TL;DR: Synthetic financial data is the fuel banks need to become AI-first and to create cutting-edge services. In this report, you can read about:
- banking technology trends in 2022 from superapps to personalized digital banking
- data privacy legislations affecting the banking industry in 2022
- the challenges in AI/ML development, testing and data sharing that synthetic data can solve
- the most valuable data science and synthetic data use cases in banking: customer acquisition and advanced analytics, mortgage analytics, credit decisioning and limit assessment, risk management and pricing, fraud and anomaly detection, cybersecurity, monitoring and collections, churn reduction, servicing and engagement, enterprise data sharing, and synthetic test data for digital banking product development
- synthetic data engineering: how to integrate synthetic data in financial data architectures
Table of Contents
- Banking technology trends
- The state of data privacy in banking in 2022
- The most valuable synthetic data use cases in banking
- Synthetic data for AI, advanced analytics, and machine learning
- Synthetic data for enterprise data sharing
- Synthetic test data for digital banking products
- How to integrate synthetic data generators into financial systems?
- The future of financial data
Banks and financial institutions are aware of their data and innovation gaps and AI-generated synthetic data is their best bet. According to Gartner:
By 2030, 80 percent of heritage financial services firms will go out of business, become commoditized or exist only formally but not competing effectively.
A pretty dire prophecy, but nonetheless realistic, with small neobanks and big tech companies eyeing their market. There is no way to run but forward.
The future of banking is all about becoming AI-first and creating cutting-edge digital services coupled with tight cybersecurity. In the race to a tech-forward future, most consultants and business prophets forget about step zero: customer data. In this blog post, we will give an overview of the data science use cases in banking and attempt to offer solutions throughout the data lifecycle. We'll concentrate on the easiest to deploy and highest value synthetic data use cases in banking. We'll cover three clusters of synthetic data use cases: data sharing, AI, advanced analytics, machine learning, and software testing. But before we dive into the details, let's talk about the banking trends of today.
Banking technology trends
The pandemic accelerated digital transformation, and the new normal is here to stay. According to Deloitte, 44% of retail banking customers use their bank's mobile app more often. At Nubank, a Brazilian digital bank, the number of accounts rose by 50%, going up to 30 million. It is no longer the high-street branch that will decide the customer experience. Apps become the new high-touch, flagship branches of banks where the stakes are extremely high. If the app works seamlessly and offers personalized banking, customer lifetime value increases. If the app has bugs, frustration drives customers away. Service design is an excellent framework for creating distinctive personalized digital banking experiences. Designing the data is where it should all start.
A high-quality synthetic data generator is one mission-critical piece of the data design tech stack. Initially a privacy-enhancing technology, synthetic data generators can generate representative copies of datasets. Statistically the same, yet none of the synthetic data points match the original. Beyond privacy, synthetic data generators are fantastic data augmentation tools too. Synthetic data is the modeling clay that makes this data design process possible. Think moldable test data and training data for machine learning models based on real production data.
Download the Banking on synthetic data ebook!
Hands on advice from industry experts and a complete collection of synthetic data use cases in banking.
The rise of superapps is another major trend financial institutions should watch out for. Building or joining such ecosystems makes absolute sense if banks think of them as data sources. Data ecosystems are also potential spaces for customer acquisition. With tech giants entering the market with payment and retail banking products, data protectionism is rising. However, locking up data assets is counterproductive, limiting collaboration and innovation. Sharing data is the only way to unlock new insights. Especially for banks, whose presence in their customers' lives is not easy to scale unless via collaborations and new generation digital services. Insurance providers and telecommunications companies are the first obvious candidates. Other beyond-banking service providers could also be great partners, from car rental companies to real estate services, legal support, and utility providers. Imagine a mortgage product that comes with a full suite of services needed throughout a property purchase. Banks need to create a frictionless, hyper-personalized customer experience to harness all the data that comes with it.
Another vital part of this digital transformation story is AI adoption. In banking, it's already happening. According to McKinsey,
"The most commonly used AI technologies (in banking) are: robotic process automation (36 percent) for structured operational tasks; virtual assistants or conversational interfaces (32 percent) for customer service divisions; and machine learning techniques (25 percent) to detect fraud and support underwriting and risk management."
It sounds like banks are running full speed ahead into an AI future, but the reality is more complicated than that. Due to the legacy infrastructures of financial institutions, the challenges are numerous. Usually, there is no clear strategy or fragmented ones with no enterprise-wide scale. Different business units operate almost completely cut off with limited collaboration and practically no data sharing. These fragmented data assets are the single biggest obstacle to AI adoption. McKinsey estimates that AI technologies could potentially deliver up to $1 trillion of additional value in banking each year. It is well worth the effort to unlock the data AI and machine learning models so desperately need. Let's take a look at the number one reason or rather excuse banks and financial institutions hide behind when it comes to AI/AA/ML innovation: data privacy.
The state of data privacy in banking in 2022
Banks have always been the trustees of customer privacy. Keeping data and insights tightly secured has prevented banks from becoming data-centric institutions. What's more, an increasingly complex and restrictive legislative landscape makes it difficult to comply globally.
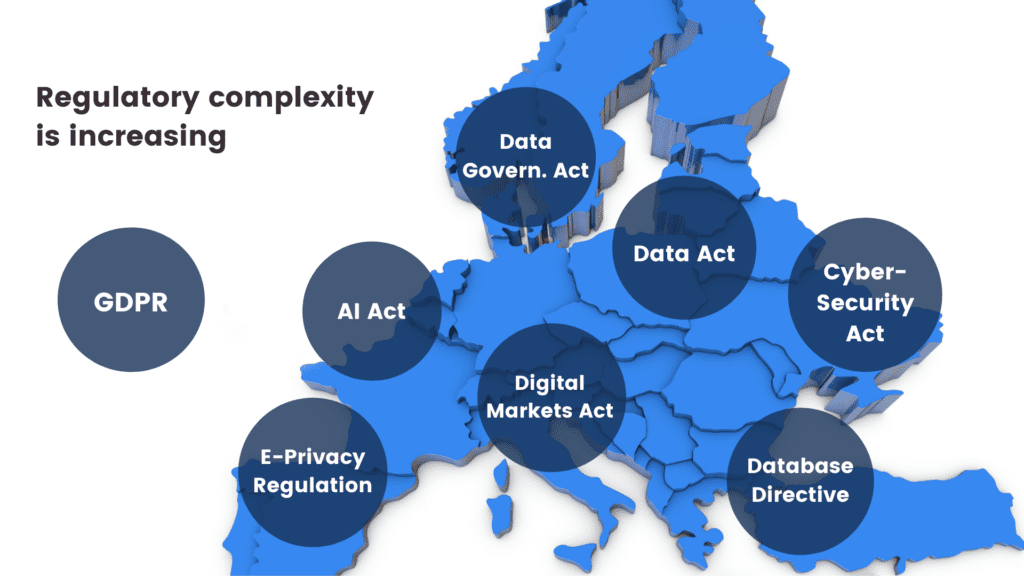
Let’s be clear. The ambition to secure customer data is the right one. Banks must take security seriously, especially in an increasingly volatile cybersecurity environment. However, this cannot take place at the expense of innovation. The good news is that there are tools to help. Privacy-enhancing technologies (PETs) are crucial ingredients of a tech-forward banking capability stack. It's high time for banking executives, CIOs, and CDOs to get rid of their digital banking blindspots. Banks must stop using legacy data anonymization tools that endanger privacy and hinder innovation. Data anonymization methods, like randomization, permutation, and generalization, carry a high risk of re-identification or destroy data utility.
Maurizio Poletto, Chief Platform Officer at Erste Group Bank AG, said in The Executive's Guide to Accelerating Artificial Intelligence and Data Innovation with Synthetic Data:
"In theory, in banking, you could take real account data, scramble it, and then put it into your system with real numbers, so it's not traceable. The problem is that obfuscation is nice, and anonymization is nice, but you can always find a way to get the original data back. We need to be thorough and cautious as a bank because it is sensitive data. Synthetic data is a good way to continue to create value and experiment without having to worry about privacy, particularly because society is moving toward better privacy. This is just the beginning, but the direction is clear."
Modern PETs include AI-generated synthetic data, homomorphic encryption, or federated learning. They offer the way out of the data dilemma in banking. Data innovators in banking should choose the appropriate PET for the appropriate use case. Encryption solutions should be looked at when necessary to unencrypt the original data. Anonymized computation, such as federated learning, is a great choice when models can get trained on users' mobile phones. AI-generated synthetic data is the most versatile privacy-enhancing technology with just one limitation. Synthetic datasets generated by AI models trained on original data cannot be reverted back to the original. Synthetic datasets are statistically identical to the original datasets they were modeled on. However, there is no 1:1 relationship between the original and the synthetic data points. This is the very definition of privacy. As a result, AI-generated synthetic data is great for specific use cases—advanced analytics, AI and machine learning training, software testing, and sharing realistic but unencryptable datasets. Synthetic data is not a good choice for use cases where the data needs to be reverted back to the original, such as information sharing for anti-money laundering purposes, where perpetrators need to be re-identified. Let's look at a comprehensive overview of the most valuable synthetic data use cases in banking!
