience to various economic and financial shocks. This helps ensure the stability of the financial system and boosts customer confidence in the institution's ability to withstand adverse conditions.
Synthetic data for enterprise data sharing
Open financial data is the ultimate form of data sharing. According to McKinsey, economies embracing financial data sharing could see GDP gains of between 1 and 5 percent by 2030, with benefits flowing to consumers and financial institutions. More data means better operational performance, better AI models, more powerful analytics, and customer-centric digital banking products facilitating omnichannel experiences. The idea of open data cannot become a reality without a robust, accurate, and safe data privacy standard shared by all industry players in finance and beyond. This is a vision shared by Erste Group Bank's Chief Platform Officer:
Imagine if we in banking use synthetic data to generate realistic and comparable data from our customers, and the same thing is done by the transportation industry, the city, the insurance company, and the pharmaceutical company, and then you give all this data to someone to analyze the correlation between them. Because the relationship between well-being, psychological health, and financial health is so strong, I think there is a fantastic opportunity around the combination of mobility, health, and finance data.
It's an ambitious plan, and like all grand designs, it's best to start building the elements early. At this point, most banks are still struggling with internal data sharing with distinct business lines acting as separate entities and being data protectionist when open data is the way forward. Banks and financial institutions share little intelligence, citing data privacy and legislation as their main concern. However, data sharing might just become an obligation very soon with the EU putting data altruism on the map in the upcoming Data Governance Act. While sharing personal data will remain strictly forbidden and increasingly so, anonymized data sharing will be expected of companies in the near future. In the U.S., healthcare insurance companies and service providers are already legally bound to share their data with other healthcare providers. The same requirement makes a lot of sense in banking too where so much depends on credit history and risk prediction. While some data is shared, intelligence is still withheld. Cross-border data sharing is also a major challenge in banking. Subsidiaries either operate in a completely siloed way or share data illegally. According to Axel von dem Bussche, Partner at Taylor Wessing and IT lawyer, as much as 95% of international data sharing is illegal due to the destruction of the EU-US Privacy Shield by the Schrems II decision.
Some organizations fly analysts and data scientists to the off-shore data to avoid risky and forbidden cross-border data sharing. It doesn't have to be this complicated. Synthetic data sharing is compliant with all privacy laws across the globe. Setting up synthetic data sandboxes and repositories can solve enterprise-wide data sharing across borders since synthetic data does not qualify as personal data. As a result, it is out of scope of GDPR and the infamous Schrems II. ruling, which effectively prohibited all sharing of personal data outside the EU.
Third-party data sharing within the same legislative domain is also problematic. Banks buy many third-party AI solutions from vendors without adequately testing the solutions on their own data. The data used in procurement processes is hard to get, causing costly delays and heavily masked to prevent sensitive data leaks through third parties. The result is often bad business decisions and out-of-the-box AI solutions that fail to deliver the expected performance. Synthetic data sandboxes are great tools for speeding up and optimizing POC processes, saving 80% of the cost.
Synthetic test data for digital banking products
One of the most common data sharing use cases is connected to developing and testing digital banking apps and products. Banks accumulate tons of apps, continuously developing them, onboarding new systems, and adding new components. Manually generated test data for such complex systems is a hopeless task, and many revert to the old dangerous habit of using production data for testing systems. Banks and financial institutions tend to be more privacy-conscious, but their solutions to this conundrum are still suboptimal. Time and time again, we see reputable banks and financial institutions roll out apps and digital banking services after only testing them with heavily masked or manually generated data. One-cent transactions and mock data generators won't get you far when customer expectations for seamless digital experiences are sky-high.
