What is time series data?
Time series data is a sequence of data points that are collected or recorded at intervals over a period of time. What makes a time series dataset unique is the sequence or order in which these data points occur. This ordering is vital to understanding any trends, patterns, or seasonal variations that may be present in the data.
In a time series, data points are often correlated and dependent on previous values in the series. For example, when a financial stock price moves every fraction of a second, its movements are based on previous positions and trends. Time series data becomes a valuable asset in predicting future values based on these past patterns, a process known as forecasting.
Time series forecasting employs specialized statistical techniques to effectively model and generate future predictions. It is commonly used in business, finance, environmental science, and many other areas for decision-making and strategic planning.
Types of time series data
Time series data can be categorized in various ways, each with its own characteristics and analytical approaches.
Metric-based time series data
When measurements are taken at regular intervals, these are known as time series metrics. Metrics are crucial for observing trends, detecting anomalies, and forecasting future values based on historical patterns.
This type of time series data is commonly seen in financial datasets, where stock prices are recorded at consistent intervals, or in environmental monitoring, where temperature, pressure, or humidity data is collected periodically.
Source: Unsplash
Event-based time series
Event-based time series data captures occurrences that happen at specific points in time, but not necessarily at regular intervals. While this data can still be aggregated into snapshots over traditional periods, the event-based time series data forms a more complex series of related activities.
Source: Unsplash
Examples include system logging in IT networks, where each entry records an event like a system error or a transaction. Electronic health records capture patient interactions with doctors, with medical devices capturing complex health telemetry over time. City-wide sensor networks capture the telemetry from millions of individual transport journeys, including bus, subway, and taxi routes.
Event-based data is vital to understanding the sequences and relationships between occurrences that help drive decision-making in cybersecurity, customer behavioral analysis, and many other domains.
Linear time series data
Time series data can also be categorized based on how the patterns within the time series behave over time. Linear time series data is more straightforward to model and forecast, with consistent behavior from one time period to the next.
Stock prices are a classic example of a linear time series. The value of a company’s shares is recorded at regular intervals, reflecting the latest market valuation. Analyzing this data over extended periods helps investors make informed decisions about buying and selling stocks based on historical performance and predicted trends.
Non-linear time series data
In contrast, non-linear time series data is often more complex, with changes that do not follow a predictable pattern. Such time series are often found in more dynamic systems when external factors force changes in behavior that may be short-lived.
For example, short-term demand modeling for public transport after an event or incident will likely follow a complex pattern that combines the time of day, geolocation information, and other factors, making reliable predictions more complicated. With IoT wearables for health, athletes are constantly monitored for early warning signals of injury or fatigue. These data points do not follow a traditional linear time series model; instead, they require a broader range of inputs to assess and predict areas of concern.
Behavioral time series data
Capturing time series data around user interactions or consumer patterns produces behavioral datasets that can provide insights into habits, preferences, or individual decisions. Behavioral time series data is becoming increasingly important to social scientists, designers, and marketers to better understand and predict human behavior in various contexts.
From measuring whether daily yoga practice can impact device screen time habits to analyzing over 285 million user events from an eCommerce website, behavioral time series data can exist as either metrics- or event-based time series datasets.
Metrics-based behavioral analytics are widespread in financial services, where customer activity over an extended period is used to assess suitability for loans or other services. Event-based behavioral analytics are often deployed as prescriptive analytics against sequences of events that represent transactions, visits, clicks, or other actions.
Organizations use behavioral analytics at scale to provide customers visiting websites, applications, or even brick-and-mortar stores with a “next best action” that will add value to their experience.
Despite the immense growth of behavioral data captured through digital transformation and investment programs, there are still major challenges to driving value from this largely untapped data asset class.
Since behavioral data typically stores thousands of data points per customer, individuals are increasingly likely to be re-identified, resulting in privacy breaches. Legacy data anonymization techniques, such as data masking, fail to provide strong enough privacy controls or remove so much from the data that it loses its utility for analytics altogether.
Examples of time series data
Let’s explore some common examples of time series data from public sources.
From the US Federal Reserve, a data platform known as the Federal Reserve Economic Database (FRED) collects time series data related to populations, employment, socioeconomic indicators, and many more categories.
Some of FRED’s most popular time series datasets include:
| Category | Source | Frequency | Data Since |
|---|---|---|---|
| Population | US Bureau of Economic Analysis | Monthly | 1959 |
| Employment (Nonfarm Private Payroll) | Automatic Data Processing, Inc. | Weekly | 2010 |
| National Accounts (Federal Debt) | US Department of the Treasury | Quarterly | 1966 |
| Environmental (Jet Fuel CO2 Emissions) | US Energy Information Administration | Annually | 1973 |
Beyond socioeconomic and political indicators, time series data plays a critical role in the decision-making processes behind financial services, especially banking activities such as trading, asset management, and risk analysis.
| Category | Source | Frequency | Data Since |
|---|---|---|---|
| Interest Rates (e.g., 3-Month Treasury Bill Secondary Market Rates) | Federal Reserve | Daily | 2018 |
| Exchange Rates (e.g., USD to EUR Spot Exchange Rate) | Federal Reserve | Daily | 2018 |
| Consumer Behavior (e.g., Large Bank Consumer Credit Card Balances) | Federal Reserve Bank of Philadelphia | Quarterly | 2012 |
| Markets Data (e.g., commodities, futures, equities, etc.) | Bloomberg, Reuters, Refinitiv, and many others | Real-Time | N/A |
The website kaggle.com provides an extensive repository of publicly available datasets, many recorded as time series.
| Category | Source | Frequency | Data Range |
|---|---|---|---|
| Environmental (Jena Climate Dataset) | Max Planck Institute for Biogeochemistry | Every 10 minutes | 2009-2016 |
| Transportation (NYC Yellow Taxi Trip Data) | NYC Taxi & Limousine Commission (TLC) | Monthly updates, with individual trip records | 2009- |
| Public Health (COVID-19) | World Health Organization | Daily | 2020- |
An emerging category of time series data relates to the growing use of Internet of things (IoT) devices that capture and transmit information for storage and processing. IoT devices, such as smart energy meters, have become extremely popular in both industrial applications (e.g., manufacturing sensors) and commercial use.
| Category | Source | Frequency | Data Range |
|---|---|---|---|
| IoT Consumer Energy (Smart Meter Telemetry) | Jaganadh Gopinadhan (Kaggle) | Minute | 12-month period |
| IoT Temperature Measurements | Atul Anand (Kaggle) | Second | 12-month period |
How to store time series data
Once time series data has been captured, there are several popular options for storing, processing, and querying these datasets using standard components in a modern data stack or via more specialist technologies.
File formats for time series data
Storing time series data in file formats like CSV, JSON, and XML is common due to their simplicity and broad compatibility. With CSV files especially, this makes them ideal for smaller datasets, where ease of use and portability are critical.
Formats such as Parquet have become increasingly popular for storing large-scale time series datasets, offering efficient compression and high performance for analysis. However, Parquet can be more complex and resource-intensive than simpler file formats, and managing large numbers of Parquet files, especially in a rapidly changing time series context, can become challenging.
When more complex data structures are involved, JSON and XML formats provide a structured way to store time series data, complete with associated metadata, especially when using APIs to transfer information between systems. JSON and XML typically require additional processing to “flatten” the data for analysis and are not ideal for large datasets.
For most time series stored in files, it’s recommended to use the more straightforward CSV format where possible, switching to Parquet when data volumes affect storage efficiency and read/write speeds, typically at the gigabyte or terabyte scale. Likewise, a synthetically generated time series can be easily exported to tabular CSV or Parquet format for downstream analysis in various tools.
Time series databases
Dedicated time series databases, such as Kx Systems, are specifically designed to manage and analyze sequences of data points indexed over time. These databases are optimized for handling large volumes of data that are constantly changing or being updated, making them ideal for applications in financial markets such as high-frequency trading, IoT sensor data, or real-time monitoring.
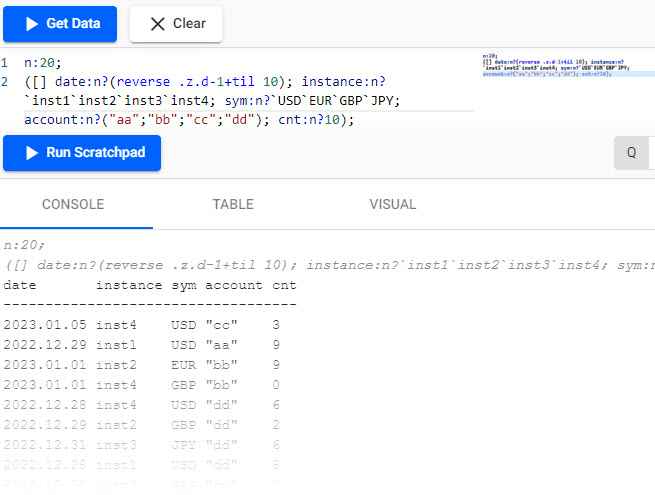
Source: Kx query
Graph databases for time series
Graph databases like Neo4j offer a unique approach to storing time series data by representing it as a network of interconnected nodes and relationships. Graph databases allow for the modeling of complex relationships, providing insights that might be difficult to extract from traditional relational data models.
The ability to explore relationships efficiently in graph databases makes them suitable for analyses that require a deep understanding of interactions over time, adding a rich layer of context to the time series data.
In the example below, Neo4j can create a “TimeTree” graph data model that captures events used in risk and compliance analysis. Exploring emails sent at different times to different parties and any associated events from that period becomes possible.
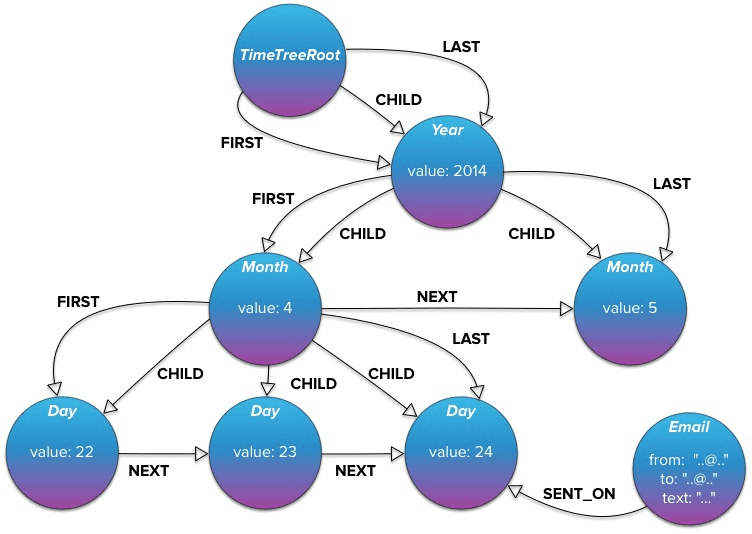
Source: Neo4j time-tree
Relational databases for time series
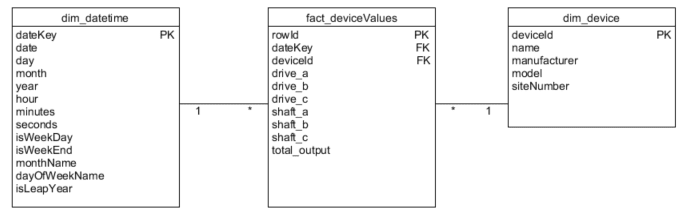
For decades, traditional relational database management systems (RDBMS) like Snowflake, Postgres, or Redshift have been used to store, process, and analyze time series data. One of the most popular relational data models for time series analysis is known as the star schema, where a central fact table (containing the time series data such as events, transactions, or behaviors) is connected to several dimension tables (e.g., customer, store, product, etc.) that provide rich analytical context.
By capturing events at a granular level, the time series data can be sliced and diced in many different ways, giving analysts a great deal of flexibility to answer questions and explore business performance. Usually, a date dimension table contains all the relevant context for a time series analysis, with attributes such as day of the week, month, and quarter, as well as valuable references to prior periods for comparison.
In a well-designed star schema model, the number of dimensions associated with a transactional fact table generally ranges between six and 15. These dimensions, which provide the contextual details necessary to understand and analyze the facts, depend on the specific analysis needs and the complexity of the business domain. MOSTLY AI can generate highly realistic synthetic data that fully retains the correlations from the original dimensions and fact tables across star schema data models with three or more entities.
Source: Stack Exchange
How to analyze time series data
Before analyzing a time series model, there are several essential terms and concepts to review.
Trend
A trend is a long-term value increase or decrease within a time series. Trends do not have to be linear and may reverse direction over time.
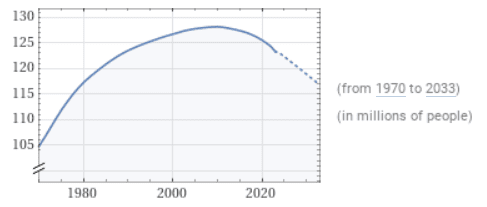
Source: WolframAlpha
Seasonality
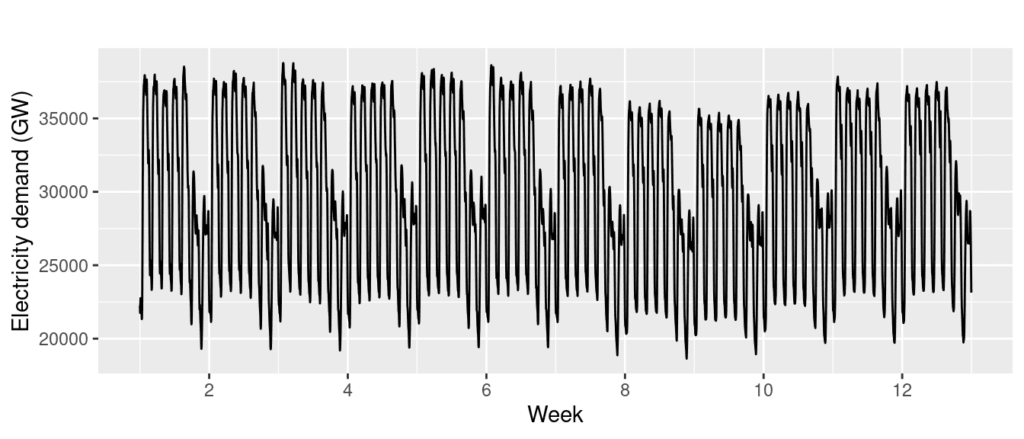
Seasonality is a pattern that occurs in a time series dataset at a fixed interval, such as the time of year or day of the week. Most commonly associated with physical properties such as temperature or rainfall, seasonality is also applied to consumer behavior driven by public holidays or promotional events.
Data retention over extended periods allows analysts to observe long-term patterns and variations. This historical perspective is essential for distinguishing between one-time anomalies and consistent seasonal fluctuations, providing valuable insights for forecasting and strategic planning.