The most valuable synthetic data use cases in banking
Synthetic data generators come in many shapes and forms. In the following, we will be referring to MOSTLY AI's synthetic data generator. It is the market-leading synthetic data solution able to generate synthetic data with high accuracy. MOSTLY AI's synthetic data platform comes with advanced features, such as direct database connection and the ability to synthesize complex data structures with referential integrity. As a result, MOSTLY AI can serve the broadest range of use cases with suitably generated synthetic data. In the following, we will detail the lowest hanging synthetic data fruits in banking. These are the use cases we have seen to work well in practice and generate a high ROI.
| CHALLENGES | HOW CAN SYNTHETIC DATA HELP? |
|---|---|
AI/AA/ML
|
|
TESTING
|
|
DATA SHARING
|
|
Synthetic data for AI, advanced analytics, and machine learning
Synthetic data for AI/AA/ML is one of the richest use case categories with many high-value applications. According to Gartner, by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated. Machine learning and AI unlocks a range of business benefits for retail banks.
- Advanced analytics improves customer acquisition by optimizing the marketing engine with hyper-personalized messages and precise next best actions.
- Intelligence from the very first point of contact increases customer lifetime value.
- Operating costs will be lower if decision-making in acquisition and servicing is supported with well-trained machine learning algorithms. Lower credit risk is also a benefit that comes from early detection of behaviors that signal a higher risk of default.
Automated, personalized decisions across the entire enterprise can increase competitiveness. The data backbone, the appropriate tools, and talent need to be in place to make this happen. Synthetic data generation is one of those capabilities essential for an AI-first bank to develop. The reliability and trustworthiness of AI is a neglected issue. According to Gartner:
65% of companies can't explain how specific AI model decisions or predictions are made. This blindness is costly. AI TRiSM tools, such as MOSTLY AI's synthetic data platform, provide the Trust, Risk and Security Management needed for effective explainability, ModelOps, anomaly detection, adversarial attack resistance and data protection. Companies need to develop these new capabilities to serve new needs arising from AI adoption.
From explainability to performance improvement, synthetic data generators are one of the most valuable building tools. Data science teams need synthetic data to succeed with AI and machine learning use cases. Here is how to use synthetic data in the most common AI banking applications.
CUSTOMER ACQUISITION AND ADVANCED ANALYTICS
CRM data is the single most valuable data asset for customer acquisition and retention. A wonderful, rich asset that holds personal data and behavioral data of the bank's future prospects. However, due to privacy legislation, up to 80% of CRM data tends to be locked away. Compliant CRM data for advanced analytics and machine learning applications is hard to come by. Banks either comply with regulations and refrain from developing a modern martech platform altogether or break the rules and hope to get away with it. There is a third option. Synthetic customer data is as good as real when it comes to training machine learning models. Insights from these type of analytics can help identify new prospects and improve sign-up rates significantly.
MORTGAGE ANALYTICS, CREDIT DECISIONING AND LIMIT ASSESSMENT
AI in lending is a hot topic in finance. Banks want to reach out to the right people with the right mortgage and credit products. In order to increase precision in targeting, a lot of personal data is needed. The more complete the customer data profile, the more intelligent mortgage analytics becomes. Better models bring lower risk both for the bank and for the customer. Rule-based or logistic regression models rely on a narrow set of criteria for credit decision-making. Banks without advanced behavioral analytics and models underserve a large segment of customers. People lacking formal credit histories or deviating from typical earning patterns are excluded. AI-first banks utilize huge troves of alternative data sources. Modern data sources include social media, browsing history, telecommunications usage data, and more. However, using these highly personal data sources in their original for training AI models is often a challenge. Legacy data anonymization techniques destroy the very insights the model needs. Synthetic data versions retain all of these insights. Thanks to the granular, feature-rich nature of synthetic data, lending solutions can use all the intelligence.
RISK MANAGEMENT AND PRICING
Pricing and risk prediction models are some of the most important models to get right. Even a small improvement in their performance can lead to significant savings and/or higher revenues. Injecting additional domain knowledge into these models, such as synthetic geolocation data or synthetic text from customer conversations, significantly improves the model's ability to quantify a customer's propensity to default. MOSTLY AI's ability to provide the accuracy needed to generate synthetic geolocation data has been proven already. Synthetic text data can be used for training machine learning models in a compliant way on transcripts of customer service interactions. Virtual loan officers can automate the approval of low-risk loans reliably.
It is also mission-critical to be able to provide insight into the behavior of these models. Local interpretability is the best approach for explainable AI today, and synthetic data is a crucial ingredient of this transparency.
FRAUD AND ANOMALY DETECTION
Fraud is one of the most interesting AI/ML use cases. Fraud and money laundering operations are incredibly versatile, getting more and more sophisticated every day. Adversaries are using a lot of automation too to find weaknesses in financial systems. It's impossible to keep up with rule-based systems and manual follow-ups. False positives cost a lot of money to investigate, so it's imperative to continuously improve precision aided with machine learning models. To make matters even more challenging, fraud profiles vary widely between banks. The same recipe for catching fraudulent transactions might not work for every financial institution. Using machine learning to detect fraud and anomaly patterns for cybersecurity is one of the first synthetic data use cases banks usually explore. The fraud detection use case goes way beyond privacy and takes advantage of the data augmentation possibility during synthesization. Maurizio Poletto, CPO at Erste Group Bank, recommends synthetic data upsampling to improve model performance:
Synthetic data can be used to train AI models for scenarios for which limited data is available—such as fraud cases. We could take a fraud case using synthetic data to exaggerate the cluster, exaggerate the amount of people, and so on, so the model can be trained with much more accuracy. The more cases you have, the more detailed the model can be.
Training and retraining models with synthetic data can improve fraud detection model performance, leading to valuable savings on investigating false positives.
MONITORING AND COLLECTIONS
Transaction analysis for risk monitoring is one of the most privacy-sensitive AI use cases banks need to be able to handle. Apart from traditional monitoring data, like repayment history and credit bureau reports, banks should be looking to utilize new data sources, such as time-series bank data, complete transaction history, and location data. Machine learning models trained with these extremely sensitive datasets can reliably microsegment customers according to value at risk and introduce targeted interventions to prevent defaults. These highly sensitive and valuable datasets cannot be used for AI/ML training without effective anonymization. MOSTLY AI's synthetic data generator is one of the best on the market when it comes to synthesizing complex time-series, behavioral data, like transactions with high accuracy. Behavioral synthetic data is one of the most difficult synthetic data categories to get right, and without a sophisticated AI engine, like MOSTLY AI's, results won't be accurate enough for such use cases.
CHURN REDUCTION, SERVICING, AND ENGAGEMENT
Another high-value use case for synthetic behavioral data is customer retention. A wide range of tools can be put to good use throughout a customer's lifetime, from identifying less engaged customers to crafting personalized messages and product offerings. The success of those tools hinges on the level of personalization and accuracy the initial training data allows. Machine learning models are the most powerful at pattern recognition. ML's ability to identify microsegments no analyst would ever recognize is astonishing, especially when fed with synthetic transaction data. Synthetic data can also serve as a bridge of intelligence between different lines of business: private banking and business banking data can be a powerful combination to provide further intelligence, but strictly in synthetic form. The same applies to national or legislative borders: analytics projects with global scope can be a reality when the foundation is 100% GDPR compliant synthetic data.
ALGORITHMIC TRADING
Financial institutions can use synthetic data to generate realistic market data for training and validating algorithmic trading models, reducing the reliance on historical data that may not always represent future market conditions. This can lead to improved trading strategies and increased profitability.
STRESS TESTING
Banks can use synthetic data to create realistic scenarios for stress testing, allowing them to evaluate their resilience to various economic and financial shocks. This helps ensure the stability of the financial system and boosts customer confidence in the institution's ability to withstand adverse conditions.
Synthetic data for enterprise data sharing
Open financial data is the ultimate form of data sharing. According to McKinsey, economies embracing financial data sharing could see GDP gains of between 1 and 5 percent by 2030, with benefits flowing to consumers and financial institutions. More data means better operational performance, better AI models, more powerful analytics, and customer-centric digital banking products facilitating omnichannel experiences. The idea of open data cannot become a reality without a robust, accurate, and safe data privacy standard shared by all industry players in finance and beyond. This is a vision shared by Erste Group Bank's Chief Platform Officer:
Imagine if we in banking use synthetic data to generate realistic and comparable data from our customers, and the same thing is done by the transportation industry, the city, the insurance company, and the pharmaceutical company, and then you give all this data to someone to analyze the correlation between them. Because the relationship between well-being, psychological health, and financial health is so strong, I think there is a fantastic opportunity around the combination of mobility, health, and finance data.
It's an ambitious plan, and like all grand designs, it's best to start building the elements early. At this point, most banks are still struggling with internal data sharing with distinct business lines acting as separate entities and being data protectionist when open data is the way forward. Banks and financial institutions share little intelligence, citing data privacy and legislation as their main concern. However, data sharing might just become an obligation very soon with the EU putting data altruism on the map in the upcoming Data Governance Act. While sharing personal data will remain strictly forbidden and increasingly so, anonymized data sharing will be expected of companies in the near future. In the U.S., healthcare insurance companies and service providers are already legally bound to share their data with other healthcare providers. The same requirement makes a lot of sense in banking too where so much depends on credit history and risk prediction. While some data is shared, intelligence is still withheld. Cross-border data sharing is also a major challenge in banking. Subsidiaries either operate in a completely siloed way or share data illegally. According to Axel von dem Bussche, Partner at Taylor Wessing and IT lawyer, as much as 95% of international data sharing is illegal due to the destruction of the EU-US Privacy Shield by the Schrems II decision.