To complicate things further, complex application development is rarely done in-house. Data owners and data consumers are not the same people, nor do they have the full picture of test scenarios and business rules. Labs and third-party dev teams rely on the bank to share meaningful test data with them, which simply does not happen. Even if testing is kept in-house, data access is still problematic. While in other, less privacy-conscious industries, developers and test engineers use radioactive test data in non-production environments, banks leave testing teams to their own devices. Manual test data generation with tools like Mockaroo and the now infamous Faker library misses most of the business rules and edge cases so vital for robust testing practices. Dynamic test users for notification and trigger testing are also hard to come by. To put it simply, it's impossible to develop intelligent banking products without intelligent test data. The same goes for the testing of AI and machine learning models. Testing those models with synthetically simulated edge cases is extremely important to do when developing from scratch and when recalibrating models to avoid drifting. Models are as good as the training data, and testing is as good as test data. Payment applications with or without personalized money management solutions need the synthetic approach: realistic synthetic test data and edge case simulations with dynamic synthetic test users. Synthetic test data is fast to generate and can create smaller or larger versions of the same dataset as needed throughout the testing pyramid from unit testing, through integration testing, UI testing to end-to-end testing.
Erste Bank's main synthetic data use case is test data management. The bank is creating synthetic segments and communities, building new features, and testing how certain types of customers would react to these features.
Normally, the data we use is static. We see everything from the past. But features like notifications and triggers—like receiving a notification when your salary comes in—can only be tested with dynamic test users. With synthetic data, you push a button to generate that user with an unlimited number of transactions in the past and a limited number of transactions in the future, and then you can put into your system a user which is alive.
These live, synthetic users can stand in for production data and provide a level of realism unheard of before while protecting customers' privacy. The Norwegian Data Protection Authority issued a fine for using production data in testing, adding that using synthetic data instead would have been the right course to take.
Testing is becoming a continuous process. Deploying fast and iterating early is the new mantra of DevOps teams. Setting up CI/CD (continuous integration and delivery) pipelines for continuous testing cannot happen without a stable flow of high-quality test data. Synthetic data generators trained on real data samples can provide just that – up-to-date, realistic, and flexible data generation on-demand.
How to integrate synthetic data generators into financial systems?
First and foremost, it's important to understand that not all synthetic data generators are created equal. It's particularly important to select the right synthetic data vendor who can match the financial institution's needs. If a synthetic data generator is inaccurate, the resulting synthetic datasets can lead your data science team astray. If it's too accurate, the generator overfits or learns the training data too well and could accidentally reproduce some of the original information from the training data. Open-source options are also available. However, the control over quality is fairly low. Until a global standard for synthetic data arrives, it's important to proceed with caution when selecting vendors. Opt for synthetic data companies, which already have extensive experience with sensitive financial data and know-how to integrate synthetic data successfully with existing infrastructures.
The future of financial data is synthetic
Our team at MOSTLY AI is working with large banks and financial organizations very closely. We know that synthetic data will be the data transformation tool that will change the financial data landscape forever, enabling the flow and agility necessary for creating competitive digital services. While we know that the direction is towards synthetic data across the enterprise, we know full well how difficult it is to introduce new technologies and disrupt the status quo in enterprises, even if everyone can see the benefits. One of the most important tasks of anyone looking to make a difference with synthetic data is to prioritize use cases in accordance with the needs and possibilities of the organization. Analytics use cases with the biggest impact can serve as flagship projects, establishing the foundations of synthetic data adoption. In most organizations, mortgage analytics, pricing, and risk prediction use cases can generate the highest immediate monetary value, while synthetic test data can massively accelerate the improvement of customer experience and reduce compliance and cybersecurity risk. It's good practice to establish semi-independent labs for experimentation and prototyping: Erste Bank's George Lab is a prime example of how successful digital banking products can be born of such ventures. The right talent is also a crucial ingredient of success. According to Erste Bank's CPO, Maurizio Poletto:
Talented data engineers want to spend 100% of their time in data exploration and value creation from data. They don't want to spend 50% of their time on bureaucracy. If we can eliminate that, we are better able to attract talent. At the moment, we may lose some, or they are not even coming to the banking industry because they know it's a super-regulated industry, and they won't have the same freedom they would have in a different industry.
Once you have the attraction of a state-of-the-art tech stack enabling agile data practices, you can start building cross-functional teams and capabilities across the organization. The data management status quo needs to be disrupted, and privacy, security, and data agility champions will do the groundwork. Legacy data architectures keeping banks and financial institutions back from innovating and endangering customers' privacy need to be dealt with soon. The future of data-driven banking is bright, and that future is synthetic.