Adapted from: Climates to Travel
Cyclicity
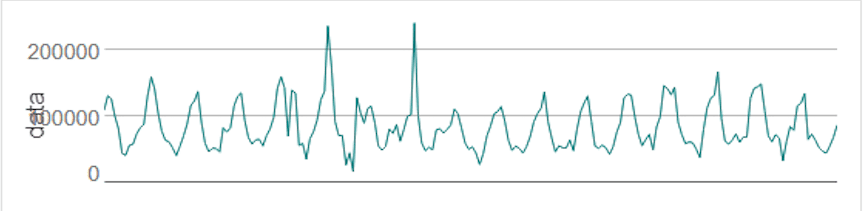
A cyclic pattern occurs when observations rise and fall at non-fixed frequencies. Often, cycles last for multiple years, but the cyclic duration can only sometimes be determined in advance.
Source: Rob J. Hyndman
Random noise
The final component to a time series is random noise, once any trends, seasonality, or cyclic signals have been accounted for. Any time series that contains too much random noise will be challenging to forecast or analyze.
Preparing data for time series analysis: Fill the gaps
Once a time series dataset has been collected, ensuring no missing dates within the sequence is vital. Review the granularity of the data set and impute any missing elements to ensure a smooth sequence. The imputation approach will vary depending on the dataset. Still, a common approach is filling any missing time series gaps with an average value based on the nearest data points.
Exploring the signals within a time series with decomposition plots
The next step in time series analysis is to explore different univariate plots of the data to determine how to develop a forecasting model.
A time series plot can help assess whether the original time series data needs to be transformed or whether any outliers are present.
Source: Alteryx
A seasonal plot helps analysts explore whether seasonality exists within the dataset, its frequency, and cyclic behaviors.
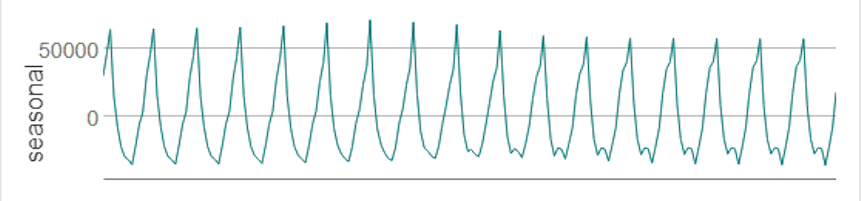
Source: Alteryx
A trend analysis can explore the magnitude of the change that is identified during the time series and is used in conjunction with the seasonality chart to explore areas of interest in the data.
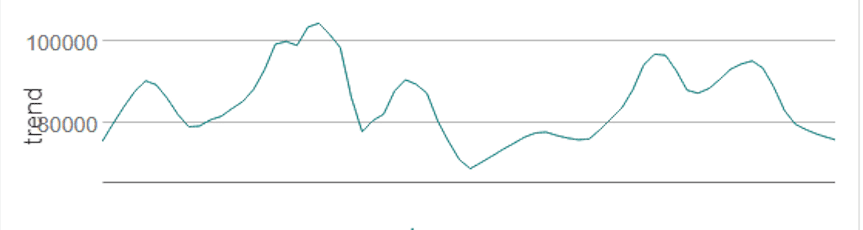
Source: Alteryx
Finally, a residual analysis shows any information remaining once seasonality and trend have been taken into account.
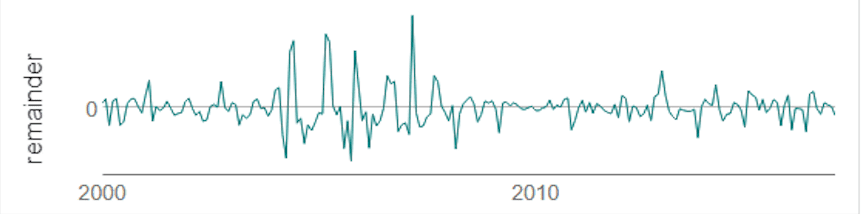
Source: Alteryx
Time series decomposition plots of this type are available in most data science environments, including R and Python.
Exploring relationships between points in a time series: Autocorrelation
As explored previously, time series records have strong relationships with previous points in the data. The strength of these relationships can be measured through a statistical tool called autocorrelation.
An autocorrelation function (ACF) measures how much current data points in a time series are correlated to previous ones over different periods. It’s a method to understand how past values in the series influence current values.
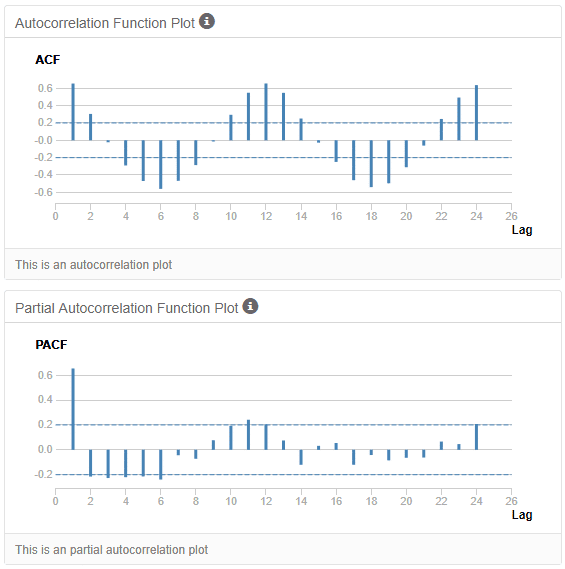
Source: Alteryx
When generating synthetic data, it’s important to preserve these underlying patterns and correlations. Accurate synthetic datasets can mimic these patterns, successfully retaining both the statistical properties as well as the time-lagged behavior of the original time series.
Building predictive time series forecasts: ARIMA
Once the exploration of a time series is complete, analysts can use their findings to build predictive models against the dataset to forecast future values.
ARIMA, AutoRegressive Integrated Moving Average, is a popular statistical method effective for time series data showing patterns or trends over time. It combines three key components:
- Autoregression (AR): Using the relationship between a current observation and several lagged observations.
- Integration (I): A process to remove trends and seasonality from the data, effectively rendering it “stationary.”
- Moving Average (MA): Calculates the relationship between a current observation and the errors from previous predictions, helping to smooth out random noise in the data.
Building predictive time series forecasts: ETS
An alternative approach is to use a method known as Error, Trend, Seasonality (ETS) that focuses on decomposing a time series into its error, trend, and seasonal components to predict future values:
- Error: As seen in the decomposition plot above, the error component captures randomness or noise in the data.
- Trend: Captures the long-term progression in the time series.
- Seasonality: Captures any systematic or calendar-related patterns.
Reviewing forecasts: Visualization and statistics
Once a model (or models) have been created, they can be visualized alongside historical data to inspect how closely the forecast follows the pattern of the existing time series data.
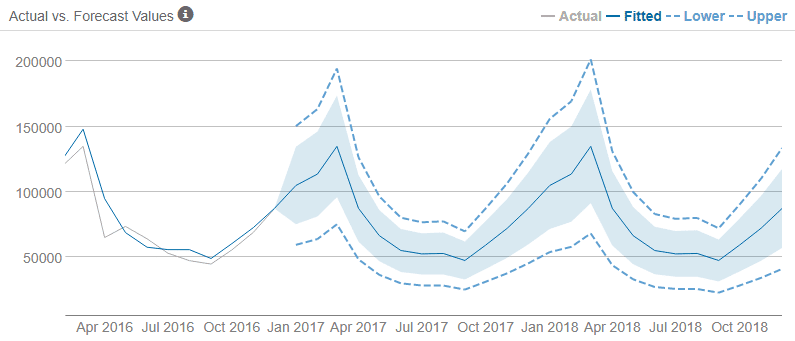
Source: phData
A quantitative approach to measuring time series forecasts often employs either the AIC (Akaike Information Criterion) or AICc (Corrected Akaike Information Criterion), defined as follows:
- AIC: Balances a model’s fit to the data against the complexity of the model, with a lower AIC score indicating a better model. AIC is often used when the sample size is significantly larger than the number of model parameters.
- AICc: This approach prevents overfitting in time series forecasting models with a smaller sample size by adding a correction term to the AIC calculation.
How to anonymize a time series with synthetic data
Anonymizing time series data is notoriously difficult and legacy anonymization approaches fail at this challenge.
But there is an effective alternative: synthetic data which offers a solution to these privacy concerns.
Synthesizing time series data makes a lot of sense when dealing with behavioral data. Understanding the key concepts of data subjects is a crucial step in learning how to generate synthetic data in a privacy-preserving manner.
A subject is an entity or individual whose privacy you will protect. Behavioral event data must be prepared in advance so that each subject in the dataset (e.g., a customer, website visitor, hospital patient, etc.) is stored in a dedicated table, each with a unique row identifier. These subjects can have additional reference information stored in separate columns, including attributes that ideally don’t change during the captured events.
For data practitioners, the concept of the subject table is similar to a “dimension” table in a data warehouse, where common attributes related to the subjects are provided for context and further analysis.
The behavioral event data is prepared and stored in a separate linked table referencing a unique subject. In this way, one subject will have zero, one, or (likely) many events captured in this linked table.
Records in the linked table must be pre-sorted in chronological order for each subject to capture the time-sensitive nature of the original data. This model suits various types of event-based data, including insurance claims, patient health, eCommerce, and financial transactions.
In the example of a customer journey, our tables may look like this.
We see customers stored in our subject table with their associated demographic attributes.
| ID | ZONE | STATE | GENDER | AGE_CAT | AGE |
|---|---|---|---|---|---|
| 1 | Pacific | Oregon | M | Young | 26 |
| 2 | Eastern | New Jersey | M | Medium | 36 |
| 3 | Central | Minnesota | M | Young | 17 |
| 4 | Eastern | Michigan | M | Medium | 56 |
| 5 | Eastern | New Jersey | M | Medium | 46 |
| 6 | Mountain | New Mexico | M | Medium | 35 |
In the corresponding linked table, we have captured events relating to the purchasing behavior of each of our subjects.
| USER_ID | DATE | NUM_CDS | AMT |
|---|---|---|---|
| 1 | 1997-01-01 | 1 | 11.77 |
| 2 | 1997-01-12 | 1 | 12 |
| 2 | 1997-01-12 | 5 | 77 |
In this example, user 1 visited the website on January 1st, 1997, purchasing 1 CD for $11.77. User 2 visited the website twice on January 12th, 1997, making six purchases over these visits for $89.
These consumer buying behaviors can be aggregated into standard metrics-based time series, such as purchases per week, month, or quarter, revealing general buying trends over time. Alternatively, the behavioral data in the linked table can be treated as discrete purchasing events happening at specific intervals in time.
Customer-centric organizations obsess around behaviors that drive revenue and retention beyond simple statistics. Analysts constantly ask questions about customer return rates, spending habits, and overall customer lifetime value.
Synthetic data modeling: Relationships between subjects and linked data
Defining the relationship between customers and their purchases is an essential first step in synthetic data modeling. Ensuring that primary and foreign keys are identified between subject and linked tables enables synthetic data generation platforms to understand the context of each behavioral record (e.g., purchases) in terms of the subject (e.g., customers).
Additional configurations, such as smart imputation, dataset rebalancing, or rare category protection, can be defined at this stage.
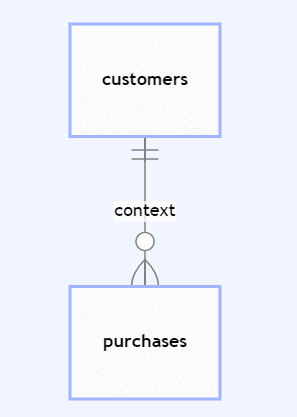
Synthetic data modeling: Sequence lengths and continuation
A time series sequence refers to a captured set of data over time for a subject within the dataset. For synthetic data models, generating the next element in a sequence given a previous set of features is a critical capability known as sequence continuation.
Defining sequence lengths in synthetic data models involves specifying the number of time steps or data points to be considered in each sequence within the dataset. This decision determines how much historical data the synthetic model will use to predict or generate the next element in the sequence.
The choice of sequence length depends significantly on the nature of the data and the specific application. Longer sequence lengths can capture more long-term patterns and dependencies but will also require more computational resources and may need to be more responsive to recent changes. Conversely, a shorter sequence length is more sensitive to recent trends but might overlook longer-term patterns.
In synthetic modeling, selecting a sequence length that strikes a balance between capturing sufficient historical or behavioral context and maintaining computational efficiency and performance is essential.
Synthetic data generation: Accurate and privacy-safe results
Synthetic data generation can produce realistic and representative behavioral time series data that mimics the original distribution found in the source data without the possibility of re-identification. With privacy-safe behavioral data, it’s possible to democratize access to datasets such as these, developing more sophisticated behavioral models and deeper insights beyond basic metrics, “average” customers, and crude segmentation methods.