Some organizations fly analysts and data scientists to the off-shore data to avoid risky and forbidden cross-border data sharing. It doesn't have to be this complicated. Synthetic data sharing is compliant with all privacy laws across the globe. Setting up synthetic data sandboxes and repositories can solve enterprise-wide data sharing across borders since synthetic data does not qualify as personal data. As a result, it is out of scope of GDPR and the infamous Schrems II. ruling, which effectively prohibited all sharing of personal data outside the EU.
Third-party data sharing within the same legislative domain is also problematic. Banks buy many third-party AI solutions from vendors without adequately testing the solutions on their own data. The data used in procurement processes is hard to get, causing costly delays and heavily masked to prevent sensitive data leaks through third parties. The result is often bad business decisions and out-of-the-box AI solutions that fail to deliver the expected performance. Synthetic data sandboxes are great tools for speeding up and optimizing POC processes, saving 80% of the cost.
Synthetic test data for digital banking products
One of the most common data sharing use cases is connected to developing and testing digital banking apps and products. Banks accumulate tons of apps, continuously developing them, onboarding new systems, and adding new components. Manually generated test data for such complex systems is a hopeless task, and many revert to the old dangerous habit of using production data for testing systems. Banks and financial institutions tend to be more privacy-conscious, but their solutions to this conundrum are still suboptimal. Time and time again, we see reputable banks and financial institutions roll out apps and digital banking services after only testing them with heavily masked or manually generated data. One-cent transactions and mock data generators won't get you far when customer expectations for seamless digital experiences are sky-high.
To complicate things further, complex application development is rarely done in-house. Data owners and data consumers are not the same people, nor do they have the full picture of test scenarios and business rules. Labs and third-party dev teams rely on the bank to share meaningful test data with them, which simply does not happen. Even if testing is kept in-house, data access is still problematic. While in other, less privacy-conscious industries, developers and test engineers use radioactive test data in non-production environments, banks leave testing teams to their own devices. Manual test data generation with tools like Mockaroo and the now infamous Faker library misses most of the business rules and edge cases so vital for robust testing practices. Dynamic test users for notification and trigger testing are also hard to come by. To put it simply, it's impossible to develop intelligent banking products without intelligent test data. The same goes for the testing of AI and machine learning models. Testing those models with synthetically simulated edge cases is extremely important to do when developing from scratch and when recalibrating models to avoid drifting. Models are as good as the training data, and testing is as good as test data. Payment applications with or without personalized money management solutions need the synthetic approach: realistic synthetic test data and edge case simulations with dynamic synthetic test users. Synthetic test data is fast to generate and can create smaller or larger versions of the same dataset as needed throughout the testing pyramid from unit testing, through integration testing, UI testing to end-to-end testing.
Erste Bank's main synthetic data use case is test data management. The bank is creating synthetic segments and communities, building new features, and testing how certain types of customers would react to these features.
Normally, the data we use is static. We see everything from the past. But features like notifications and triggers—like receiving a notification when your salary comes in—can only be tested with dynamic test users. With synthetic data, you push a button to generate that user with an unlimited number of transactions in the past and a limited number of transactions in the future, and then you can put into your system a user which is alive.
These live, synthetic users can stand in for production data and provide a level of realism unheard of before while protecting customers' privacy. The Norwegian Data Protection Authority issued a fine for using production data in testing, adding that using synthetic data instead would have been the right course to take.
Testing is becoming a continuous process. Deploying fast and iterating early is the new mantra of DevOps teams. Setting up CI/CD (continuous integration and delivery) pipelines for continuous testing cannot happen without a stable flow of high-quality test data. Synthetic data generators trained on real data samples can provide just that – up-to-date, realistic, and flexible data generation on-demand.
How to integrate synthetic data generators into financial systems?
First and foremost, it's important to understand that not all synthetic data generators are created equal. It's particularly important to select the right synthetic data vendor who can match the financial institution's needs. If a synthetic data generator is inaccurate, the resulting synthetic datasets can lead your data science team astray. If it's too accurate, the generator overfits or learns the training data too well and could accidentally reproduce some of the original information from the training data. Open-source options are also available. However, the control over quality is fairly low. Until a global standard for synthetic data arrives, it's important to proceed with caution when selecting vendors. Opt for synthetic data companies, which already have extensive experience with sensitive financial data and know-how to integrate synthetic data successfully with existing infrastructures.
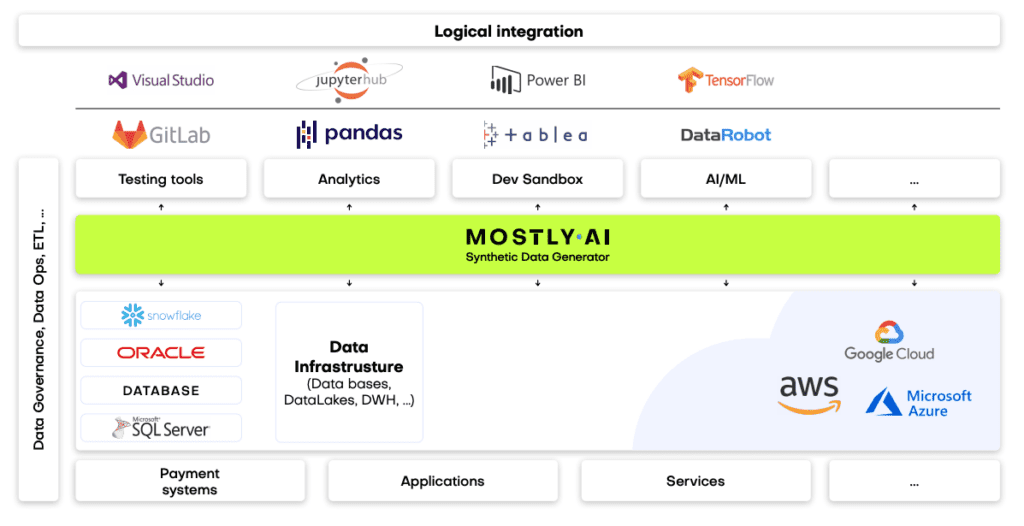
The future of financial data is synthetic
Our team at MOSTLY AI is working with large banks and financial organizations very closely. We know that synthetic data will be the data transformation tool that will change the financial data landscape forever, enabling the flow and agility necessary for creating competitive digital services. While we know that the direction is towards synthetic data across the enterprise, we know full well how difficult it is to introduce new technologies and disrupt the status quo in enterprises, even if everyone can see the benefits. One of the most important tasks of anyone looking to make a difference with synthetic data is to prioritize use cases in accordance with the needs and possibilities of the organization. Analytics use cases with the biggest impact can serve as flagship projects, establishing the foundations of synthetic data adoption. In most organizations, mortgage analytics, pricing, and risk prediction use cases can generate the highest immediate monetary value, while synthetic test data can massively accelerate the improvement of customer experience and reduce compliance and cybersecurity risk. It's good practice to establish semi-independent labs for experimentation and prototyping: Erste Bank's George Lab is a prime example of how successful digital banking products can be born of such ventures. The right talent is also a crucial ingredient of success. According to Erste Bank's CPO, Maurizio Poletto:
Talented data engineers want to spend 100% of their time in data exploration and value creation from data. They don't want to spend 50% of their time on bureaucracy. If we can eliminate that, we are better able to attract talent. At the moment, we may lose some, or they are not even coming to the banking industry because they know it's a super-regulated industry, and they won't have the same freedom they would have in a different industry.
Once you have the attraction of a state-of-the-art tech stack enabling agile data practices, you can start building cross-functional teams and capabilities across the organization. The data management status quo needs to be disrupted, and privacy, security, and data agility champions will do the groundwork. Legacy data architectures keeping banks and financial institutions back from innovating and endangering customers' privacy need to be dealt with soon. The future of data-driven banking is bright, and that future is synthetic.
Synthetic data in banking ebook
Would you like to know more about using synthetic data in banking?
Have you missed the 6th Synthetic Data Meetup? Don't worry, an on-demand video of the event is here! Synthetic data is a game-changer for the simulation of residential energy demand. Watch the 6th Synthetic Data Meetup to learn more about important research our guest speaker, Max Kleinebrahm is working on at the Karlsruhe Institute of Technology, modeling residential energy systems using synthetic data!
What was the 6th Synthetic Data Meetup about?
Models simulating household energy demand based on occupant behavior have received increasing attention over the last years due to the need to better understand fundamental characteristics that shape residential energy.
In this Synthetic Data Meetup, hosted by Dr. Paul Tiwald, Head of Data Science at MOSTLY AI, we have presented deep learning methods ready to capture complex long-term relationships in occupant behavior that can provide high-quality synthetic behavioral data.
The generated synthetic dataset combines various advantages of individual empirically collected data sets and thus enables a better understanding of residential energy demand without collecting new data with great effort.
Our guest speaker was Max Kleinebrahm, Research Assistant at the Chair of Energy Economics at the Karlsruhe Institute of Technology in Germany. Max’s research interests are renewable energies, decentralized energy systems, energy self-sufficient residential buildings, and time series analysis of energy consumption and occupant behavior. In his PhD, he is investigating the dissemination of self-sufficient residential buildings in the future European energy system.
Play the Synthetic Data Meetup video to learn how household energy demand can be simulated with high-quality synthetic behavioral data!
Do you have a question? We are happy to talk synthetic data with you. Please feel free to contact us!
Intro
In part I of this mini-series we outlined the particular challenges for anonymizing behavioral data, and continued in part II with a first real-world case study on transactional e-commerce data. In this post, we will expand the study, present further sequential datasets, and demonstrate the unparalleled accuracy and thus utility of MOSTLY AI’s synthetic data platform for behavioral data. Its ability to retain the valuable statistical information finally allows organizations to meet privacy regulations (and customers’ expectations) and still reap the immense value of their behavioral data assets at scale.