Synthetic data is quickly becoming a critical tool for organizations to unlock the value of sensitive customer data while keeping the privacy of their customers protected and in compliance with data protection regulations such as GDPR and CCPA. It can be generated quickly in abundance and has been proven to drastically improve machine learning performance. As a result, it is often used for advanced analytics and AI training, such as predictive algorithms, fraud detection and pricing models.
According to Gartner, by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.
MOSTLY AI pioneered the creation of synthetic data for AI model development and software testing. With things moving so quickly in this space here are three trends that we see happening in AI and synthetic data in 2022:
1. Bias in AI will get worse before it gets better.
Most of the machine learning and AI algorithms currently in production, interacting with customers, making decisions about people have never been audited for fairness and discrimination, the training data has never been augmented to fix embedded biases. It is only through massive scandals that companies are finding out and learning the hard way that they need to pay more attention to biased data and to use fair synthetic data instead.
2. Companies’ data assets will freeze up due to regulations and declining customer consent.
Regulations all over the world are getting stricter every day; many countries have a personal data protection policy in place by now. Using customer data is getting increasingly difficult for a number of other reasons too - people are more privacy-conscious and are increasingly likely to refuse consent to using their data for analytics purposes. So companies literally run out of relevant and usable data assets. Companies will learn to understand that synthetic data is the way out of this dilemma.
3. Synthetic data will be standardized with globally recognized benchmarks for privacy and accuracy.
Not all synthetic data is created equal. To start off with, there is a world of difference between what we call structured and unstructured synthetic data. Unstructured data means images and text for example, while structured data is mainly tabular in nature. There are lots of open source and proprietary synthetic data providers out there for both kinds of synthetic data and the quality of their generators varies widely. It’s high time to establish a synthetic data standard to make sure that synthetic data users get consistently high-quality synthetic data. We are already working on structured synthetic data standards.
If you’d like to connect on these trends, we’re happy to set up an interview or write a byline on these topics for your publication. Please let us know - thanks.
[Update April 2025: We have open-sourced our quality assurance toolkit for synthetic data under a fully permissive license at https://github.com/mostly-ai/mostlyai-qa. Please refer to that repository, respectively to the accompanying paper for an up-to-date approach on measuring fidelity vs. privacy of synthetic data in practice.]
This is the second part of our blog post series on anonymous synthetic data. While Part I introduced the fundamental challenge of true anonymization, this part will detail the technical possibilities of establishing the privacy and thus safety of synthetic data.
The new era of anonymization: AI-generated synthetic copies
MOSTLY AI's synthetic data platform enables anyone to reliably extract global structure, patterns, and correlations from an existing dataset, to then generate completely new synthetic data at scale. These synthetic data points are sampled from scratch from the fitted probability distributions and thus bear no 1:1 relationship to any real, existing data subjects.
This lack of direct relationship to actual people already provides a drastically higher level of safety and renders deterministic re-identification, as discussed in Part I, impossible. However, a privacy assessment of synthetic data must not stop there but also needs to consider the most advanced attack scenarios. For one, to be assured, that customers’ privacy is not being put at any risk. And for two, to establish that a synthetic data solution indeed adheres to modern-day privacy laws. Over the past months, we have had two renowned institutions conduct thorough technical and legal assessments of MOSTLY AI's synthetic data across a broad range of attack scenarios and a broad range of datasets. And once more, it was independently established and attested by renowned experts: synthetic data by MOSTLY AI is not personal data anymore, thus adheres to all modern privacy regulations. ✅ While we go into these assessments’ details in this blog post, we are more than happy to share the full reports with you upon request.
The privacy assessment of synthetic data
Europe has recently introduced the toughest privacy law in the world, and its regulation also provides the strictest requirements for anonymization techniques. In particular, WP Article 29 has defined three criteria that need to be assessed:
- (i) is it still possible to single out an individual,
- (ii) is it still possible to link records relating to an individual, and
- (iii) can information be inferred concerning an individual?
These translate to evaluating synthetic data with respect to:
- the risk of identity disclosure: can anyone link actual individuals to synthetically generated subjects,
- the risk of membership disclosure: can anyone infer whether a subject was or was not contained in a dataset based on the derived synthetic data,
- the risk of attribute disclosure: can anyone infer additional information on a subject’s attribute if that subject was contained in the original data?