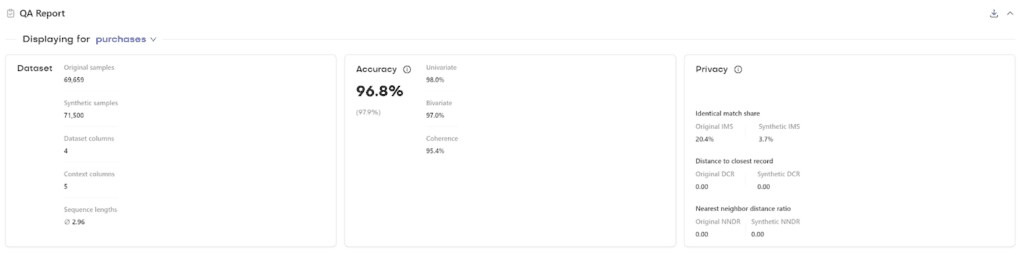

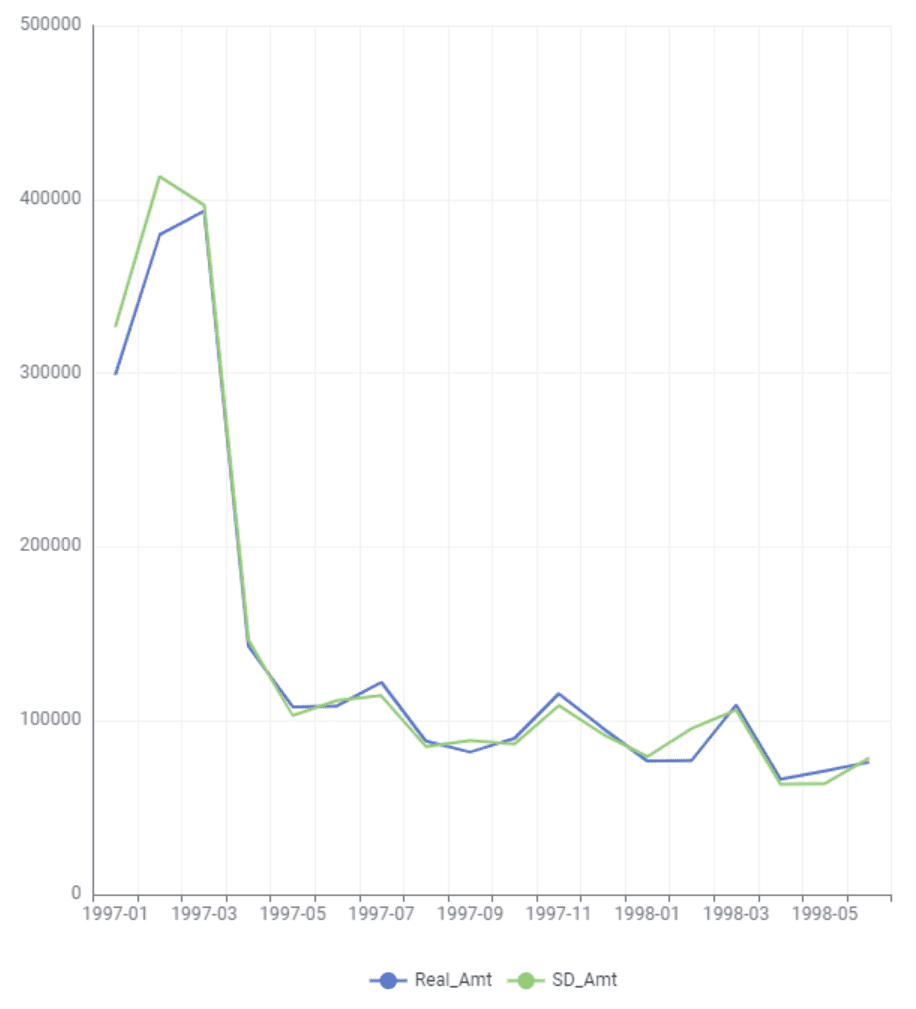
Table of Contents
The definition of data monetization
Data monetization refers to converting data assets into revenue or value for an organization. The strategic practice of data monetization involves the collection, analysis, and sale of data to generate profits, improve decision-making, or enhance customer experiences. We can distinguish between internal and external data monetization, depending on where data consumption takes place. Businesses can acquire a competitive advantage in the digital world by exploiting insights and information from data. Data monetization is critical in today's economy, allowing businesses to maximize the value of their data resources while adhering to privacy and security policies and regulations.
Motivation for data monetization: Data as an asset
The idea that data is an asset is becoming more and more prevalent, changing how businesses function and develop. Data is now more than simply a byproduct of operations; it's a product itself, a useful tool that can be used to improve decision-making, generate new income streams, and gain a competitive edge. This paradigm shift raises a fundamental question: why not include data as an asset on a company's balance sheet, just like other tangible and intangible assets?
The recognition of data as an asset is not a theoretical proposition but a practical reality. Companies have come to understand that the enormous amounts of data they generate, gather, and retain may contain a wealth of information about consumer preferences, market trends, and insights. By evaluating this data, organizations can improve operations, create more successful marketing campaigns, and make better decisions. The outcome? Increased effectiveness, financial savings, and — above all — the generation of fresh revenue streams.
Take online retail giants like Amazon and Netflix as an example. They have transformed their business models by utilizing data. They increase revenue and retention of customers by offering personalized suggestions based on an analysis of consumer behavior. They also generate extra revenue by selling insights to outside parties, which is another way they monetize data. They have been able to disrupt established markets and prosper in the digital age because of their data-centric strategy.
However, the potential of data as an asset extends far beyond these tech giants. All organizations, no matter how big or little, produce and gather data. Data is essential for improving goods and services, finding new market possibilities, and optimizing operations in a variety of industries, including manufacturing, financial services, and healthcare. Acknowledging data on balance sheets as an asset is a natural first step towards appreciating its actual value. This action may result in a more complete and transparent representation of a business's worth, giving stakeholders a greater understanding of its potential for expansion and data-driven capabilities.
How can synthetic data help?
When it comes to data monetization techniques, synthetic data can be a useful tool. It helps businesses maximize their data resources and opens up new revenue streams. How?
- Protecting sensitive information
By using synthetic data, businesses can profit from their data assets and get insightful knowledge without disclosing private or sensitive information. This is particularly important in sectors like healthcare and finance that are governed by stringent privacy laws, since actual data frequently contains sensitive or personal information. Legacy data anonymization tools can destroy data quality and decrease the value of data assets.
- Creating synthetic data marketplaces
It is possible to create data marketplaces using synthetic datasets, in which companies can provide insightful information to researchers, data scientists, and other enterprises. By selling or licensing these artificially generated datasets, new revenue streams may be generated.
- Enhancing data products
Synthetic data may be used by organizations that offer data services and products to improve and expand their product offerings. They can combine real and synthetic data to generate more comprehensive datasets that satisfy a wider range of customer expectations.
- Improve machine learning performance
Synthetic data offers a great upsampling method. It can be used in addition to real data to train machine learning models, increasing the models' accuracy and durability. This improved model performance can be quite helpful when offering predictive analytics services to clients.
- Risk mitigation
By using synthetic data for data monetization, the dangers of sharing real data can be reduced. Potential clients or partners may be more inclined to work together and invest in data-driven solutions as a result.
- Reducing data acquisition costs
Organizations can use synthetic data to address the needs of data-hungry applications and analytics while lowering expenses associated with data collection and storage, as opposed to continually collecting and storing real data.
- Enables data retention
Internal data retention policies and external legal requirements can make data retention impossible in the long run. However, the value of retaining data as an asset lies in its potential to provide historical insights, support trend analysis, and facilitate future decision-making. Retaining synthetic versions of datasets that must be deleted is a compliant and data-friendly solution, ensuring that the organizational knowledge base remains intact for strategic planning and informed decision-making while adhering to privacy and regulatory standards.
For the aforementioned reasons, synthetic data is an invaluable enabler that helps businesses maximize their data assets while resolving privacy issues and cutting expenses. It provides more assurance over data security and privacy compliance when entering into partnerships for data sharing, developing innovative data products, and expanding revenue streams.
Data monetization use cases
Synthetic data makes granular-level information accessible without requiring individual consent to share. This makes it possible for businesses to profit from their data assets while upholding data security and privacy, adhering to legal obligations, and making use of data-driven insights to improve decision-making and open up new revenue streams. This section will examine particular use cases from a variety of sectors, demonstrating how synthetic data can revolutionize data monetization by providing a competitive advantage and ensuring compliance with data protection laws.
- Data monetization in financial services
Financial institutions can use synthetic data in various ways — for example, to create credit scoring models and assess the risk of lending to individuals or businesses. By having access to granular-level information, they can make more informed decisions without violating data privacy regulations. Synthetic data can emulate the behavior of real customers without needing their consent. Banks can monetize this synthetic data by offering their advanced credit scoring and risk assessment models to other financial institutions or third-party vendors. These models, based on synthetic data, can provide valuable insights into creditworthiness and risk assessment. By licensing or selling these models, financial institutions can create an additional revenue stream while maintaining data privacy and security, making it a win-win scenario for both the bank and its partners.
- Marketing
Marketing firms can use synthetic data to segment customer profiles and create personalized marketing campaigns. This data can be shared with clients or partners without the need for individual customer consent. For example, banks can use synthetic data to optimize product recommendations for specific customer segments, creating personalized customer experiences and increasing customer satisfaction.
Marketing firms can monetize this valuable resource by offering their expertise in customer segmentation and their personalized marketing strategies based on synthetic data to other businesses in need of such services. By providing data-driven marketing solutions, marketing agencies can not only enhance their client offerings but also establish additional revenue streams through consulting and licensing agreements. This approach drives business growth and maintains the privacy and security of customer data, ensuring compliance with data protection regulations.
- Telecommunications
Telecommunications businesses can profit from synthetic data for network optimization. Network traffic and usage patterns can be simulated with synthetic data, which helps with infrastructure design and resource allocation. This may result in lower infrastructure costs and better service quality.
Telecommunication companies can generate money from this vital expertise, which is driven by synthetic data, by charging other service providers or companies looking to improve their network performance. Telecom firms can add value proposition products to their offerings and diversify their revenue streams by delivering data-driven network solutions based on synthetic data.
Conclusion
In this era of data-driven innovation, the power of synthetic data in data monetization cannot be overstated. It allows organizations to tap into the wealth of insights hidden within their data while upholding stringent privacy regulations and ensuring data security. From financial institutions fine-tuning credit risk models to marketing firms creating personalized campaigns and telecommunication companies optimizing networks, synthetic data is the key to unlocking new revenue streams.
For those seeking a private and secure synthetic data generation solution, MOSTLY AI's platform stands as a beacon. Our “private by default” synthetic data ensures that sensitive information remains protected while still enabling organizations to make the most of their data assets.
Ready to experience the benefits of synthetic data monetization with MOSTLY AI? Get started today by registering for our free version, and don't hesitate to contact us for more details. Your journey towards smarter, more profitable data-driven decisions begins here.
Data governance is a data management framework that ensures data is accurate, accessible, consistent, and protected. For Chief Information Officers (CIOs), it’s also the strategic blueprint that communicates how data is handled and protected across the organization.
Governance ensures that data can be used effectively, ethically, and in compliance with regulations while implementing policies to safeguard against breaches or misuse. As a CIO, mastering data governance requires a delicate balance between maintaining trust, privacy, and control of valuable data assets while investing in innovation and long-term business growth.
Ultimately, successful business innovation depends on data innovation. CIOs can build a collaborative, innovative culture based on data governance where every executive stakeholder feels a closer ownership of digital initiatives.
Partnerships for data governance: the CIO priority in 2024
In 2024, Gartner forecasts that CIOs will be increasingly asked to do more with less: with tighter budgets and a watchful eye on efficiency needed to meet growing demands around digital leadership, delivery, and governance.
CIOs find themselves at a critical moment that requires managing a complex digital landscape and operating model and taking responsibility and ownership for technology-enabled innovation around data, analytics, and artificial intelligence (AI).
These emerging priorities demand a new approach to data governance. CIOs and other C-suite executives must rethink their collaboration strategies. By tapping into domain expertise and building communities of practice, organizations can cut costs and reduce operational risks. This transformation helps reposition CIOs as vital strategic partners within their organizations.
Among the newest tools for CIOs is AI-generated synthetic data, which stands out as a game-changer. It sparks innovation and fosters trusted relationships between business divisions, providing a secure and versatile base for data-driven initiatives. Synthetic data is fast becoming an everyday data governance tool used by AI-savvy CIOs.
What is AI-generated synthetic data?
Synthetic data is created using AI. It replicates the statistical properties of real-world data but keeps sensitive details private. Synthetic data can be safely used instead of the original data — for example, as training data for building machine learning models and as privacy-safe versions of datasets for data sharing.
This characteristic is invaluable for CIOs who manage risk and cybersecurity, work to contract with external parties for innovation or outsourced development, or lead teams to deploy data analytics, AI, or digital platforms. This makes synthetic data a tool to transform data governance throughout organizations.
Synthetic data can be safely used instead of the original data—for example, as training data for building machine learning models and as privacy-safe versions of datasets for data sharing.
Synthetic data use cases are far-reaching, particularly in enhancing AI models, improving application testing, and reducing regulatory risk. With a synthetic data approach, CIOs and data leaders can drive data democratization and digital delivery without the logistical issues of data procurement, data privacy, and traditionally restrictive governance controls.
Synthetic data is an artificial version of your real data
Synthetic data is NOT
mock data
Synthetic data is smarter than data anonymization
Three CIO strategies for improved delivery with synthetic data
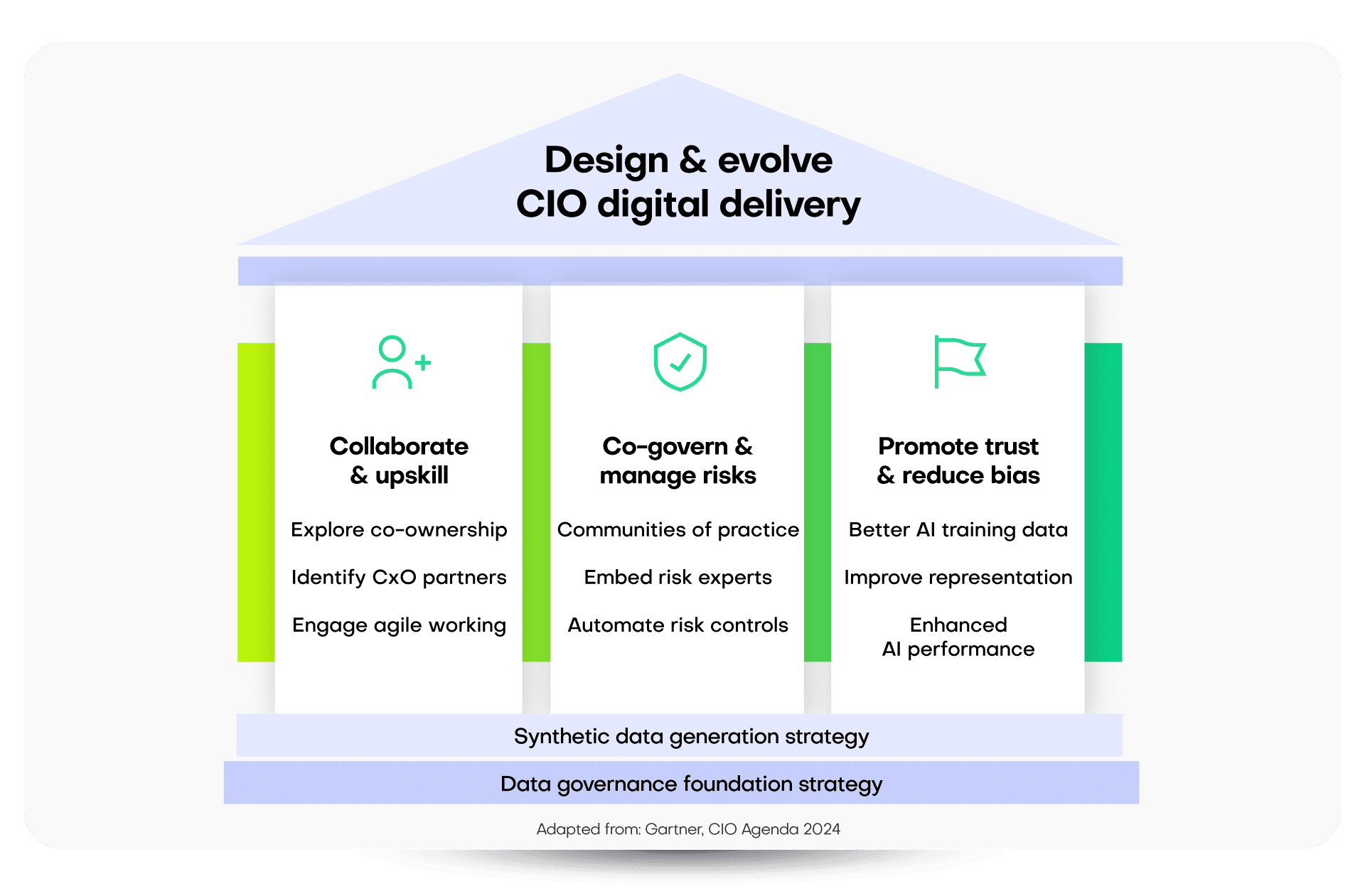
To understand the impact of synthetic data on data governance, consider the evolving role of CIOs:
- Traditional Role: 55% of CIOs surveyed maintain complete control over their digital and technical domains.