Datasets
These are the datasets of our study:
1. cdnow: 18-month of transaction records for CD purchases from a cohort of 23,570 customers. Each transaction contains information on the date of purchase, the number of CDs, as well as the total transaction amount. The dataset can be obtained from here
2. berka: This is one of the few freely available datasets on retail bank transactions. It has been released by a Czech bank for a machine learning competition in 1999, can be obtained from here, and consists of a bit over 1 million transactions with 6 attributes for a cohort of 4’500 bank customers.

3. gstore: This set contains Google Analytics 360 data and represents site traffic for the Google Merchandise online store. The original dataset can be obtained from here, and contains over 1.6 million visitors, together with 14 of their visit-specific attributes over a 26-month period.

4. insta: This Kaggle dataset consists of 3.2 million orders by over 200’00 grocery customers, with an average basket size of 10.1 items, ordering from a total assortment of 49’677 products across 21 grocery departments.

The following table summarizes the varying range of dataset sizes:
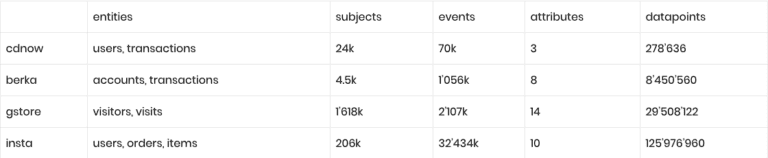
Bear in mind, that these are all drastically limited versions of the underlying real-world data assets. Many of the otherwise available attributes, on subject- as well as on item-level, were held back by data providers in order to anonymize the data. With synthetic data all of the originally available information could have been shared in a privacy-preserving manner.
For each of the four datasets, we used the latest enterprise version of MOSTLY AI's synthetic data platform to create corresponding synthetic versions thereof. With the click of a few buttons we generated hundreds of thousands of synthetic subjects and their data points. All of them being highly realistic, as well as statistically representative of the original data, but fully anonymous.
As we’ve made the case before, behavioral data is all about its inherent sequential structure. Just as a text loses its meaning when words are assembled in random order (see an example with the First Amendment of the US Constitution below), behavioral data loses its value if its composition, its consistency and coherence cannot be retained. Any data synthesization thus needs to ensure that not only representative events, but that representative subjects together with their representative events are being generated.
for freedom or for or of the respecting peaceably no right religion, abridging the make the law and to shall a the of speech, to exercise establishment or of people government grievances. or Congress redress of assemble, thereof; of the the press; an prohibiting petition
With that in mind, we will focus the analysis in this study on the valuable intertemporal relationships.
CDNOW
The customer base of this former online CD store exhibits a broad variety of behavioral patterns. While we have transactions range from zero dollars (presumably promotional offers) to over a thousand dollars, and from 1 to 99 CDs being purchased at a single time, one can expect that customers rather tend to be consistent, and that transactions by the same person are strongly correlated. I.e., a person making a high-value purchase once is likely to do so again. And indeed, as it turns out, this is the case, both when analyzing the original and when analyzing our artificially generated data. The following charts visualize these correlations, as well as the full distribution of the difference between a first and a second transaction amount, and how each of these statistics perfectly aligns between original and synthetic data.
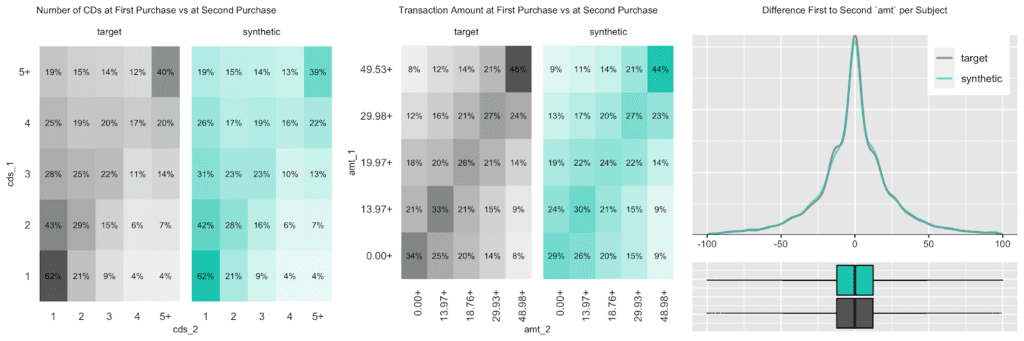
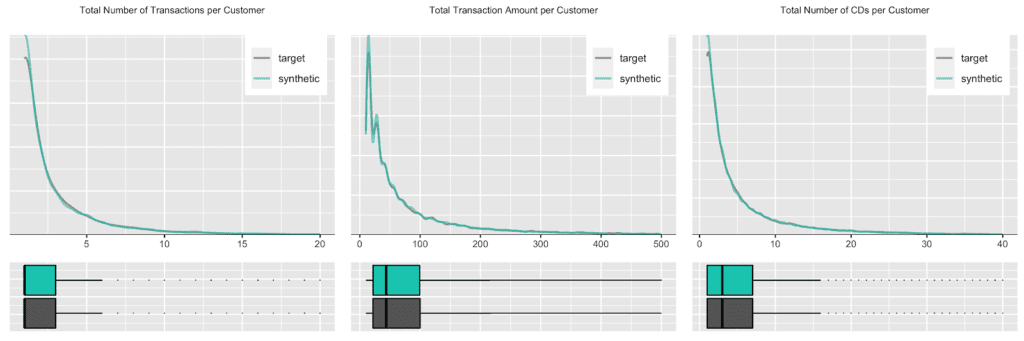
Due to this auto-correlation of succeeding transactions, it’s also common to observe a relatively small share of customers contribute to most of the total revenues of a company (and thus justifying different levels of acquisition and retention efforts). So, let’s validate this and move towards customer-level summary statistics, by aggregating over all the purchases for each customer. And indeed, in the presented dataset 20% of the most frequently buying customers of the actual cohort make up more than half (58%) of all transactions, and 20% of the most valuable customers contribute to 62% of all revenues. When querying the synthetic data, we can gain the same insights, with corresponding metrics being reported at 59% and 61% respectively. Yet, it’s not only single statistics but the full spectrum of these subject-level aggregates that is being accurately represented in the synthetic cohort, as can be seen in detail from the following plotted empirical distributions.
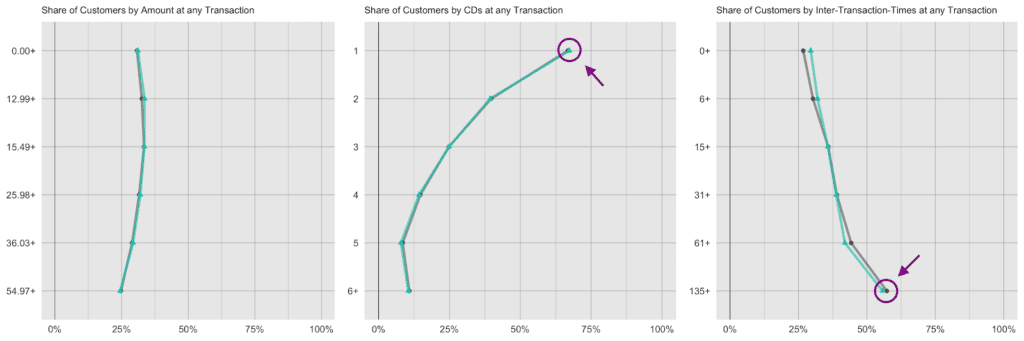
Next up, let’s investigate the share of customers that purchase a certain number of CDs, that had a given transaction amount spend, or that had a particular preceding inactivity period, at any one of their recorded transactions. E.g., while overall 45% of all transactions consisted of just a single CD, it is over two thirds (67%) of all customers that have had at least one single-CD purchase within their overall customer journey. Along the same line, it is 57% of customers that have exhibited a purchase hiatus longer than 135 days. Both statistics have been highlighted in the charts below, and show once again perfectly aligned results.
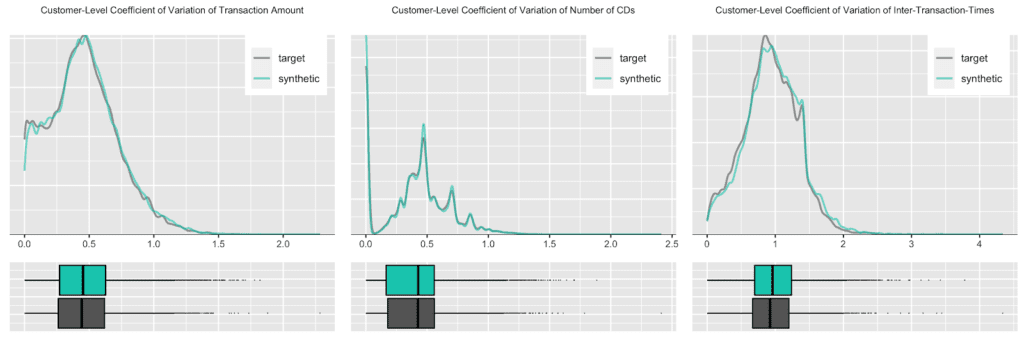
Further, let’s take yet another angle, and specifically, check for the consistency across all of the transactions of a customer. For that we will study the dispersion within attributes, and strengthen the test further by normalizing the standard deviation by its mean, resulting in the so-called coefficient of variation plotted below. In particular, the coefficient of variation for the intertransaction times being centered around 1 is an indication for exponentially distributed timing patterns. Once more, this same derived pattern can be seen for the actual as well as for the synthetic data.