Whereas self-reported privacy metrics continue to emerge, it needs to be emphasized that these risks have to be empirically tested in order to assess the correct workings of any synthetic data algorithm as well as implementation.
Attribute disclosure
How is it possible for a third party to empirically assess the privacy of a synthetic data implementation? SBA Research, a renowned research center for information security, has been actively researching the field of attribute disclosure over the past couple of years and recently developed a sophisticated leave-one-out ML-based attribute disclosure test framework, as sketched in Figure 1. In that illustration, T depicts the original target data, that serves as training data for generating multiple synthetic datasets ST. T’ is then a so-called neighboring dataset of T that only differs with respect to T by excluding a single individual. Any additional information obtained from the synthetic datasets ST (based on T) as opposed to ST’ (based on T’) would reveal an attribute disclosure risk from including that individual. The risk of attribute disclosure can be systematically evaluated by training a multitude of machine learning models that predict a sensitive attribute based on all remaining attributes in order to then study the predictive accuracy for the excluded individual (the red-colored male depicted in Figure 1). A privacy-safe synthetic data platform, like MOSTLY AI with its in-built privacy safeguards, does not exhibit any measurable change in inference due to the inclusion or exclusion of a single individual.
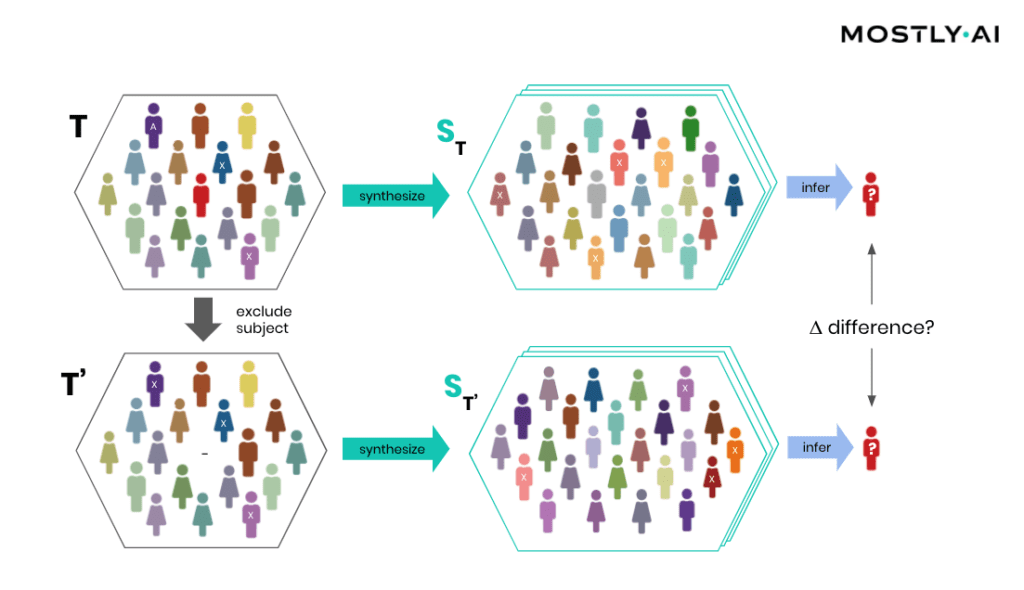
At this point, it is important to emphasize that it’s the explicit goal of a synthesizer to retain as much information as possible. And a high predictive accuracy of an ML model trained on synthetic data is testimony to its retained utility and thus value, and in itself not a risk of attribute disclosure. However, these inferences must be robust, meaning that they must not be susceptible to the influence of any single individual, no matter how much that individual conforms or does not conform to the remaining population. The bonus: any statistics, any ML model, any insights derived from MOSTLY AI’s anonymous synthetic data comes out-of-the-box with the added benefit of being robust. The following evaluation results table for the contraceptive method choice dataset from the technical assessment report further supports this argument.