- Shift to Partnership: Conversely, 12% of CIOs now share responsibilities for digital delivery, embracing equal partnerships with their business counterparts.
The real surprise from Gartner’s findings comes from the actual outcomes of these reported digital projects, with a stark, inverse relationship between pure CIO ownership and the ability to meet or exceed project targets. Indeed, only 43% of digital initiatives meet this threshold when CIOs are in complete control, versus 63% for projects where the CIO co-leads delivery with other CxO executives.
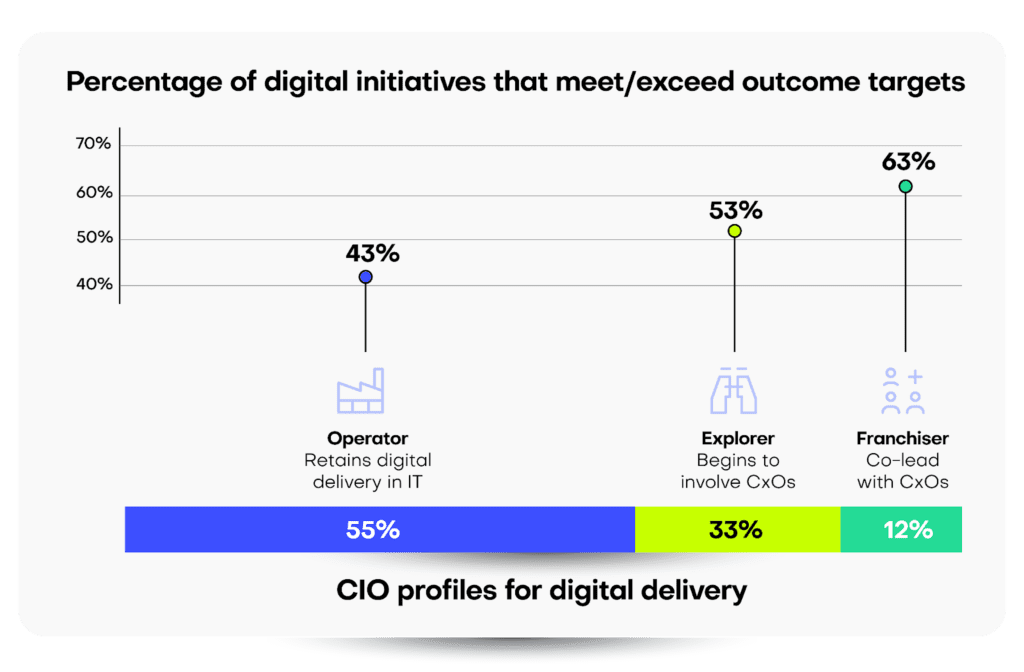
When CIOs retain full delivery control, only 43% of digital initiatives meet or exceed their outcome targets.
So, how can CIOs leverage synthetic data to drive successful business innovation across the enterprise? What steps should a traditional Chief Information Officer take to move from legacy practices to an operating model that shares leadership, delivery, and data governance?
Strategy 1: Upskilling with synthetic data
Enhancing collaboration between CIOs and business leaders
As business and technology teams work more closely together to develop digital solutions, synthetic data can bridge the gap between these groups.
To educate and equip business leaders with the skills they need to co-lead digital initiatives, there are shared challenges to overcome. Pain points are no longer simply an “IT issue,” and new, agile ways of working are needed that share responsibility between previously siloed teams.
In these first steps, synthetic data can feel like uncharted territory, with great opportunities to democratize data across the organization and recreate real-world scenarios without compromising privacy or confidentiality.
As business and technology teams work more closely together to develop digital solutions, synthetic data can bridge the gap between these groups, offering safe and effective development and testing environments for new platforms or applications or providing domain experts with valuable insights without risking the underlying data assets.
Strategy 2: Risk management through synthetic data
Creating safe, collaborative spaces for cross-functional teams
Synthetic data alleviates the risk typically associated with sharing sensitive information, while enabling partners access to the depth of data required for meaningful innovation and delivery.
A shared responsibility model democratizes digital technology delivery, with synthetic data serving as common ground for various CxOs to collaborate on business initiatives in a safe, versatile environment.
Communities of practice (CoPs) ensure that autonomy is balanced with a collective feedback structure that can collect and centralize best practices from domain experts without overburdening a project with excessive bureaucracy.
This approach can also extend beyond traditional organizational boundaries—for example, contracting with external parties. Synthetic data alleviates the risk typically associated with sharing sensitive information (especially outside of company walls) while enabling partners access to the depth of data required for meaningful innovation and delivery.
Strategy 3: Cultural shifts in AI delivery
Using synthetic data to promote ethical AI practices
Feeding AI models better training data leads to more precise personalization, stronger fraud detection capabilities, and enhanced customer experiences.
Business demand for AI far outstrips supply on CIOs’ 2024 roadmaps. Synthetic data addresses this challenge by:
- Promoting Trust: Synthetic data allows precise control over its generation process. This enables analysts to investigate outlier data points thoroughly. Additionally, it aids data scientists in explaining and stress-testing AI models to guarantee fair representation and consistent reliability for diverse use cases.
- Reducing Bias: Synthetic data generation can rebalance data distribution across data categories without losing integrity or detail.
- Enhanced Performance: Feeding AI models better training data leads to more precise personalization, robust fraud detection capabilities, and improved customer experiences.
However, adopting synthetic data in co-led teams isn’t just a technical approach; it’s cultural, too. CIOs can lead from the front and underscore their commitment to social responsibility by promoting ethical data practices to challenge data bias or representation issues. Shlomit Yanisky-Ravid, a professor at Fordham University’s School of Law, says that it’s imperative to understand what an AI model is really doing; otherwise, we won’t be able to think about the ethical issues around it. “CIOs should be engaging with the ethical questions around AI right now,” she says. “If you wait, it’s too late.”
The data governance journey for CIOs: From technology steward to C-suite partner
A successful digital delivery operating model requires a rethink in the ownership and control of traditional CIO responsibilities. Who should lead an initiative? Who should deliver key functionality? Who should govern the resulting business platform?
The results from Gartner’s survey provide some answers to these questions. They point clearly to the effectiveness of shared responsibility — working across C-suite executives for delivery versus a more siloed approach.
Here’s how CIOs can navigate this journey:
- Encourage experimentation: Build a culture that embraces synthetic data to achieve rapid prototyping and iterative feedback for digital delivery.
- Bridge the IT-Business divide: Use synthetic data to democratize data and share digital delivery responsibilities across the C-suite.
- Expand collaboration: When data privacy or intellectual property concerns restrict data sharing, synthetic data can enable collaboration, allowing for innovation or external partnerships without increased risks.
Ultimately, successful business innovation depends on data innovation. CIOs can build a collaborative, innovative culture based on data governance where every executive stakeholder feels a closer ownership of digital initiatives.
Synthetic data enables different departments to innovate without direct reliance on overburdened IT departments. When real-world data is slow to provision and often loaded with ethical or privacy restrictions, synthetic data offers a new approach to collaboration and digital delivery.
With these strategic initiatives on the corporate agenda for 2024 and beyond, CIOs must find new and efficient ways to deliver value through partnerships while building stronger strategic relationships between executives.
Advancing data governance initiatives with synthetic data
For CIOs ready to take the next step, embracing synthetic data within a data governance strategy is just the beginning. Discover more about how synthetic data can revolutionize your enterprise!
Get in touch for a personalized demo
In this tutorial, you will learn how to tackle the problem of missing data in an efficient and statistically representative way using smart, synthetic data imputation. You will use MOSTLY AI’s Smart Imputation feature to uncover the original distribution for a dataset with a significant percentage of missing values. This skill will give you the confidence to tackle missing data in any data analysis project.
Dealing with datasets that contain missing values can be a challenge. The presence of missing values can make the rest of your dataset non-representative, which means that it provides a distorted, biased picture of the overall population you are trying to study. Missing values can also be a problem for your machine learning applications, specifically when downstream models are not able to handle missing values. In all cases, it is crucial that you address the missing values as accurately and statistically representative as possible to avoid valuable data loss.
To tackle the problem of missing data, you will use the data imputation capability of MOSTLY AI’s free synthetic data generator. You will start with a modified version of the UCI Adult Income dataset that has a significant portion (~30%) of missing values for the age column. These missing values have been intentionally inserted at random, with a specific bias for the older segments of the population. You will synthesize this dataset and enable the Smart Imputation feature, which will generate a synthetic dataset that does not contain any missing values. With this smartly imputed synthetic dataset, it is then straightforward to accurately analyze the population as if all values were present in the first place.
The Python code for this tutorial is publicly available and runnable in this Google Colab notebook.
Dealing with missing data
Missing data is a common problem in the world of data analysis and there are many different ways to deal with it. While some may choose to simply disregard the records with missing values, this is generally not advised as it causes you to lose valuable data for the other columns that may not have missing data. Instead, most analysts will choose to impute the missing values.
This can be a simple data imputation by, for example, calculating the mean or median value of the column and using this to fill in the missing values. There are also more advanced data imputation methods available. Read the article comparing data imputation methods to explore some of these techniques and learn how MOSTLY AI’s Smart Imputation feature outperforms other data imputation techniques.
Explore the original data
Let’s start by taking a look at our original dataset. This is the modified version of the UCI Adult Income dataset with ~30% missing values for the age column.
If you’re following along in Google Colab, you can run the code below directly. If you are running the code locally, make sure to set the repo variable to the correct path.
import pandas as pd
import numpy as np
# let's load the original data file, that includes missing values
try:
from google.colab import files # check whether we are in Google colab
repo = "https://github.com/mostly-ai/mostly-tutorials/raw/dev/smart-imputation"
except:
repo = "."
# load the original data, with missing values in place
tgt = pd.read_csv(f"{repo}/census-with-missings.csv")
print(
f"read original data with {tgt.shape[0]:,} records and {tgt.shape[1]} attributes"
)Let’s take a look at 10 random samples:
# let's show some samples
tgt[["workclass", "education", "marital-status", "age"]].sample(
n=10, random_state=42
)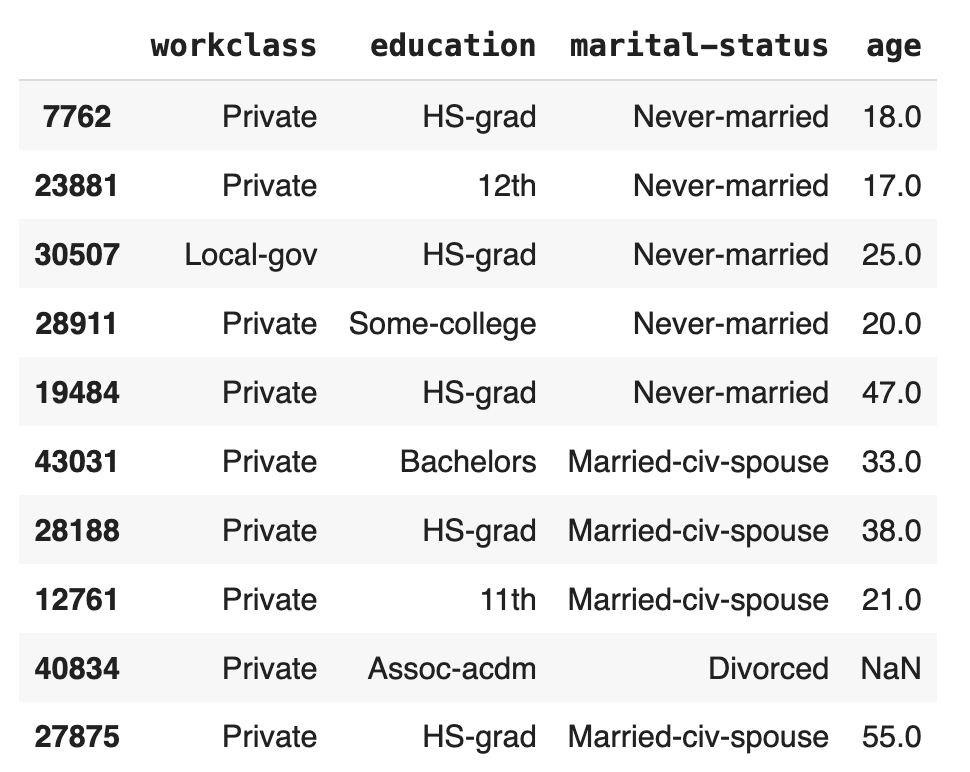
We can already spot 1 missing value in the age column.
Let’s confirm how many missing values we are actually dealing with:
# report share of missing values for column `age`
print(f"{tgt['age'].isna().mean():.1%} of values for column `age` are missing")32.7% of values for column `age` are missing
Almost one-third of the age column contains missing values. This is a significant amount of relevant data – you would not want to discard these records from your analysis.
Let’s also take a look to see what the distribution of the age column looks like with these missing values.
# plot distribution of column `age`
import matplotlib.pyplot as plt
tgt.age.plot(kind="kde", label="Original Data (with missings)", color="black")
_ = plt.legend(loc="upper right")
_ = plt.title("Age Distribution")
_ = plt.xlim(13, 90)
_ = plt.ylim(0, None)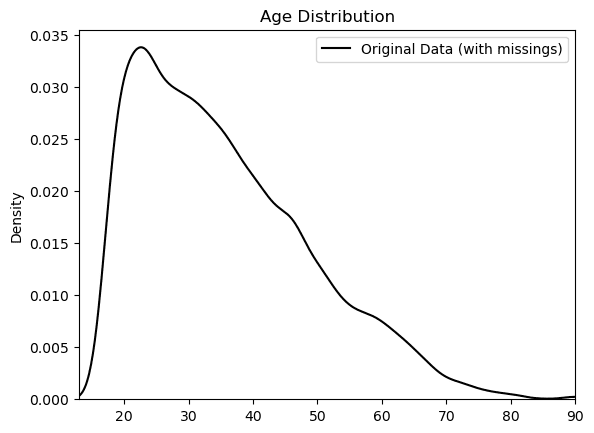
This might look reasonable but remember that this distribution is showing you only two-thirds of the actual population. If you were to analyze or build machine learning models on this dataset as it is, chances are high that you would be working with a significantly distorted view of the population which would lead to poor analysis results and decisions downstream.