In case your mind is boggling in the face of all these customer statistics, then don’t worry. The point that we are making here is that you can take any angle at the fully anonymous synthetic data in order to gain a deeper customer understanding, no matter whether it’s been anticipated or not before the actual synthesization process, and you will end up with highly aligned results.
BERKA
Our second case reflects a typical dataset structure within the finance industry. However, this publicly available set consists of only 4’500 accounts, while on the other hand each account has hundreds of data points. The challenge for a generic synthetic data solution thus is, to automatically extract generalizable relationships between all these data points based on a rather small sample.
We start out with an overall transaction-level analysis to gain a basic understanding of the original and synthetic datasets, before we compare again subject-level (in this case account-level) statistics in more detail. Transactions are spread out across a period ranging from 1993 to 1998, with a steadily growing upward trend, coupled with a strong seasonal pattern at the beginning of each year, as well as increased activity at the end of each month. In addition, there are strong dependencies between the categorical attributes as shown by the heatmap.
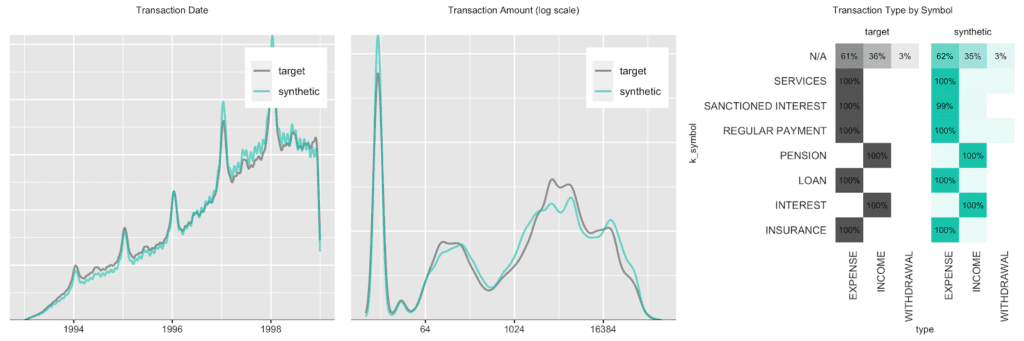
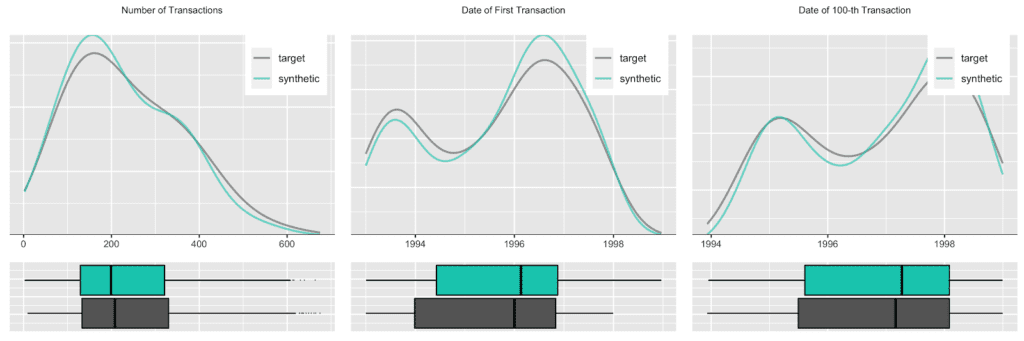
Accounts see a varying number of transactions, ranging from only a few up to 600 over the observed time period. Plotting the date of first transaction, i.e. the customer acquisition date, shows that the customer base has been steadily growing, with a particular strong year in 1996. Further, an analysis of the timing of the 100-th transaction remains consistent between the original and the synthetic data as well.
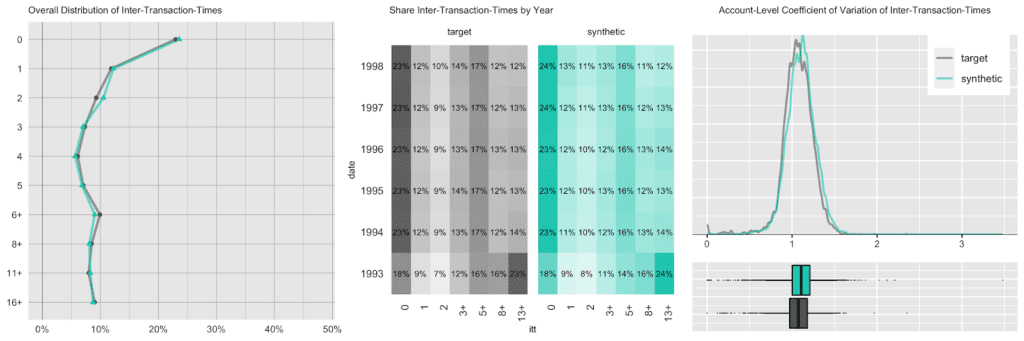
Next up we investigate the intertransacion times, which is a derived measure calculated as the elapsed number of days between two succeeding transactions. A value of 0 implies that a transaction has occurred on the same day as the previous transaction. The following charts take 3 different perspectives on this intertemporal metric. While, for example, overall a quarter of the transactions happened on the same date as a previous transaction, that pattern has been less pronounced in 1993, the initial year of the recording, as it had a significantly larger share of 13 days or longer periods of customer inactivity.
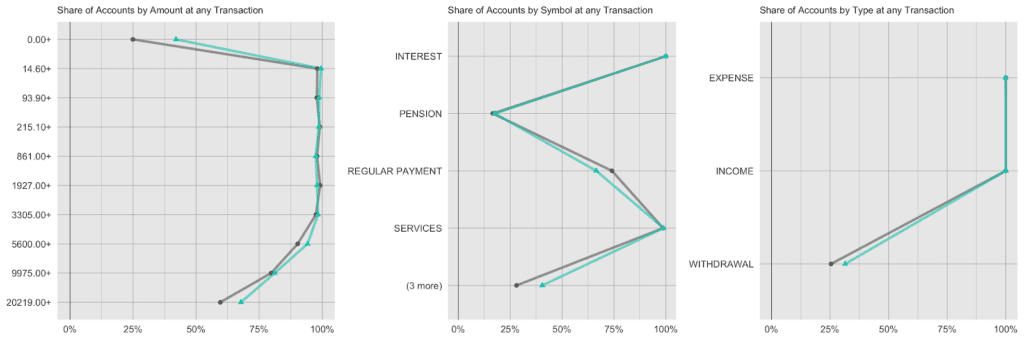
And lastly, we again look at the share of accounts that had a given amount/symbol/type at any of their transactions. E.g. while practically all accounts have had expenses and incomes recorded, the share of accounts with withdrawals is consistently low at around 25%, both for the real and the synthetic accounts.
GSTORE
It’s time to step up the game, and consider this online Merchandise store case with a significantly bigger population size, in this case, 1.6 million visitors, together with their visits. With this amount of data, the underlying generative deep neural network models of MOSTLY AI are able to fully leverage their capacity and retain information at a deeper level, as we will see next.
Visitors to the site are coming from over 200 different countries, with the US making up 40% of all visitors, India is second with a share of 7%, and UK, Canada, Germany follow the ranks. However, the exhibited behavior is distinctively different by country. US and Canadian visitors are the ones who are more likely to return multiple times to the site (20% likelihood vs. a 10% chance for the rest of the world) and are also the ones that actually end up making purchases at the store (as recorded by the attribute `transactionRevenue`). However, in that respect, a US visitor is still more than 3 times as likely to generate revenues than a Canadian visitor. Certainly a relevant insight for anyone looking to improve the store’s performance.
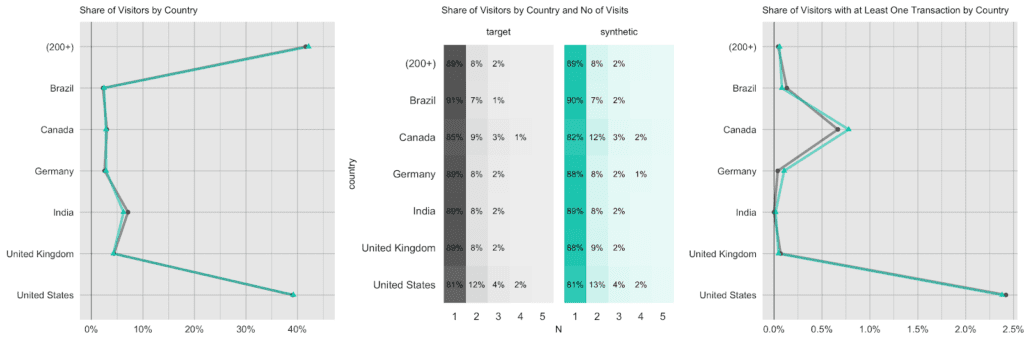
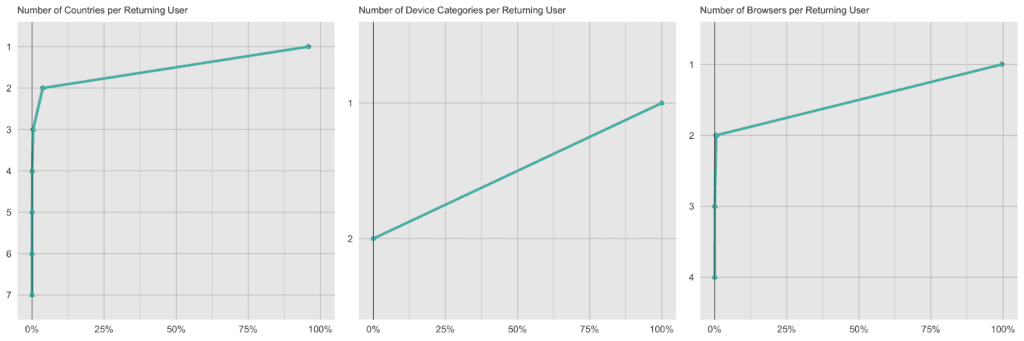
Each visitor is being identified in the dataset by a unique identifier. Typically, a visitor accesses the site with the same device, the same browser and within the same country, thus these attributes remain consistent across visits. However, there are exceptions to this rule, and we can detect these same exceptions again reliably in the synthetic data. 4.1% of returning visitors access the site from a different country, and 0.4% use a different browser in one of their later visits than they did in their first visit. For the synthetic data, these numbers are closely matched, with 4.4% and 0.6% each, i.e. it exhibits the same level of subject-level consistency over time as is present in original data.