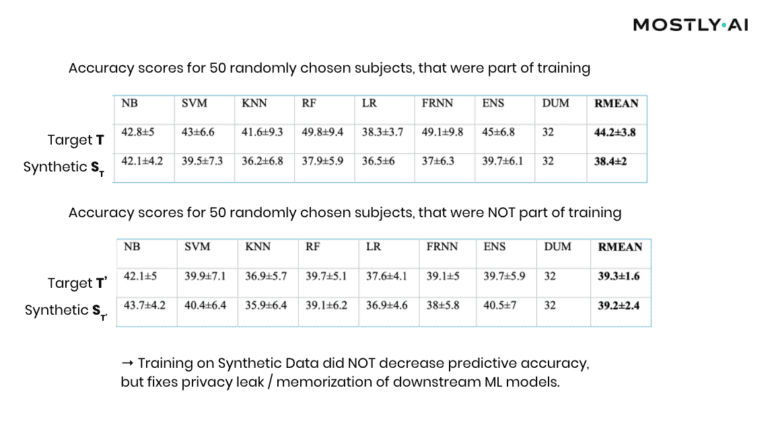
As can be seen, training standard machine learning models on actual data tends to be sensitive towards the inclusion of individual subjects (compare the accuracy of T vs. T’), which shows that the model has memorized its training data, and thus privacy has been leaked into the model parameters. On the other hand, training on MOSTLY AI’s synthetic data is NOT sensitive to individuals (compare ST with ST’). Thus, using synthetic data prevents the privacy leak / the overfitting of this broad range of ML models to actual data while remaining at the same level of predictive accuracy for holdout records.
Similarity-based privacy tests
While the previously presented framework allows for the systematic assessment of the (in)sensitivity of a synthetic data solution with respect to individual outliers, its leave-one-out approach does come with significant computational costs that make it unfortunately infeasible to be performed for each and every synthesis run. However, strong privacy tests have been developed based on the similarity of synthetic and actual data subjects, and we’ve made these an integral part of MOSTLY AI. Thus, every single time a user performs a data synthesis run, the platform conducts several fully automated tests for potential privacy leakage to help confirm the continuous valid working of the system.
Simply speaking, synthetic data shall be as close as possible, but not too close to actual data. So, accuracy and privacy, can both be understood as concepts of (dis)similarity, with the key difference being that the former is measured at an aggregate level and the latter at an individual level. But, what does it mean for a data record to be too close? How can one detect whether synthetic records are indeed statistical representations as opposed to overfitted/memorized copies of actual records? Randomly selected actual holdout records can help answer these questions by serving as a proper reference since they stem from the same target distribution but have not been seen before. Ideally, the synthetic subjects are indistinguishable from the holdout subjects, both in terms of their matching statistical properties, and their dissimilarity to the exposed training subjects. Thus, while synthetic records shall be as close as possible to the training records, they must not be any closer to them than what would be expected from the holdout records, as this would indicate that individual-level information is leaked rather than general patterns learned.
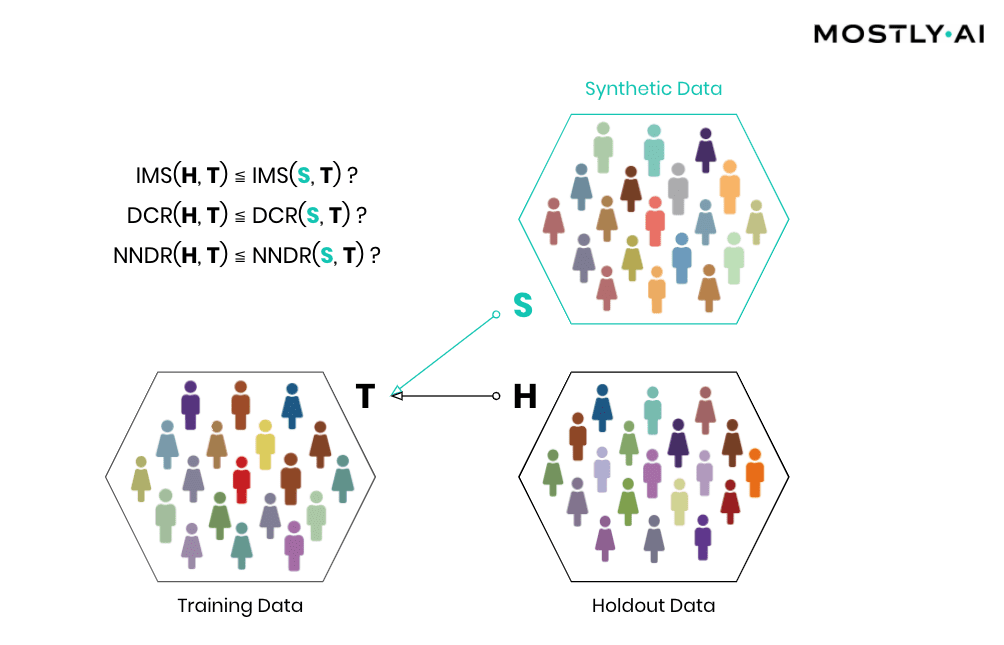
Then, how can the individual-level similarity of two datasets be quantified? A first, natural candidate is to investigate the number, respectively the share, of identical matches between these (IMS = identical match share). We thus have statistical tests automatically be performed that verify that the synthetic dataset does not have significantly more matches with the training data than what would be expected from a holdout data.