Let’s take a look at how we can use MOSTLY AI’s Smart Imputation method to address the missing values and improve the quality of your analysis.
Synthesize data with smart data imputation
Follow the steps below to download the dataset and synthesize it using MOSTLY AI. For a step-by-step walkthrough, you can also watch the video tutorial.
- Download
census-with-missings.csvby clicking here and pressing either Ctrl+S or Cmd+S to save the file locally. - Synthesize
census-with-missings.csvvia MOSTLY AI. Leave all settings at their default, but activate the Smart Imputation for the age column.
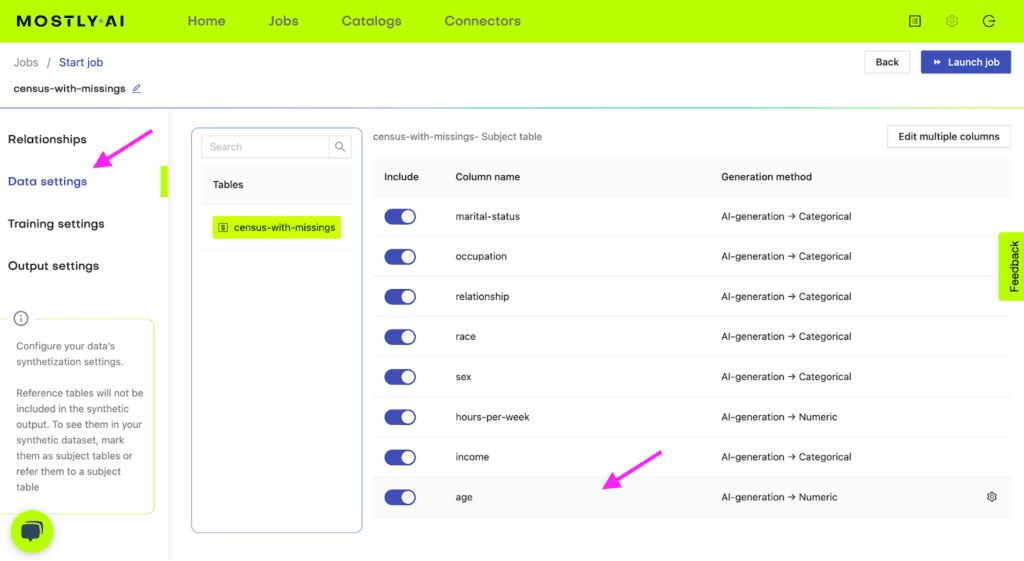
Fig 1 - Navigate to Data Setting and select the age column.
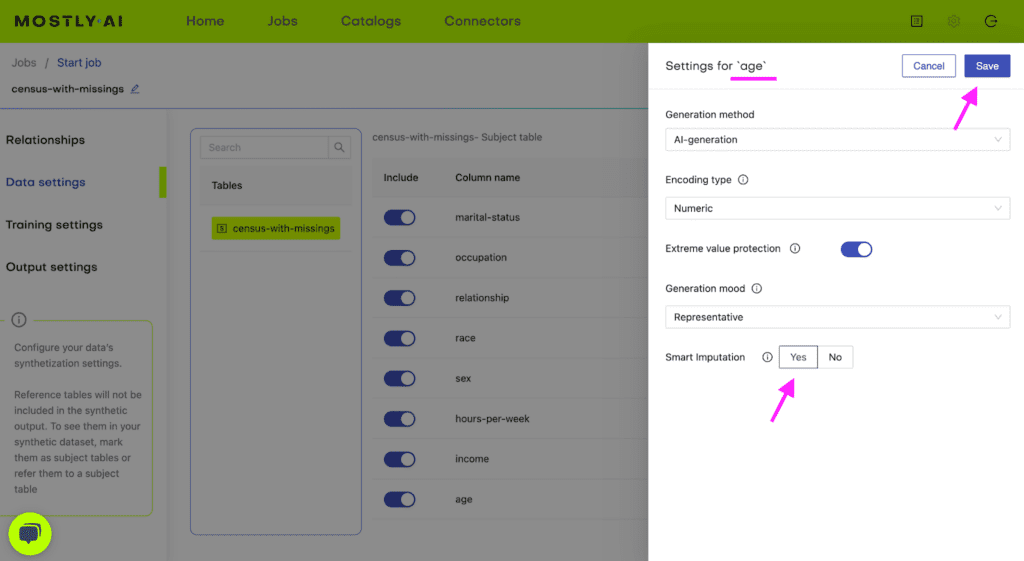
Fig 2 - Enable the Smart Imputation feature for the age column.
- Once the job has finished, download the generated synthetic data as a CSV file to your computer and rename it to
census-synthetic-imputed.csv. Optionally, you can also download a previously synthesized version here.
- Use the following code to upload the synthesized data if you’re running in Google Colab or to access it from disk if you are working locally:
# upload synthetic dataset
import pandas as pd
try:
# check whether we are in Google colab
from google.colab import files
import io
uploaded = files.upload()
syn = pd.read_csv(io.BytesIO(list(uploaded.values())[0]))
print(
f"uploaded synthetic data with {syn.shape[0]:,} records and {syn.shape[1]:,} attributes"
)
except:
syn_file_path = f"{repo}/census-synthetic-imputed.csv"
print(f"read synthetic data from {syn_file_path}")
syn = pd.read_csv(syn_file_path)
print(
f"read synthetic data with {syn.shape[0]:,} records and {syn.shape[1]:,} attributes"
)Now that we’ve had an overall look at the distributions of the underlying model and the generated synthetic data, let’s dive a little deeper into the synthetic data you’ve generated.
Like before, let’s sample 10 random records to see if we can spot any missing values:
# show some synthetic samples
syn[["workclass", "education", "marital-status", "age"]].sample(
n=10, random_state=42
)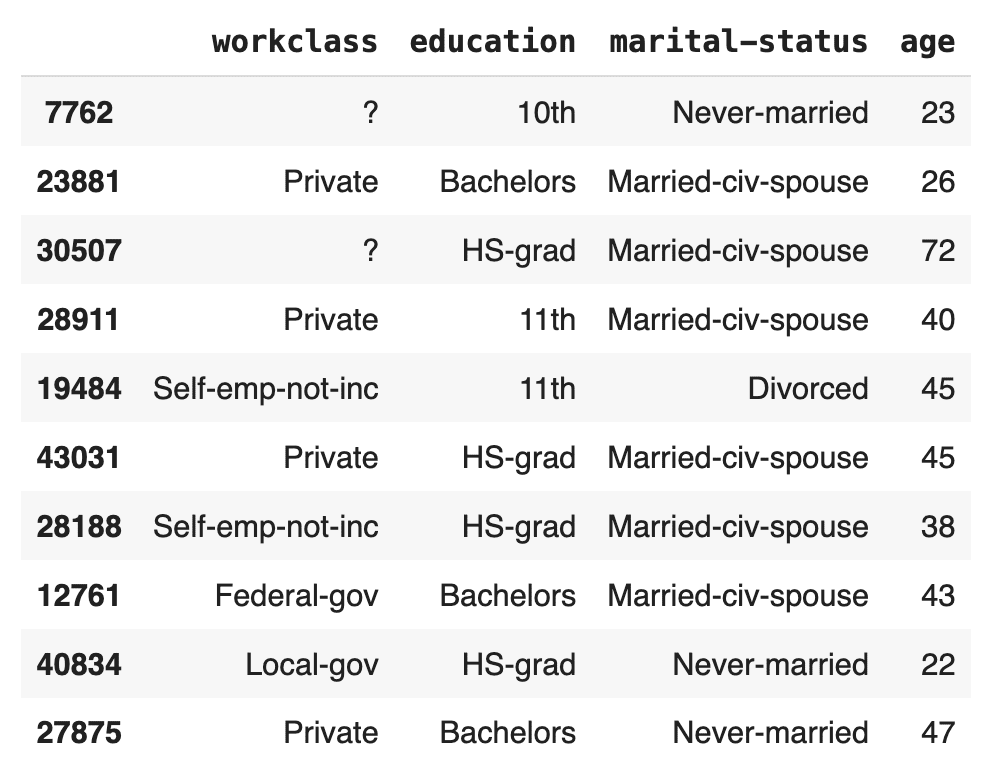
There are no missing values for the age column in this random sample. Let’s verify the percentage of missing values for the entire column:
# report share of missing values for column `age`
print(f"{syn['age'].isna().mean():.1%} of values for column `age` are missing")0.0% of values for column `age` are missing
We can confirm that all the missing values have been imputed and that we no longer have any missing values for the age column in our dataset.
This is great, but only half of the story. Filling the gaps in our missing data is the easy part: we could do this by simply imputing the mean or the median, for example. It’s filling the gaps in a statistically representative manner that is the challenge.
In the next sections, we will inspect the quality of the generated synthetic data to see how well the Smart Imputation feature performs in terms of imputing values that are statistically representative of the actual population.
Inspecting the synthetic data quality reports
MOSTLY AI provides two Quality Assurance (QA) reports for every synthetic data generation job: a Model QA and a Data QA report. You can access these by clicking on a completed generation job and selecting the Model QA tab.
Fig 3 - Access the QA Reports in your MOSTLY AI account.
The Model QA reports on the accuracy and privacy of the trained Generative AI model. As you can see, the distributions of the training dataset are faithfully learned and also include the right share of missing values:
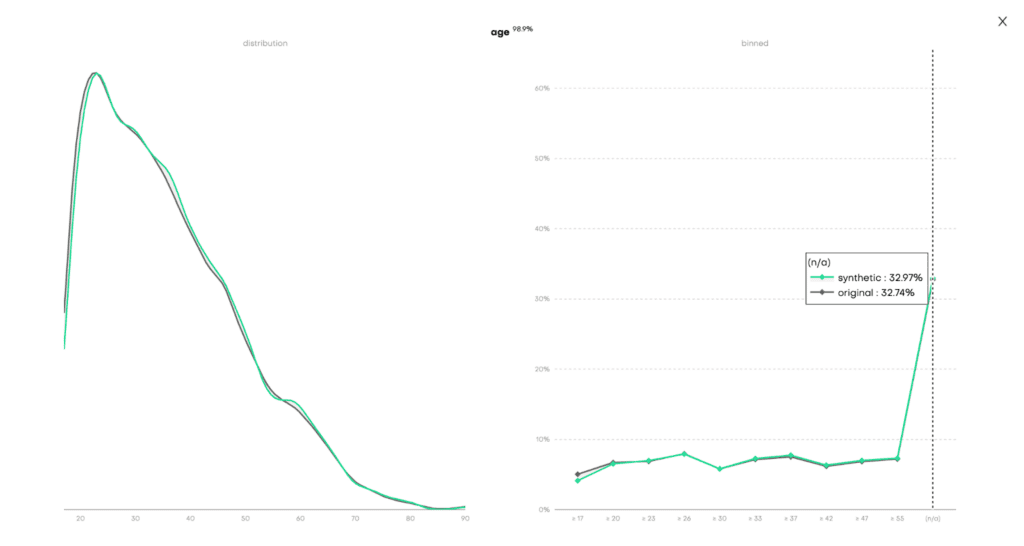
Fig 4 - Model QA report for the univariate distribution of the age column.
The Data QA, on the other hand, visualizes the distributions not of the underlying model but of the outputted synthetic dataset. Since we enabled the Smart Imputation feature, we expect to see no missing values in our generated dataset. Indeed, here we can see that the share of missing values (N/A) has dropped to 0% in the synthetic dataset (vs. 32.74% in the original) and that the distribution has been shifted towards older age buckets:
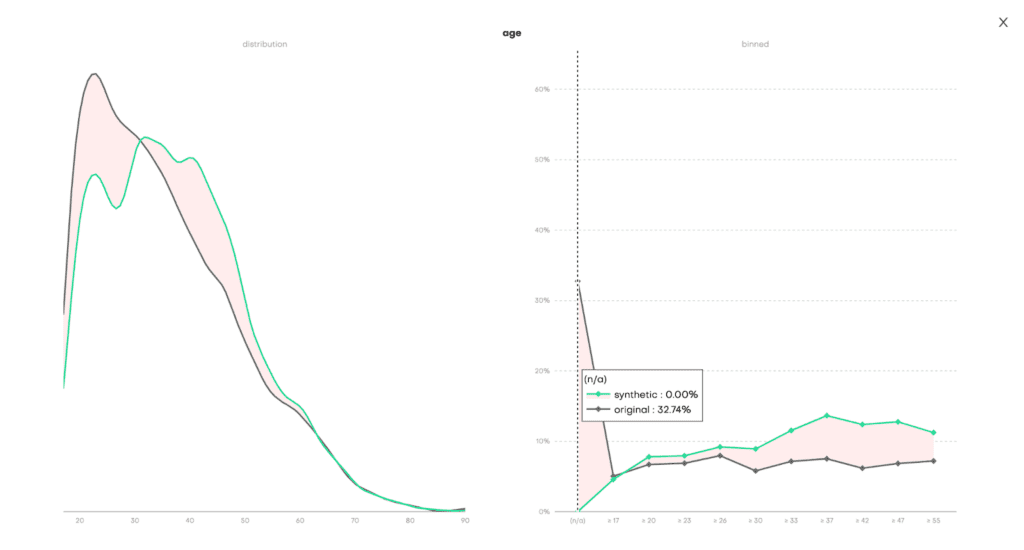
Fig 5 - Data QA report for the univariate distribution of the age column.
The QA reports give us a first indication of the quality of our generated synthetic data. But the ultimate test of our synthetic data quality will be to see how well the synthetic distribution of the age column compares to the actual population: the ground truth UCI Adult Income dataset without any missing values.
Let’s plot side-by-side the distributions of the age column for:
- The original training dataset (incl. ~33% missing values),
- The smartly imputed synthetic dataset, and
- The ground truth dataset (before the values were removed).