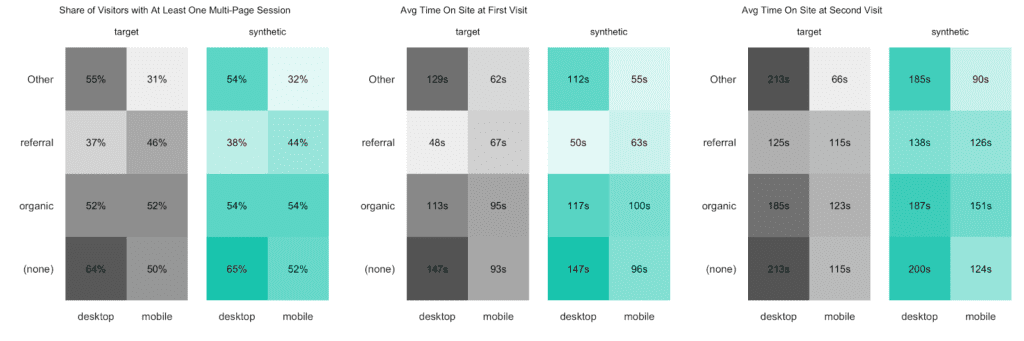
Finally, let’s dive even deeper into the data by cross-tabulating subject-level statistics by two categorical visit-level attributes. The following analysis indicates that the combination of the traffic source (of a visitor’s initial visit) and the device category is strongly, yet non-linearly related to the time spent on the site. While referrals result in shorter sessions for their first-time visit on the desktop than on the mobile, it is interestingly the other way around for organic traffic. For their second-time visit desktop users are then consistently spending more time on the site compared to mobile users. A non-trivial, yet persistent relationship worth investigating further.
INSTA
We will conclude our benchmark study with another large real-world dataset from the retail industry. This one consists of over 200k customers and their 32 million purchased product items.
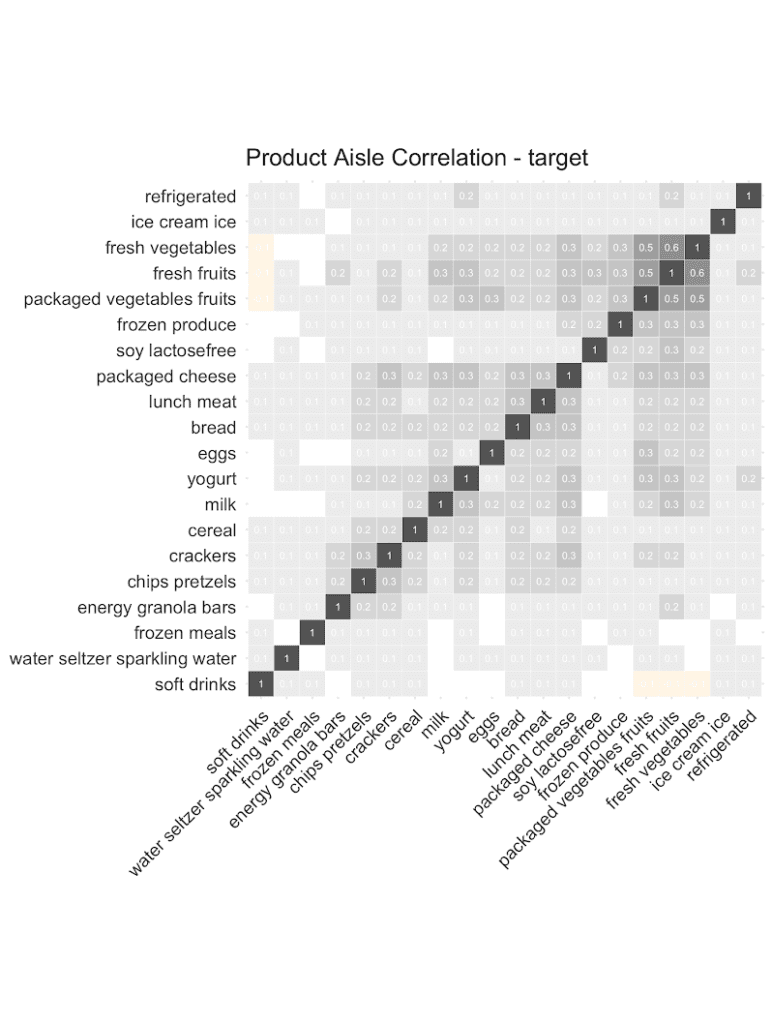
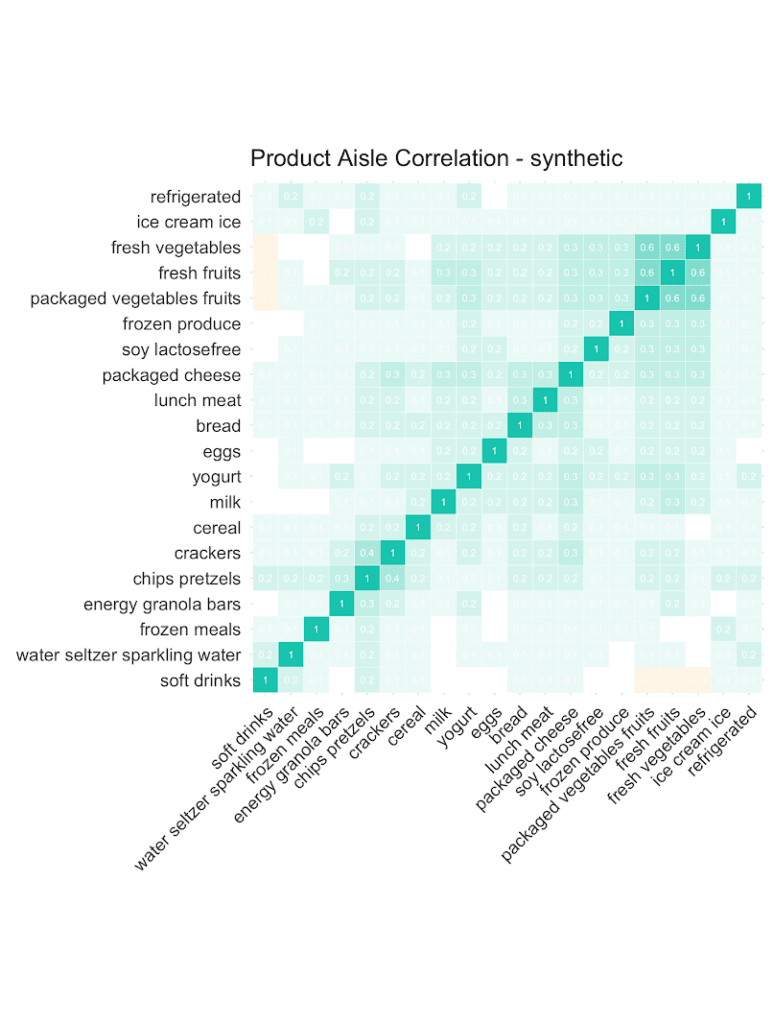
Let’s start out by checking the co-occurrences of popular product aisles: Purchases of chips are positively correlated with purchases of pretzels. And customers that buy fresh vegetables are more likely to add fresh fruits, and less likely to add soft drinks to their shopping list. And as can be seen from the following correlation plots, it’s the overall structure and relationships that are being very well retained in the synthetic data. This valuable information on basket compositions (in the context of a customer’s past purchase behavior) allows to build smart recommender systems that help users quickly add further items to their baskets, significantly improving their shopping experience. All possible in a fully privacy-preserving manner, with any internal teams or external partners developing these systems, thanks to our AI-based synthetic data solution.