Important: the existence of identical matches within a synthetic dataset is in itself not an indicator for a privacy leak but rather needs to be assessed in the context of the dataset, as is done with our statistical tests. E.g., a dataset that exhibits identical matches within the actual data itself, shall also have a similar share of identical matches with respect to the synthetic data. Analogous to that metaphorical monkey typing the complete works of William Shakespeare by hitting random keys on a typewriter for an infinite time, any random data generator will eventually end up generating any data records, including the full medical history of yours. However, as there is no indication which of the generated data points actually exist and which not, the occurrence of such matches in a sea of data is of no use to an attacker. Yet further, these identical matches must NOT be removed from the synthetic output, as such a filter would 1) distort the resulting distributions, but more importantly 2) would actually leak privacy, as it would reveal the presence of a specific record in the training data by it being absent from a sufficiently large synthetic dataset!
But one has to go further and not only consider the dissimilarity with respect to exact matches but also with respect to the overall distribution of their distance to closest records (DCR). Just adding noise to existing data in a high-dimensional data space does not provide any protection, as has been laid out in the seminal Netflix paper on reidentification attacks (see also Part I). Taking your medical record, and changing your age by a couple of years, still leaks your sensitive information and makes that record re-identifiable, despite the overall record not being an exact match anymore. Out of an abundance of caution and to provide the strictest guarantees, one, therefore, shall demand that a synthetic record is not systematically any closer to an actual training record than what is again expected from an actual holdout record. On the other hand, if similar patterns occur within the original data across subjects, then the same (dis-)similarity shall be present also within the synthetic data. Whether the corresponding DCR distributions are significantly different can then be checked with statistical tests that compare the quantiles of the corresponding empirical distribution functions. In case the test fails, the synthetic data shall be rejected, as it is too close to actual records, and thus information on real individuals can potentially be obtained by looking for near matches within the synthetic population.
While checking for DCR is already a strong test, it comes with the caveat of measuring closeness in absolute terms. However, the distance between records can vary widely across a population, with Average Joes having small DCRs and Weird Willis (=outliers) having very large DCRs. E.g., if Weird Willi is 87 years old, has 8 kids, and is 212 cm tall, then shifting his height by a couple of centimeters will do little for his privacy. We have therefore developed an advanced measure that normalizes the distance to the closest record with respect to the overall density within a data space region, by dividing it by the distance to the 2nd closest record. This concept is known as the Nearest Neighbor Distance Ratio (NNDR) and is fortunately straightforward to compute. By checking that the NNDRs for synthetic records are not systematically any closer than expected from holdout records, one can thus provide an additional test for privacy that also protects the typically most vulnerable individuals, i.e., the outliers within a population. In any case, all tests (IMS, DCR, and NNDR) for a synthetic dataset need to pass in order to be considered anonymous.
Conclusion
We founded MOSTLY AI with the mission to foster an ethical data and AI ecosystem, with privacy-respecting synthetic data at its core. And today, we are in an excellent position to enable a rapidly growing number of leading-edge organizations to safely collaborate on top of their data for good use, to drive data agility as well as customer understanding, and to do so at scale. All while ensuring core values and fundamental rights of individuals remain fully protected.