Use the code below to create this visualization:
raw = pd.read_csv(f"{repo}/census-ground-truth.csv")
# plot side-by-side
import matplotlib.pyplot as plt
tgt.age.plot(kind="kde", label="Original Data (with missings)", color="black")
raw.age.plot(kind="kde", label="Original Data (ground truth)", color="red")
syn.age.plot(kind="kde", label="Synthetic Data (imputed)", color="green")
_ = plt.title("Age Distribution")
_ = plt.legend(loc="upper right")
_ = plt.xlim(13, 90)
_ = plt.ylim(0, None)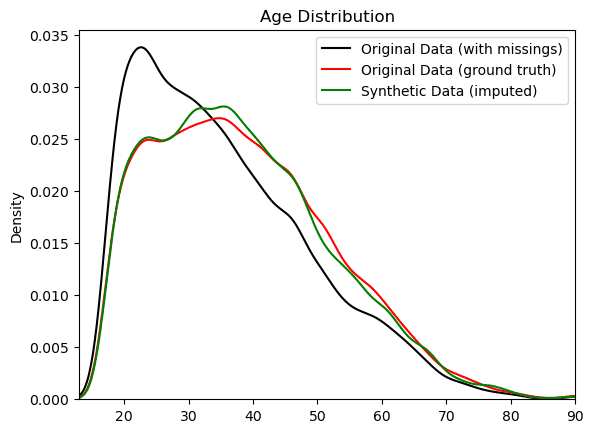
As you can see, the smartly imputed synthetic data is able to recover the original, suppressed distribution of the ground truth dataset. As an analyst, you can now proceed with the exploratory and descriptive analysis as if the values were present in the first place.
Tackling missing data with MOSTLY AI's data imputation feature
In this tutorial, you have learned how to tackle the problem of missing values in your dataset in an efficient and highly accurate way. Using MOSTLY AI’s Smart Imputation feature, you were able to uncover the original distribution of the population. This then allows you to proceed to use your smartly imputed synthetic dataset and analyze and reason about the population with high confidence in the quality of both the data and your conclusions.
If you’re interested in learning more about imputation techniques and how the performance of MOSTLY AI’s Smart Imputation feature compares to other imputation methods, check out our smart data imputation article.
You can also head straight to the other synthetic data tutorials:
- Generate synthetic text data
- Explainable AI with synthetic data
- Perform conditional data generation
- Rebalancing your data for ML classification problems
- Optimize your training sample size for synthetic data accuracy
- Build a “fake vs real” ML classifier
As we wrap up 2023, the corporate world is abuzz with the next technological wave: Enterprise AI. Over the past few years, AI has taken center stage in conversations across newsfeeds and boardrooms alike. From the inception of neural networks to the emergence of companies like Deepmind at Google and the proliferation of Deepfake videos, AI's influence has been undeniable.
While some are captivated by the potential of these advancements, others approach them with caution, emphasizing the need for clear boundaries and ethical guidelines. Tech visionaries, including Elon Musk, have voiced concerns about AI's ethical complexities and potential dangers when deployed without stringent rules and best practices. Other advocates of AI skepticism include Timnit Gebru, one of the first people to sound alarms at Google, Dr. Hinton, the godfather of AI and even Sam Altman, CEO of OpenAI, voiced concerns, as well as the renowned historian Yuval Harari.
Now, Enterprise AI is knocking on the doors of corporate boardrooms, presenting executives with a familiar challenge: the eternal dilemma of adopting new technology. Adopt too early, and you risk venturing into the unknown, potentially inviting reputational and financial damage. Adopt too late, and you might miss the efficiency and cost-cutting opportunities that Enterprise AI promises.
What is Enterprise AI?
Enterprise AI, also known as Enterprise Artificial Intelligence, refers to the application of artificial intelligence (AI) technologies and techniques within large organizations or enterprises to improve various aspects of their operations, decision-making processes, and customer interactions. It involves leveraging AI tools, machine learning algorithms, natural language processing, and other AI-related technologies to address specific business challenges and enhance overall efficiency, productivity, and competitiveness.
In a world where failing to adapt has led to the downfall of organizations, as witnessed in the recent history of the banking industry with companies like Credit Suisse, the pressure to reduce operational costs and stay competitive is more pressing than ever. Add to this mix the current macroeconomic landscape, with higher-than-ideal inflation and lending rates, and the urgency for companies not to be left behind becomes palpable.
Moreover, many corporate leaders still find themselves grappling with the pros and cons of integrating the previous wave of technologies, such as blockchain. Just as the dust was settling on blockchain's implementation, AI burst into the spotlight. A limited understanding of how technologies like neural networks function, coupled with a general lack of comprehension regarding their potential business applications, has left corporate leaders facing a perfect storm of FOMO (Fear of Missing Out) and FOCICAD (Fear of Causing Irreversible Chaos and Damage).
So, how can industry leaders navigate the world of Enterprise AI without losing their footing and potentially harming their organizations? The answer lies in combining traditional business processes and quality management with cutting-edge auxiliary technologies to mitigate the risks surrounding AI and its outputs. Here are the questions which QuantumBlack, AI by McKinsey, suggests boards to ask about generative AI.
Laying the foundation for Enterprise AI adoption
To embark on a successful Enterprise AI journey, companies need to build a strong foundation. This involves several crucial steps:
- Data Inventories: Conduct thorough data inventories to gain a comprehensive understanding of your organization's data landscape. This step helps identify the type of data available, its quality, and its relevance to AI initiatives.
- Assess Data Architectures: Evaluate your existing data structures and systems to determine their compatibility with AI integration. Consider whether any modifications or updates are necessary to ensure smooth data flow and accessibility.
- Cost Estimation: Calculate the costs associated with adopting AI, including labor for data preparation and model development, technology investments, and change management expenses. This step provides a realistic budget for your AI initiatives.
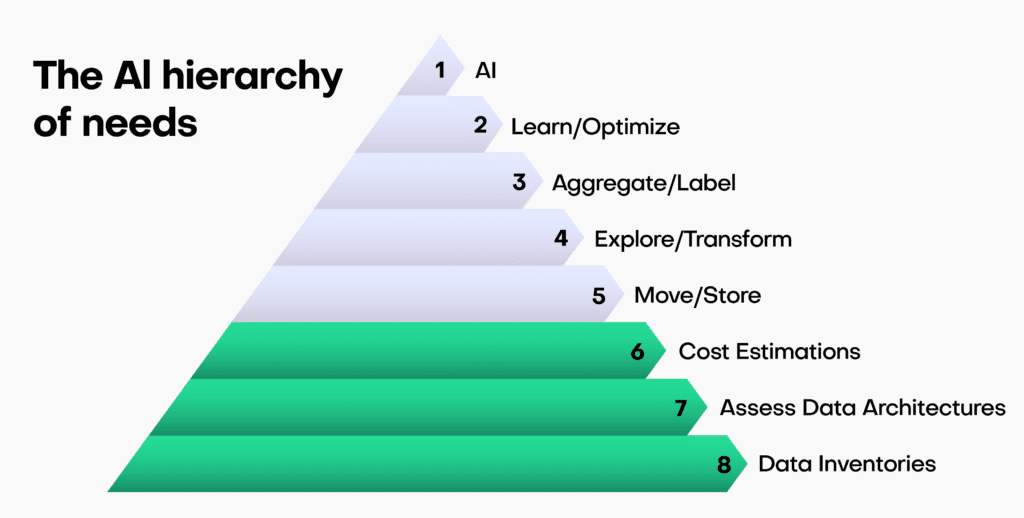
By following these steps, organizations can lay the groundwork for a successful AI adoption strategy. It helps in avoiding common pitfalls related to data quality and infrastructure readiness.
Leveraging auxiliary technologies in Enterprise AI
In a recent survey by a large telecommunications company, half of all respondents said they wait up to one month for privacy approvals before they can proceed with their data processing and analytics activities. Data Processing Agreements (DPAs), Secure by Design processes, and further approvals are the main reasons behind these high lead times.
The demand for quicker, more accessible, and statistically representative data makes the case that real and mock data just aren't good enough to meet these (somewhat basic) requirements.
On the other side, however, The Wall Street Journal has recently reported that big tech companies such as Microsoft, Google, and Adobe are struggling to make AI technology profitable as they attempt to integrate it into their existing products.
The dichotomy we see here can put decision-makers into a state of paralysis: the need to act is imminent, but the price of poor action is high. Trustworthy and competent guidance, along with a sound strategy, is the only way out of the AI rabbit hole and towards AI-based solutions that can be monetized and thereby target and alleviate corporate pain points.
One of the key strategies to mitigate the risks associated with AI adoption is to leverage auxiliary technologies. These technologies act as force multipliers, enhancing the efficiency and safety of AI implementations. Recently, European lawmakers specifically included synthetic data in the draft of the EU's upcoming AI Act, as a data type explicitly suitable for building AI systems.
In this context, MOSTLY AI's Synthetic Data Platform emerges as a powerful ally. This innovative platform offers synthetic data generation capabilities that can significantly aid in AI development and deployment. Here's how it can benefit your organization:
- Enhancing Data Privacy: Synthetic data allows organizations to work with data that resembles their real data but contains no personally identifiable information (PII). This ensures compliance with data privacy regulations, such as GDPR and HIPAA.
- Reducing Data Bias: The platform generates synthetic data that is free from inherent biases present in real data. This helps in building fair and unbiased AI models, reducing the risk of discrimination.
- Accelerating AI Development: Synthetic data accelerates AI development by providing a diverse dataset that can be used for training and testing models. It reduces the time and effort required to collect and clean real data.
- Testing AI Systems Safely: Organizations can use synthetic data to simulate various scenarios and test AI systems without exposing sensitive or confidential information.
- Cost Efficiency: Synthetic data reduces the need to invest in expensive data collection and storage processes, making AI adoption more cost-effective.
By incorporating MOSTLY AI's Synthetic Data Platform into your AI strategy, you can significantly reduce the complexities and uncertainties associated with data privacy, bias, and development timelines.
Enterprise AI example: ChatGPT's Code Interpreter
To illustrate the practical application of auxiliary technologies, let's consider a concrete example: Chat GPT's code interpreter in conjunction with MOSTLY AI’s Synthetic Data Platform. This innovative duo-tool plays a pivotal role in ensuring companies can harness the power of AI while maintaining safety and compliance. Business teams can feed statistically meaningful synthetic data into their corporate ChatGPT instead of real corporate data and thereby meet both data accuracy and privacy objectives.
Defining guidelines and best practices for Enterprise AI
Before diving into Enterprise AI implementation, it's essential to set clear guidelines and best practices. This involves:
- Scope and Planning Strategy: Define the scope of your AI implementation, aligning it with your organization's strategic objectives. Create a comprehensive plan that outlines the steps, timelines, and resources required for a successful AI deployment.
Embracing auxiliary technologies
In the context of auxiliary technologies, MOSTLY AI's Synthetic Data Platform is an invaluable resource. This platform provides organizations with the ability to generate synthetic data that closely mimics their real data, without compromising privacy or security.
Insight: The combination of setting clear guidelines and leveraging auxiliary technologies like MOSTLY AI's Synthetic Data Platform ensures a smoother and safer AI journey for organizations, where innovation can thrive without fear of adverse consequences.
The transformative force of Enterprise AI
In summary, Enterprise AI is no longer a distant concept but a transformative force reshaping the corporate landscape. The challenges it presents are real, as are the opportunities.
We've explored the delicate balance executives must strike when considering AI adoption, the ethical concerns that underscore this technology, and a structured approach to navigate these challenges. Auxiliary technologies like MOSTLY AI's Synthetic Data Platform serve as indispensable tools, allowing organizations to harness the full potential of AI while safeguarding against risks.
As you embark on your Enterprise AI journey, remember that the right tools and strategies can make all the difference. Explore MOSTLY AI's Synthetic Data Platform to discover how it can enhance your AI initiatives and keep your organization on the path to success. With a solid foundation and the right auxiliary technologies, the future of Enterprise AI holds boundless possibilities.
If you would like to know more about synthetic data, we suggest trying MOSTLY AI's free synthetic data generator, using one of the sample dataets provided within the app or reach out to us for a personalized demo!
In this tutorial, you will learn how to build a machine-learning model that is trained to distinguish between synthetic (fake) and real data records. This can be a helpful tool when you are given a hybrid dataset containing both real and fake records and want to be able to distinguish between them. Moreover, this model can serve as a quality evaluation tool for any synthetic data you generate. The higher the quality of your synthetic data records, the harder it will be for your ML discriminator to tell these fake records apart from the real ones.
You will be working with the UCI Adult Income dataset. The first step will be to synthesize the original dataset. We will start by intentionally creating synthetic data of lower quality in order to make it easier for our “Fake vs. Real” ML classifier to detect a signal and tell the two apart. We will then compare this against a synthetic dataset generated using MOSTLY AI's default high-quality settings to see whether the ML model can tell the fake records apart from the real ones.
The Python code for this tutorial is publicly available and runnable in this Google Colab notebook.
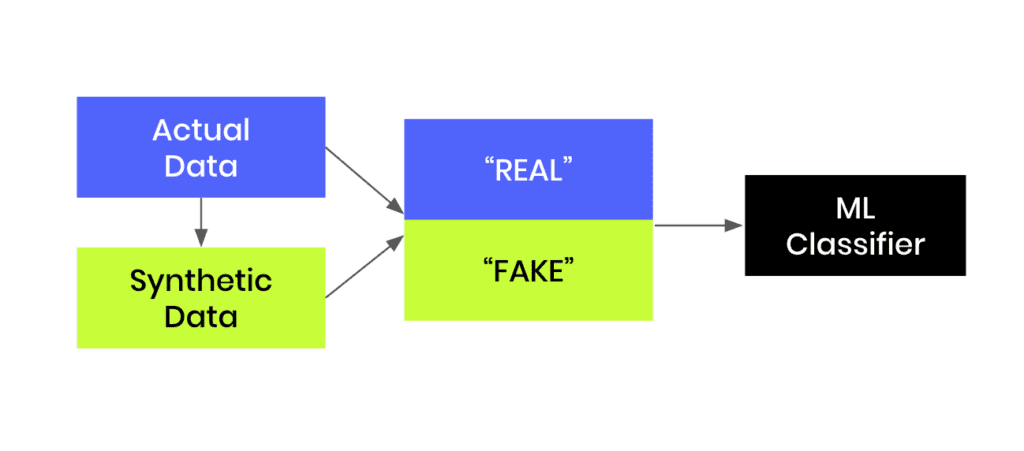
Fig 1 - Generate synthetic data and join this to the original dataset in order to train an ML classifier.
Create synthetic training data
Let’s start by creating our synthetic data:
- Download the original dataset here. Depending on your operating system, use either Ctrl+S or Cmd+S to save the file locally.
- Go to your MOSTLY AI account and navigate to “Synthetic Datasets”. Upload the CSV file you downloaded in the previous step and click “Proceed”.
- Set the Training Size to 1000. This will intentionally lower the quality of the resulting synthetic data. Click “Create a synthetic dataset” to launch the job.