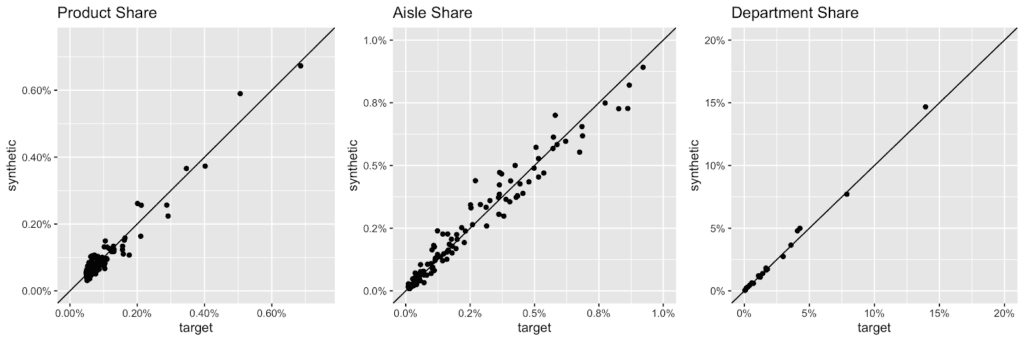
Overall, the grocery store has a very broad assortment with over 49’677 products across 134 aisles, and 21 departments being enlisted. Here are the actual and the synthetic shares of all products, of all aisles and of all departments plotted against each other.
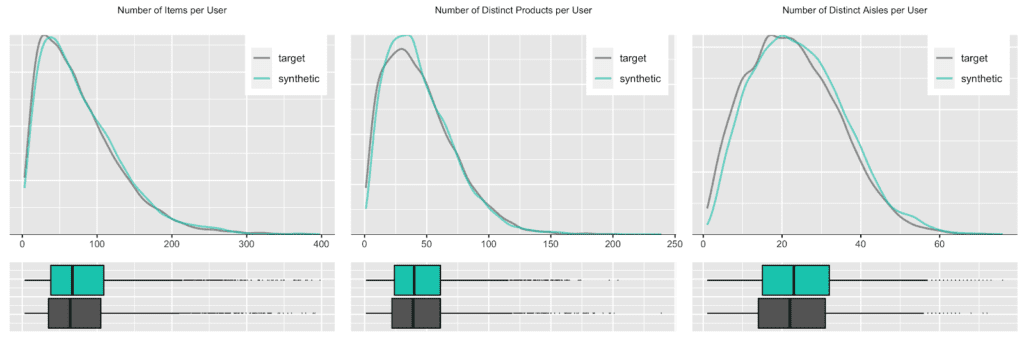
But any given customer will only ever purchase from a small subset of the assortment, in particular as customers tend to repurchase the same items over and over again. Let’s thus check the distribution, in terms of number of distinct products and distinct product aisles being ever purchased by customers. And of course, as we are not just interested in an “average” customer, we will inspect the full distribution of these metrics, as visualized below. Once more, we can see a near-perfect alignment between the real world and our synthetic world. This is a particularly remarkable achievement, as the synthetic data generator needs to be aware of the complete product spectrum as well as the full purchase history when generating new synthetic orders, that are to be statistically representative and coherent.
Conclusions
This third blog post in our series on synthetic behavioral data turned out lengthy and technical, and contained lots (and lots and lots) of statistics. Thanks for bearing with us. But we intentionally wanted to go the extra mile to demonstrate the sheer power and unparalleled accuracy of MOSTLY AI's AI-powered synthetic data platform across a broad range of datasets. So, no matter whether your customer data is big or small, wide or tall, static or dynamic, numeric or categorical, our solution will be able to reliably pick up the patterns and provide you with a synthetic, statistically representative version thereof. One that captures all the value, and yet is fully anonymous, and thus unrestricted to utilize and leverage further.
Behavioral data is the new gold, but it requires more than a few people to make the most out of it. And yet, the era of privacy is here, and here to stay. So, reach out to us and learn more about how you can go synthetic, and become the superhero of your organization who can finally make both data sharing and data protection possible at the same time.
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
Making The Case for Synthetic Behavioral Data
In the first part of this series, we’ve noted that only the most data-savvy organizations turn up on the winning side by knowing how to leverage their rapidly growing behavioral data assets. We further went on and identified two key obstacles for organizations to seize the arising opportunity:- Behavioral data is sequential, and thus complex to model and analyze.
- Behavioral data is privacy-sensitive and particularly difficult to anonymize. Thus it tends to be locked up.
Introducing the Dataset: CDNOW
In this blog post, we will work with the so-called CDNOW dataset, which represents purchase records of a former e-commerce site, that sold CDs online. The dataset contains the 18-month purchase history of a cohort of 23,570 customers, that the company acquired in the first quarter of 1997. As it’s one of the few publicly available, real-world transactional datasets, it has been extensively studied within the marketing literature and served as a canonical case study for developing behavioral models in non-contractual settings ([1], [2], [3], [4]). If you are interested, you can easily obtain the dataset as well via Bruce Hardie’s website.
Poor Consumer Understanding Will Lead to Poor Business Decisions
These basic statistics already show that looking at the “Average Customer” does not reveal the looming problems of the e-commerce site, and don't reflect the full breadth of observable behavior in any customer base. Organizations that are truly interested in understanding their customers and their behaviors, and that wish to effectively address these, would rather ask questions like the following:- Which customers will come back?
- When will they come back?
- How often will they return?
- How much will they likely spend?
- Thus, what is their customer lifetime value going to be? (don't miss out on Pete Fader’s TEDx talk on customer-centricity)
- Does the very first purchase provide any indication of later actions?
- Are the most frequent customers the most valuable ones?
- At which particular dates are customers more active?
- Are weekend shoppers different from weekday shoppers?
- At which price points do specific customer groups like to act?
- How much time typically elapses between two purchases?
- Do customers come regularly or rather sporadically?
- And can we build predictive models based on these insights?
Generating a Synthetic Version of CDNOW

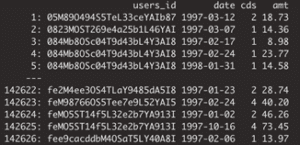
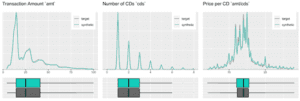

Synthetic Sequences Allow You to Draw the Same Conclusions As Real Ones

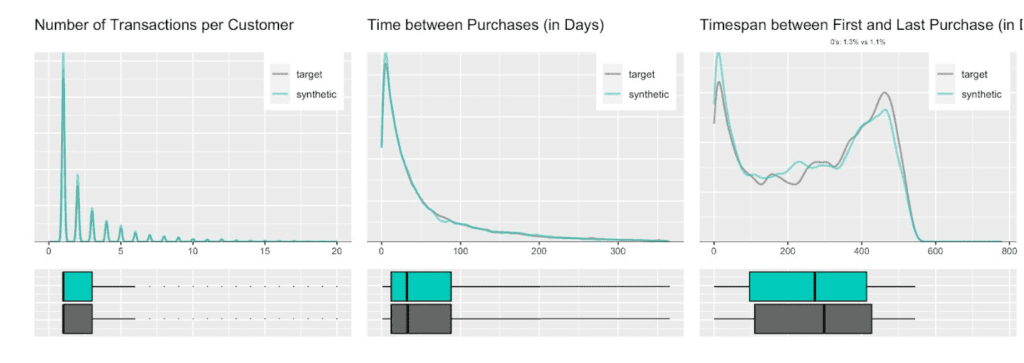
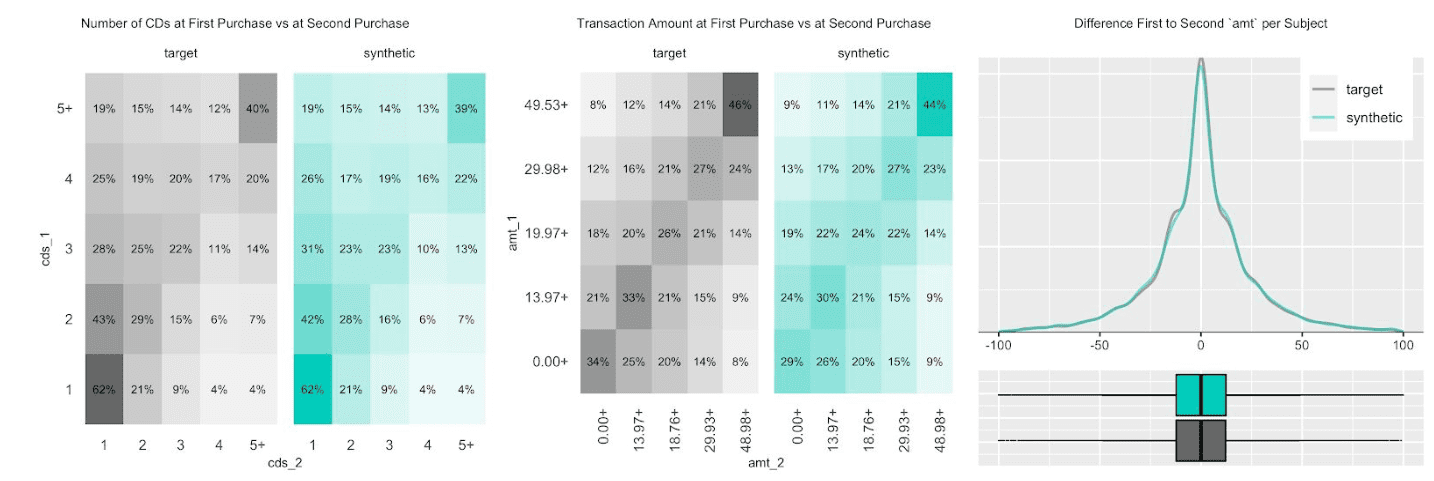
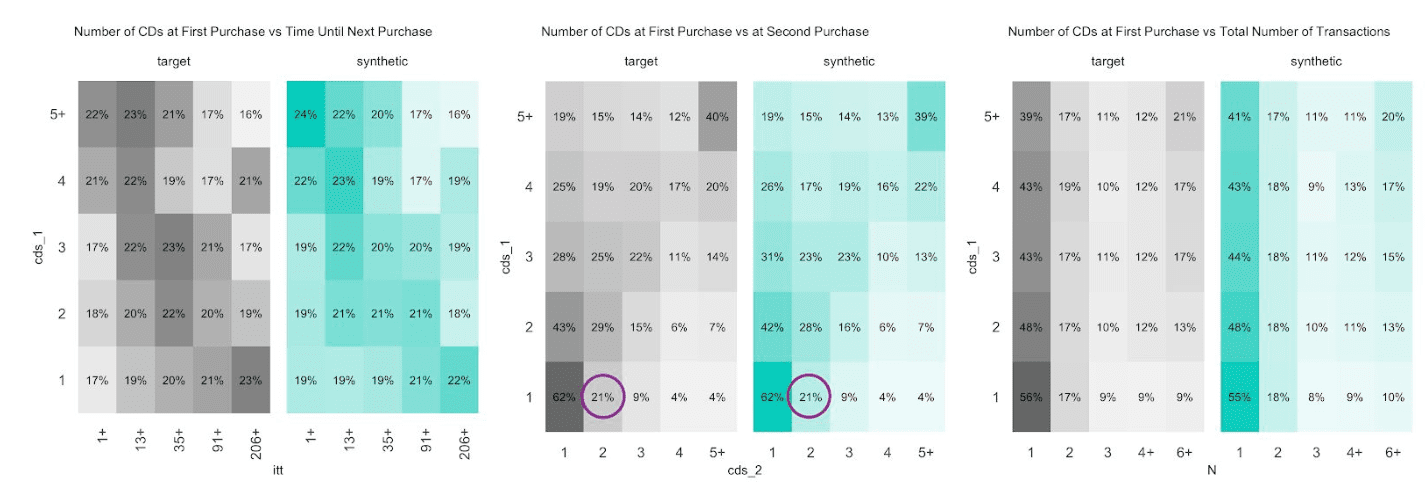
Fig 6. Various Distributions at Customer Level
Synthetic Predictions to Guide Business Decisions While Preserving Privacy
Let’s take this further, and do some predictive modeling on the individual customer level. We can, for example, easily fit the popular BG/NBD model (via the Buy-Till-You-Die R package) to a calibration period of 39 weeks of actual as well as of synthetic data, to see whether this yields comparable results. Note, that our generative model shares none of the intrinsic model assumptions of the BG/NBD model, but purely detects the patterns based on the empirical data. This being considered, it is even more impressive, that the four estimated BG/NBD parameters can be near perfectly recovered from the synthetic data, without ever seeing the actual data. The estimated purchase frequency, the estimated churn process, and their corresponding heterogeneity match closely. Thus, the models trained on synthetic data yield near-identical (and still very accurate) forecasts for the 39 week holdout period of actual consumer data (see figure 7 for further details).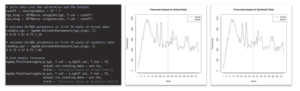

Prologue
In one of our earlier blog posts we demonstrated our synthetic data platform using a well studied, publicly available dataset of over 50’000 historic diamond sales with 10 recorded data points each. It served as an educational example to introduce the idea of synthetic data, as well as to showcase the unparalleled accuracy of our technology. With the click of a button, users of our platform can forge an unlimited number of precious, highly realistic, highly representative synthetic data diamonds.