Anonymization is hard - synthetic data is the solution. MOSTLY AI's synthetic data platform is the world’s most accurate and most secure offering in this space. So, reach out to us and learn more about how your organizations can reap the benefits of their data assets, while knowing that their customers’ trust is not put at any risk.
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
The very first question commonly asked with respect to Synthetic Data is: how accurate is it? Seeing, then, the unparalleled accuracy of MOSTLY AI's synthetic data platform in action, resulting in synthetic data that is near indistinguishable from real data, typically triggers the second, just as important question: is it really private? In this blog post series we will dive into the topic of privacy preservation, both from a legal as well as a technical perspective, and explain how external assessors unequivocally come to the same conclusion: MOSTLY AI generates truly anonymous synthetic data, and thus any further processing, sharing or monetization becomes instantly compliant with even the toughest privacy regulations being put in place these days.
What is anonymous data? A historical perspective
So, what does it mean for a dataset to be considered private in the first place? A common misconception is that any dataset that has its uniquely identifying attributes removed is thereby made anonymous. However, the absence of these so-called “direct identifiers”, like the full names, the e-mail addresses, the social security numbers, etc., within a dataset provides hardly any safety at all. The simple composition of multiple attributes taken together is unique and thus allows for the re-identification of individual subjects. Such attributes that are not direct identifiers by themselves, but only in combination, are thus termed quasi-identifiers. Just how easy this re-identification is, and how few attributes are actually required, came as a surprise to a broader audience when Latanya Sweeney published her seminal paper entitled “Simple Demographics Often Identify People Uniquely” in the year 2000. In particular, because her research was preceded by the successful re-identification of publicly available highly sensitive medical records, that were supposedly anonymous. Notably, the simple fact that zip code, date-of-birth, and gender in combination are unique to 87% of the US population, served as an eye-opener for policy-makers and researchers alike. And as a direct result of Sweeney’s groundbreaking work, privacy regulations were adapted to provide extra safety. For instance, the HIPAA privacy rule that covers the handling of health records in the US was passed in 2003, and explicitly lists a vast number of attributes (incl. any dates), that are all to be removed to provide safety (see footnote 15 here). Spurred by the discovery of these risks in methods then considered state-of-the-art anonymization, researchers continued their quest for improved de-identification methods and privacy guarantees, based on the concept of quasi-identifiers and sensitive attributes.
However, the approach ultimately had to hit a dead end, because any seemingly innocuous piece of information, that is related to an individual subject, is potentially sensitive, as well as serves as a quasi-identifier. And with more and more data points being collected, there is no escape from adversaries combining all of these with ease to single out individuals, even in large-scale datasets. The futility of this endeavor becomes even more striking once you realize that it’s a hard mathematical law that one attempts to compete with: the so-called curse of dimensionality. The number of possible outcomes grows exponentially with the number of data points per subject, and even for modestly sized databases quickly surpasses the number of atoms in the universe. Thus, with a continuously growing number of data points collected, any individual in any database is increasingly distinctive from all others and therefore becomes susceptible to de-anonymization.
The consequence? Modern-day privacy regulations (GDPR, CCPA, etc.) provide stricter definitions of anonymity. They consider data to be anonymous if and only if none of the subjects are re-identifiable, neither directly nor indirectly, neither by the data controller nor by any third party (see GDPR §4.1). They do soften the definition, requiring that the re-identification attack needs to be reasonably likely to be performed (see GDPR Recital 26 or CCPA 1798.140(o)). However, these clauses clearly do NOT exempt from considering the most basic and thus reasonable form, the so-called linkage attacks, that simply require 3rd party data to be joined for a successful de-anonymization. And it was simple linkage attacks, that lead to the re-identification of Netflix users, the re-identification of NY taxi trips, the re-identification of telco location data, the re-identification of credit card transactions, the re-identification of browsing data, the re-identification of health care records, and so forth.
A 2019 Nature paper thus had to conclude:
“[..] even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR and seriously challenge the technical and legal adequacy of the de-identification release-and-forget model.”
Gartner projects that by 2023, 65% of the world’s population will have its personal information covered under modern privacy regulations, up from 10% today with the European GDPR regulation becoming the de-facto global standard.