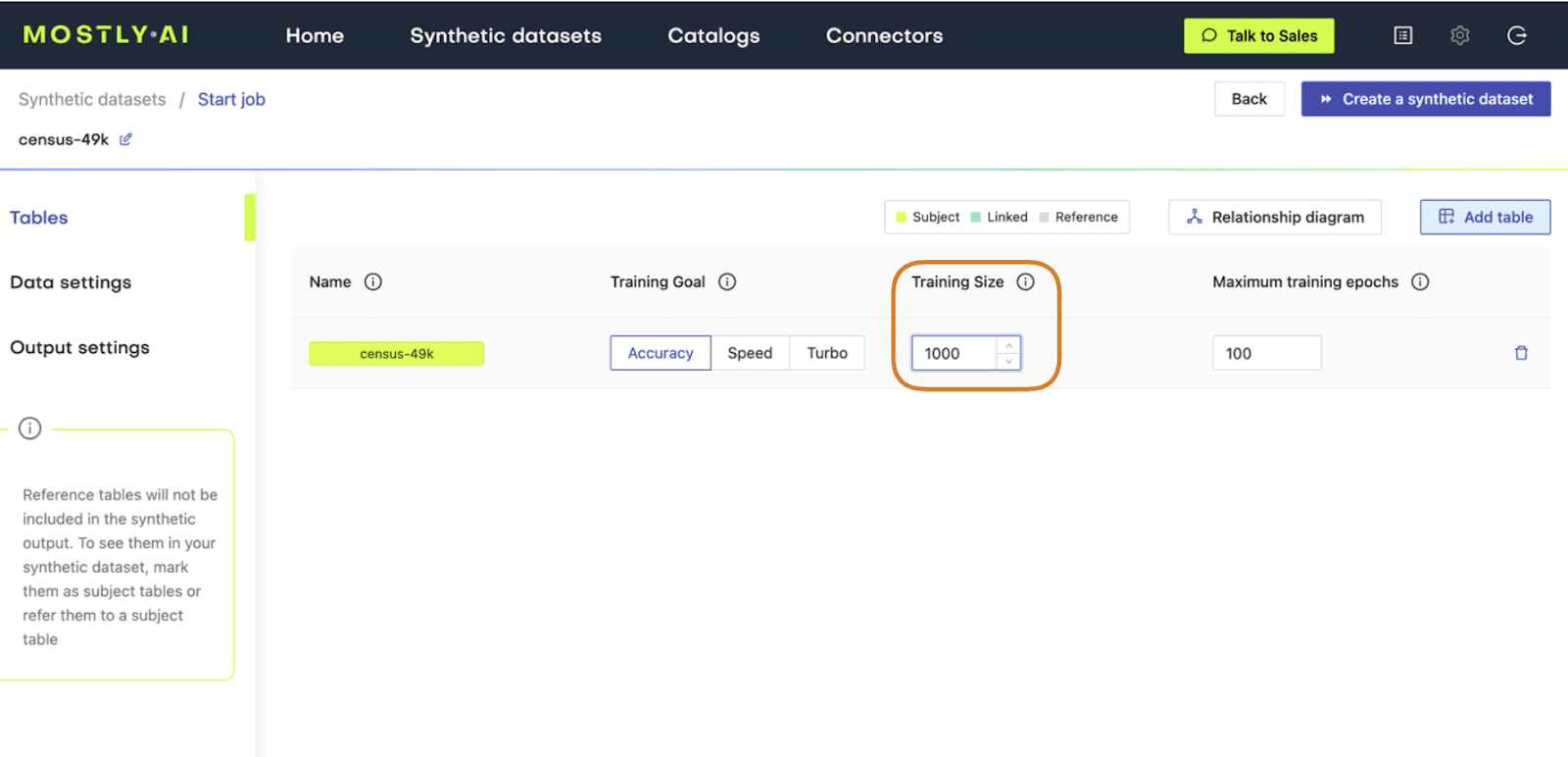
Fig 2 - Set the Training Size to 1000.
- Once the synthetic data is ready, download it to disk as CSV and use the following code to upload it if you’re running in Google Colab or to access it from disk if you are working locally:
# upload synthetic dataset
import pandas as pd
try:
# check whether we are in Google colab
from google.colab import files
print("running in COLAB mode")
repo = "https://github.com/mostly-ai/mostly-tutorials/raw/dev/fake-or-real"
import io
uploaded = files.upload()
syn = pd.read_csv(io.BytesIO(list(uploaded.values())[0]))
print(
f"uploaded synthetic data with {syn.shape[0]:,} records"
" and {syn.shape[1]:,} attributes"
)
except:
print("running in LOCAL mode")
repo = "."
print("adapt `syn_file_path` to point to your generated synthetic data file")
syn_file_path = "./census-synthetic-1k.csv"
syn = pd.read_csv(syn_file_path)
print(
f"read synthetic data with {syn.shape[0]:,} records"
" and {syn.shape[1]:,} attributes"
)Train your “fake vs real” ML classifier
Now that we have our low-quality synthetic data, let’s use it together with the original dataset to train a LightGBM classifier.
The first step will be to concatenate the original and synthetic datasets together into one large dataset. We will also create a split column to label the records: the original records will be labeled as REAL and the synthetic records as FAKE.
# concatenate FAKE and REAL data together
tgt = pd.read_csv(f"{repo}/census-49k.csv")
df = pd.concat(
[
tgt.assign(split="REAL"),
syn.assign(split="FAKE"),
],
axis=0,
)
df.insert(0, "split", df.pop("split"))Sample some records to take a look at the complete dataset:
df.sample(n=5)
We see that the dataset contains both REAL and FAKE records.
By grouping by the split column and verifying the size, we can confirm that we have an even split of synthetic and original records:
df.groupby('split').size()split
FAKE 48842
REAL 48842
dtype: int64
The next step will be to train your LightGBM model on this complete dataset. The following code contains two helper scripts to preprocess the data and train your model:
import lightgbm as lgb
from lightgbm import early_stopping
from sklearn.model_selection import train_test_split
def prepare_xy(df, target_col, target_val):
# split target variable `y`
y = (df[target_col] == target_val).astype(int)
# convert strings to categoricals, and all others to floats
str_cols = [
col
for col in df.select_dtypes(["object", "string"]).columns
if col != target_col
]
for col in str_cols:
df[col] = pd.Categorical(df[col])
cat_cols = [
col
for col in df.select_dtypes("category").columns
if col != target_col
]
num_cols = [
col for col in df.select_dtypes("number").columns if col != target_col
]
for col in num_cols:
df[col] = df[col].astype("float")
X = df[cat_cols + num_cols]
return X, y
def train_model(X, y):
cat_cols = list(X.select_dtypes("category").columns)
X_trn, X_val, y_trn, y_val = train_test_split(
X, y, test_size=0.2, random_state=1
)
ds_trn = lgb.Dataset(
X_trn, label=y_trn, categorical_feature=cat_cols, free_raw_data=False
)
ds_val = lgb.Dataset(
X_val, label=y_val, categorical_feature=cat_cols, free_raw_data=False
)
model = lgb.train(
params={"verbose": -1, "metric": "auc", "objective": "binary"},
train_set=ds_trn,
valid_sets=[ds_val],
callbacks=[early_stopping(5)],
)
return modelBefore training, make sure to set aside a holdout dataset for evaluation. Let’s reserve 20% of the records for this:
trn, hol = train_test_split(df, test_size=0.2, random_state=1)Now train your LightGBM classifier on the remaining 80% of the combined original and synthetic data:
X_trn, y_trn = prepare_xy(trn, 'split', 'FAKE')
model = train_model(X_trn, y_trn)Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[30] valid_0's auc: 0.594648
Next, score the model’s performance on the holdout dataset. We will include the model’s predicted probability for each record. A score of 1.0 indicates that the model is fully certain that the record is FAKE. A score of 0.0 means the model is certain the record is REAL.
Let’s sample some random records to take a look:
hol.sample(n=5)
We see that the model assigns varying levels of probability to the REAL and FAKE records. In some cases it is not able to predict with much confidence (scores around 0.5) and in others it is quite confident and also correct: see the 0.0727 for a REAL record and 0.8006 for a FAKE record.
Let’s visualize the model’s overall performance by calculating the AUC and Accuracy scores and plotting the probability scores:
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score, accuracy_score
auc = roc_auc_score(y_hol, hol.is_fake)
acc = accuracy_score(y_hol, (hol.is_fake > 0.5).astype(int))
probs_df = pd.concat(
[
pd.Series(hol.is_fake, name="probability").reset_index(drop=True),
pd.Series(y_hol, name="target").reset_index(drop=True),
],
axis=1,
)
fig = sns.displot(
data=probs_df, x="probability", hue="target", bins=20, multiple="stack"
)
fig = plt.title(f"Accuracy: {acc:.1%}, AUC: {auc:.1%}")
plt.show()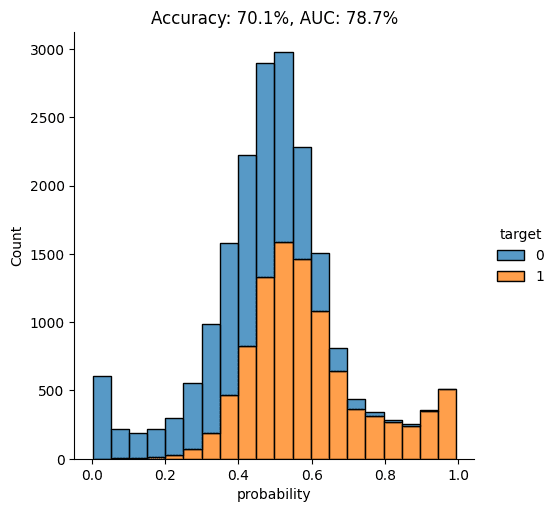
As you can see from the chart above, the discriminator has learned to pick up some signals that allow it with a varying level of confidence to determine whether a record is FAKE or REAL. The AUC can be interpreted as the percentage of cases in which the discriminator is able to correctly spot the FAKE record, given a set of a FAKE and a REAL record.
Let’s dig a little deeper by looking specifically at records that seem very fake and records that seem very real. This will give us a better understanding of the type of signals the model is learning.
Go ahead and sample some random records which the model has assigned a particularly high probability of being FAKE:
hol.sort_values('is_fake').tail(n=100).sample(n=5)
In these cases, it seems to be the mismatch between the education and education_num columns that gives away the fact that these are synthetic records. In the original data, these two columns have a 1:1 mapping of numerical to textual values. For example, the education value Some-college is always mapped to the numerical education_num value 10.0. In this poor-quality synthetic data, we see that there are multiple numerical values for the Some-college value, thereby giving away the fact that these records are fake.
Now let’s take a closer look at records which the model is especially certain are REAL:
hol.sort_values('is_fake').head(n=100).sample(n=5)
These “obviously real” records are types of records which the synthesizer has apparently failed to create. Thus, as they are then absent from the synthetic data, the discriminator recognizes these as REAL.
Generate high-quality synthetic data with MOSTLY AI
Now, let’s proceed to synthesize the original dataset again but this time using MOSTLY AI’s default settings for high-quality synthetic data. Run the same steps as before to synthesize the dataset except this time leave the Training Sample field blank. This will use all the records for the model training, ensuring the highest-quality synthetic data is generated.
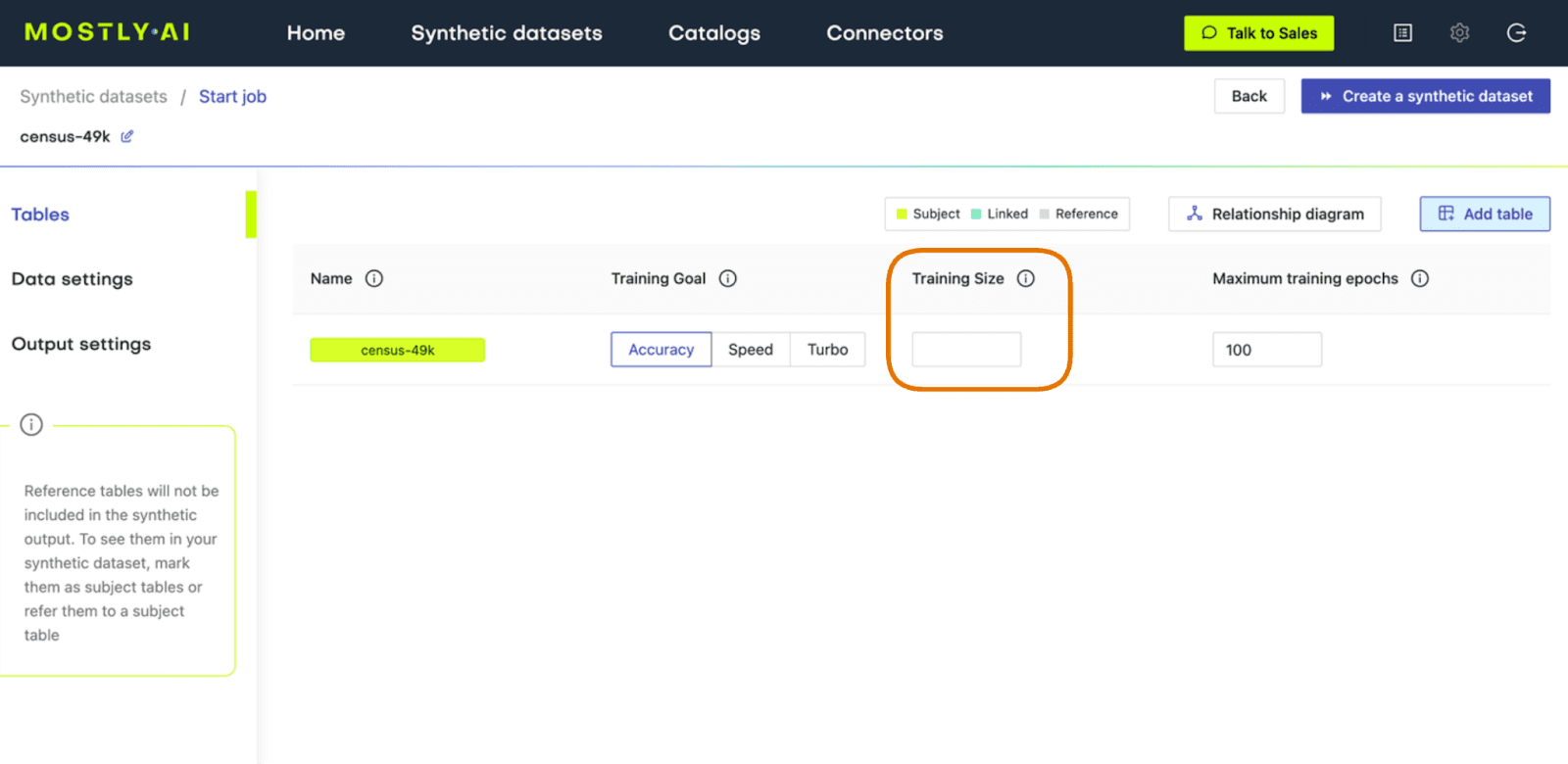
Fig 3 - Leave the Training Size blank to train on all available records.