But, to be fair, the example didn’t do justice to the type and scale of real-world behavioral data assets encountered in today’s industry, whether it’s financial, telecommunication, healthcare or other digital services. Organizations operate at a different order of magnitude, as they serve millions of customers and record thousands of data points over time for each one of those. Whether these recorded sequences of events represent transactions, visits, clicks or other actions, it is so important that these rich behavioral stories of customers are understood, analyzed, and leveraged at scale in order to provide smarter services with the best possible user experience for each customer.
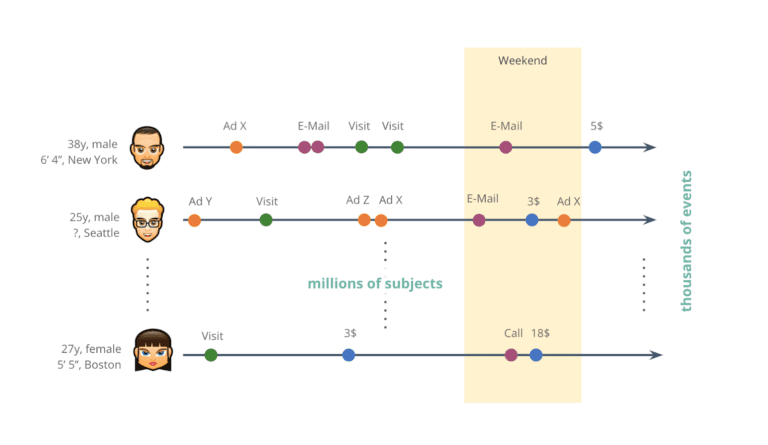
Today, organizations collect thousands of events for each and every one of their millions of customers.
But despite the immense growth in volume over recent years, the captured behavioral data still remains vastly an untapped opportunity. And over and over again, we can identify two key obstacles at organizations at play:
1) Behavioral data is primarily sequential and constantly evolving, rather than static and fixed – and with its thousands of data points per individual, there is a sheer unlimited number of potential temporal inter-dependencies and contextual correlations to look for. To say it simply: It’s a fundamentally different category beast than what is being taught at Statistics 101. Existing business intelligence tools, as well as regression or tree-based models struggle in making sense of this type of data at scale. Thus it is no surprise that only the most data-savvy organizations turn up on the winning side by knowing how to leverage their immense behavioral data assets to effectively gain a competitive edge with hyper-personalized customer experiences.
2) The second obstacle is, that behavioral data remains primarily locked up. Because with thousands of available data points per customer the re-identification of individual subjects becomes increasingly easy. Existing anonymization techniques (e.g. data masking), that have been developed to work for a handful of sensitive attributes per subject, stand no chance in protecting privacy while retaining the utility of this type of data at a granular level. A disillusion that is by now also broadly understood and recognized by the public:

As it turns out, these are two reinforcing effects: Without safe data sharing, you can’t establish data literacy around behavioral data. Without data literacy, you will not see the growing demand for behavioral data in your organization. However, only some companies will remain stuck in their inertia, while others are able to identify and thus address the dilemma by turning towards synthetic data, which allows them to offer smart, adaptive, and data-driven services to win the hearts of the consumers (as well as the markets).
The Curse of Dimensionality
Let’s look at an example to illustrate the complexity of sequential behavioral data. Within retail banking, each account will have a sequence of transactions recorded. But even if we discard any personally identifiable information on the customer, and even if we limit the amount of information per transaction to 5 distinct transaction amounts, and 20 distinct transaction categories, the number of behavioral stories quickly explodes with the length of the sequences. While a single transaction seems innocuous with its 20*50 = 100 possible outcomes, two transactions will already yield 100*100 = 10’000 outcomes. For a sequence of three transactions we are at 100^3 = 1 million outcomes per customer, and at forty recorded transactions, we will already have more possible outcomes (10^80) than atoms in the universe! No wonder, that these digital traces are highly identifying, and near impossible to obfuscate. No wonder, that making sense of this vast sea of data and detecting patterns and nuances therein poses such a huge challenge.
This combinatorial explosion, the exponential growth of outcomes with the number of records per subject, is also referred to as the curse of dimensionality. There is no person like another, everyone is different, everyone is unique. It’s a curse for analytics, it’s a curse for protecting privacy. But, at the same time, it’s a blessing for customer-centric organizations, who are willed to embrace a rich, diverse world of individuals, and who recognize this to be an opportunity to differentiate on top of these otherwise hidden behavioral patterns.

AI-Generated Synthetic Data to the Rescue
The power of synthetic data continues to be recognized as THE way forward for privacy-preserving data sharing. While there are various approaches and levels of sophistication, ranging from simple rule-based to more advanced model-based generators, our focus at MOSTLY AI has always been on offering the world’s most accurate solution based on deep neural network architectures. These are high-capacity, state-of-the-art machine learning models, that can reliably and automatically pick up and retain complex hidden patterns at scale. In particular for the type of sequential data, that is so prevalent among an organization’s behavioral data assets. These models make little a-prior assumptions and require no manual feature engineering by domain experts. They are the very same models that have revolutionized so many fields already over the past couple of years, like image classification, speech recognition, text translation, robotics, etc., that are now about to change privacy-preserving big data sharing once and for all.
And ultimately, it is the accuracy and representativeness of the synthetic data that is the key driver of its value. This is what will determine whether use cases go beyond mere testing & development, and expand towards advanced analytics and machine learning tasks as well, where synthetic data can be relied on in lieu of the actual privacy-sensitive customer data. And just as classic learning algorithms continue to be superseded by deep learning in the presence of big data, one can already observe a similar evolution for the market of synthetic data solutions for behavioral data assets.
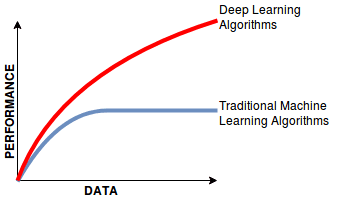
This was the first part of our mini-series on sequential data, setting the stage for next week’s post. There we will present a handful of empirical case studies to showcase the power of our synthetic data platform, in particular with respect to the important domain of behavioral data – so make sure that you don’t miss out on it!
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.