True anonymization today is almost impossible with old tools

And while thousands, rather millions of bits are being collected about each one of us on a continuous basis, only 33 bits of information turn out to be sufficient to re-identify each individual among a global population of nearly 8 billion people. This gap between how much data is captured and how much information can be at most retained is widening by the day, making it an ever-more pressing concern for any organization dealing with privacy-sensitive data.
In particular, as this limitation is true for any of the existing techniques, and for any real-world customer data asset, as has already been conjectured in the seminal 2008 paper on de-anonymizing basic Netflix ratings:
“[..] the amount of perturbation that must be applied to the data to defeat our algorithm will completely destroy their utility [..] Sanitization techniques from the k-anonymity literature such as generalization and suppression do not provide meaningful privacy guarantees, and in any case fail on high-dimensional data.”
So, true anonymization is hard. Is this the end of privacy? No! But we will need to move beyond mere de-identification. Enter synthetic data. Truly anonymous synthetic data.
Head over to Part II of our blog post series to dive deeper into the privacy of synthetic data, and how it can be assessed.
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
Last Thursday the European Court of Justice published their verdict on the so-called Schrems II case: See the full ECJ Press Release or The Guardian for a summary. In essence, the ECJ invalidated with immediate effect the EU-US Privacy Shield and clarified the obligations for companies relying on Standard Contractual Clauses (SCC) for cross-border data sharing. This verdict, the culmination of a year-long legal battle between data privacy advocates, national data protection authorities, and Facebook, came to many observers as a surprise. In particular, as the Privacy Shield has been established as a response to yet another ECJ ruling made in 2015, that already recognized the danger of US surveillance for EU citizens (see here for a timeline of events). However, the ECJ makes the case that the Privacy Shield is not effective in protecting the personal data of European citizens, a recognized fundamental right, in particular with respect to (known or unknown) data requests by US intelligence agencies, like the NSA.
Let’s take a step back: Personal data is protected within the EU based on the General Data Protection Regulation (GDPR) and other previous regulations (e.g. Charter of Fundamental Rights). With this unified regulation, it is relatively easy to move personal data across borders within the European Union. However, data transfer to a third country, in principle, may only take place if the third country in question ensures an adequate level of data protection. The data exporter needs to ensure that this adequate level of data protection is given. Because this is difficult and cumbersome to do on an individual basis, the data transfer to the US has been granted a particular exemption via the EU-US Privacy Shield in 2016. It is this exemption that has now been recognized as being invalid from its beginning.
Max Schrems, privacy advocate and party in the case, expressed relief and satisfaction in a first reaction to this verdict. The non-profit organization NOYB, which he founded, shared their view on the ruling in their first reaction. In particular, the clear call to action towards national Data Protection Authorities was highly welcomed, as the GDPR relies on these in order to be truly effective. Several privacy law firms followed suit over the last couple of days and published their perspectives. E.g., Taylor Wessing also emphasizes that while standard contract clauses remain valid, they are not to be seen as a "panacea”. The obligations to assess the legality of a cross-border data transfer remain with the data exporter and data importer and need to be studied on a case-by-case basis, which typically incurs significant costs, time, as well as legal risks. As it has been shown by the ECJ verdict itself, even the European Commission was proven to be wrong in terms of their judgment when negotiating the Privacy Shield in the first place.
Bottom line is that this ruling will make it even more difficult for organizations to legally share any personal data of EU citizens from the EU to the US, as well as to other third countries. This impacts the sharing of customer data just as well as employee’s data for multinational organizations. And this ruling comes on top of a global trend towards tighter data sovereignty and data localization laws taking effect (see here).
All that being said, it is important to remember that none of this applies to non-personal data. While most existing anonymization techniques need to destroy vast amounts of information in order to prevent re-identification, it is the unique value proposition of synthetic data that finally allows for information to flow freely at granular level as needed, without infringing individuals’ fundamental right for privacy. Rather than sharing the original, privacy-sensitive data, organizations can thus share statistically representative data and circumvent the restrictions on personal data.
Our economy increasingly depends on the free flow of information. It’s broadly recognized, and yet, at the same time, the need for strong privacy is more important than ever before. Synthetic data is a solution that offers a viable way out of this dilemma.