Once the job has completed, download the high-quality data as CSV and then upload it to wherever you are running your code.
Make sure that the syn variable now contains the new, high-quality synthesized data. Then re-run the code you ran earlier to concatenate the synthetic and original data together, train a new LightGBM model on the complete dataset, and evaluate its ability to tell the REAL records from FAKE.
Again, let’s visualize the model’s performance by calculating the AUC and Accuracy scores and by plotting the probability scores:
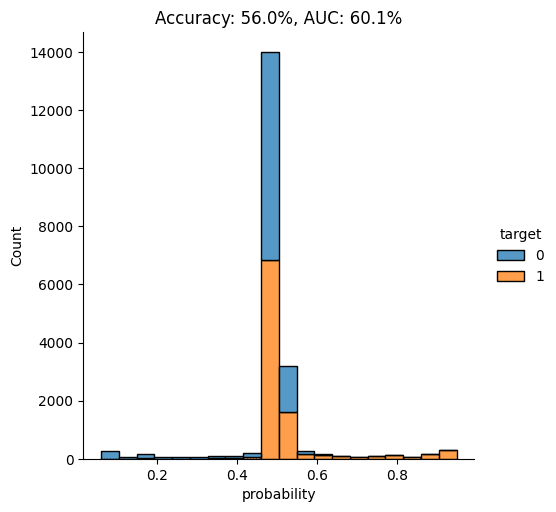
This time, we see that the model’s performance has dropped significantly. The model is not really able to pick up any meaningful signal from the combined data and assigns the largest share of records a probability around the 0.5 mark, which is essentially the equivalent of flipping a coin.
This means that the data you have generated using MOSTLY AI’s default high-quality settings is so similar to the original, real records that it is almost impossible for the model to tell them apart.
Classifying “fake vs real” records with MOSTLY AI
In this tutorial, you have learned how to build a machine learning model that can distinguish between fake (i.e. synthetic) and real data records. You have synthesized the original data using MOSTLY AI and evaluated the resulting model by looking at multiple performance metrics. By comparing the model performance on both an intentionally low-quality synthetic dataset and MOSTLY AI’s default high-quality synthetic data, you have seen firsthand that the synthetic data MOSTLY AI delivers is so statistically representative of the original data that a top-notch LightGBM model was practically unable to tell these synthetic records apart from the real ones.
If you are interested in comparing performance across various data synthesizers, you may want to check out our benchmarking article which surveys 8 different synthetic data generators.
What’s next?
In addition to walking through the above instructions, we suggest:
- measuring the Discriminator's AUC if more training samples are used,
- using a different dataset,
- using a different ML model for the discriminator, eg. a RandomForest model,
- generate synthetic data with MOSTLY using your own dataset,
- using a different synthesizer, eg. SynthCity, SDV, etc.
You can also head straight to the other synthetic data tutorials:
- Generate synthetic text data
- Explainable AI with synthetic data
- Perform conditional data generation
- Rebalancing your data for ML classification problems
- Optimize your training sample size for synthetic data accuracy
In this tutorial, you will learn how to generate synthetic text using MOSTLY AI's synthetic data generator. While synthetic data generation is most often applied to structured (tabular) data types, such as numbers and categoricals, this tutorial will show you that you can also use MOSTLY AI to generate high-quality synthetic unstructured data, such as free text.
You will learn how to use the MOSTLY AI platform to synthesize text data and also how to evaluate the quality of the synthetic text that you will generate. For context, you may want to check out the introductory article which walks through a real-world example of using synthetic text when working with voice assistant data.
You will be working with a public dataset containing AirBnB listings in London. We will walk through how to synthesize this dataset and pay special attention to the steps needed to successfully synthesize the columns containing unstructured text data. We will then proceed to evaluate the statistical quality of the generated text data by inspecting things like the set of characters, the distribution of character and term frequencies and the term co-occurrence.
We will also perform a privacy check by scanning for exact matches between the original and synthetic text datasets. Finally, we will evaluate the correlations between the synthesized text columns and the other features in the dataset to ensure that these are accurately preserved. The Python code for this tutorial is publicly available and runnable in this Google Colab notebook.
Synthesize text data
Synthesizing text data with MOSTLY AI can be done through a single step before launching your data generation job. We will indicate which columns contain unstructured text and let MOSTLY AI’s generative algorithm do the rest.
Let’s walk through how this works:
- Download the original AirBnB dataset. Depending on your operating system, use either Ctrl+S or Cmd+S to save the file locally.
- Go to your MOSTLY AI account and navigate to “Synthetic Datasets”. Upload the CSV file you downloaded in the previous step and click “Proceed”.
- Navigate to “Data Settings” in order to specify which columns should be synthesized as unstructured text data.
- Click on the host_name and title columns and set the Generation Method to “Text”.
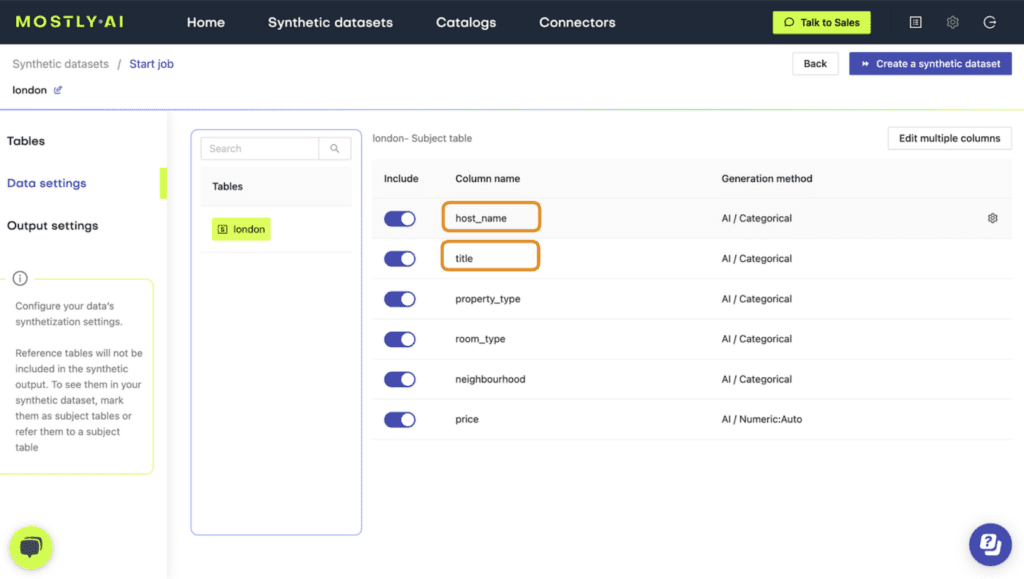
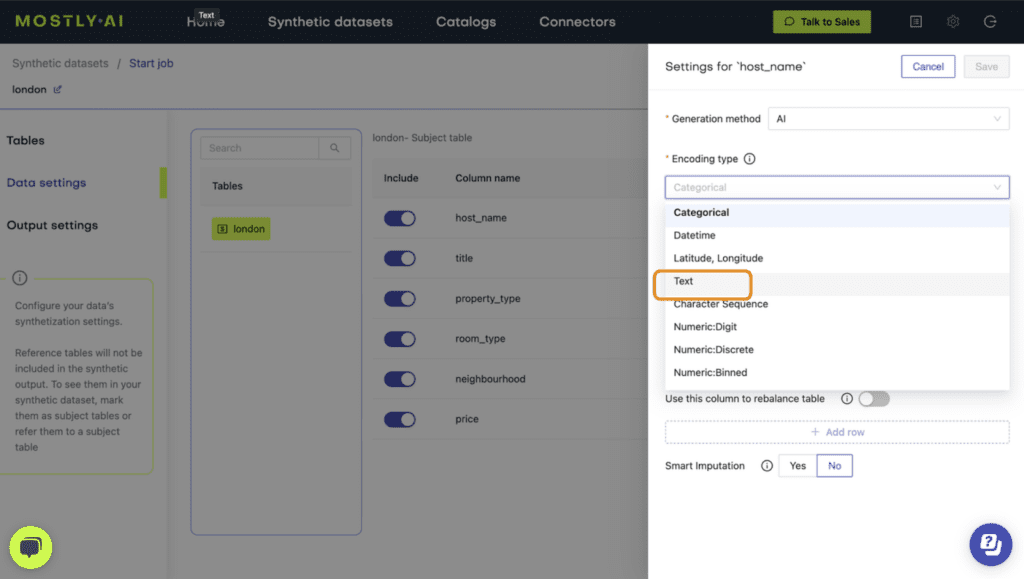
- Verify that both columns are set to Generation Method “AI / Text” and then launch the job by clicking “Create a synthetic dataset”. Synthetic text generation is compute-intensive, so this may take up to an hour to complete.
- Once completed, download the synthetic dataset as CSV.
And that’s it! You have successfully synthesized unstructured text data using MOSTLY AI.
You can now poke around the synthetic data you’ve created, for example, by sampling 5 random records:
syn.sample(n=5)
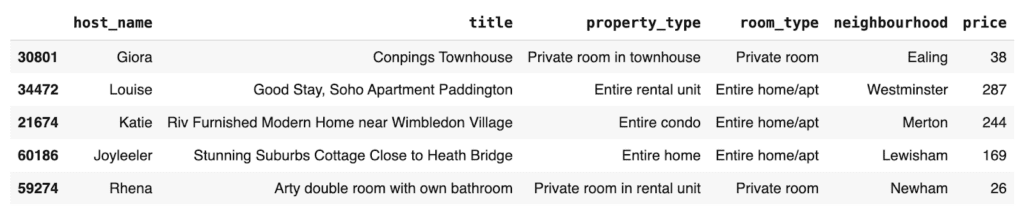
And compare this to 5 random records sampled from the original dataset:

But of course, you shouldn’t just take our word for the fact that this is high-quality synthetic data. Let’s be a little more critical and evaluate the data quality in more detail in the next section.
Evaluate statistical integrity
Let’s take a closer look at how statistically representative the synthetic text data is compared to the original text. Specifically, we’ll investigate four different aspects of the synthetic data: (1) the character set, (2) the character and (3) term frequency distributions, and (4) the term co-occurrence. We’ll explain the technical terms in each section.
Character set
Let’s start by taking a look at the set of all characters that occur in both the original and synthetic text. We would expect to see a strong overlap between the two sets, indicating that the same kinds of characters that appear in the original dataset also appear in the synthetic version.
The code below generates the set of characters for the original and synthetic versions of the title column:
print(
"## ORIGINAL ##\n",
"".join(sorted(list(set(tgt["title"].str.cat(sep=" "))))),
"\n",
)
print(
"## SYNTHETIC ##\n",
"".join(sorted(list(set(syn["title"].str.cat(sep=" "))))),
"\n",
)
The output is quite long and is best inspected by running the code in the notebook yourself.
We see a perfect overlap in the character set for all characters up until the “£” symbol. These are all the most commonly used characters. This is a good first sign that the synthetic data contains the right kinds of characters.
From the “£” symbol onwards, you will note that the character set of the synthetic data is shorter. This is expected and is due to the privacy mechanism called rare category protection within the MOSTLY AI platform, which removes very rare tokens in order to prevent their presence giving away information on the existence of individual records in the original dataset.
Character frequency distribution
Next, let’s take a look at the character frequency distribution: how many times each letter shows up in the dataset. Again, we will compare this statistical property between the original and synthetic text data in the title column.
The code below creates a list of all characters that occur in the datasets along with the percentage that character constitutes of the whole dataset:
title_char_freq = (
pd.merge(
tgt["title"]
.str.split("")
.explode()
.value_counts(normalize=True)
.to_frame("tgt")
.reset_index(),
syn["title"]
.str.split("")
.explode()
.value_counts(normalize=True)
.to_frame("syn")
.reset_index(),
on="index",
how="outer",
)
.rename(columns={"index": "char"})
.round(5)
)
title_char_freq.head(10)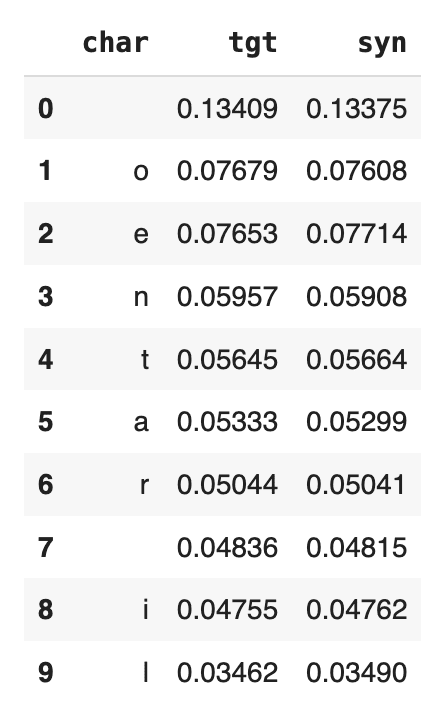
We see that “o” and “e” are the 2 most common characters (after the whitespace character), both showing up a little more than 7.6% of the time in the original dataset. If we inspect the syn column, we see that the percentages match up nicely. There are about as many “o”s and “e”s in the synthetic dataset as there are in the original now. And this goes for the other characters in the list as well.
For a visualization of all the distributions of the 100 most common characters, you can run the code below:
import matplotlib.pyplot as plt
ax = title_char_freq.head(100).plot.line()
plt.title('Distribution of Char Frequencies')
plt.show()
We see that the original distribution (in light blue) and the synthetic distribution (orange) are almost identical. This is another important confirmation that the statistical properties of the original text data are being preserved during the synthetic text generation.
Term frequency distribution
Let’s now do the same exercise we did above but with words (or “terms”) instead of characters. We will look at the term frequency distribution: how many times each term shows up in the dataset and how this compares across the synthetic and original datasets.
The code below performs some data cleaning and then performs the analysis and displays the 10 most frequently used terms.
import re
def sanitize(s):
s = str(s).lower()
s = re.sub('[\\,\\.\\)\\(\\!\\"\\:\\/]', " ", s)
s = re.sub("[ ]+", " ", s)
return s
tgt["terms"] = tgt["title"].apply(lambda x: sanitize(x)).str.split(" ")
syn["terms"] = syn["title"].apply(lambda x: sanitize(x)).str.split(" ")
title_term_freq = (
pd.merge(
tgt["terms"]
.explode()
.value_counts(normalize=True)
.to_frame("tgt")
.reset_index(),
syn["terms"]
.explode()
.value_counts(normalize=True)
.to_frame("syn")
.reset_index(),
on="index",
how="outer",
)
.rename(columns={"index": "term"})
.round(5)
)
display(title_term_freq.head(10))
You can also take a look at the 10 least-common words:
display(title_term_freq.head(200).tail(10))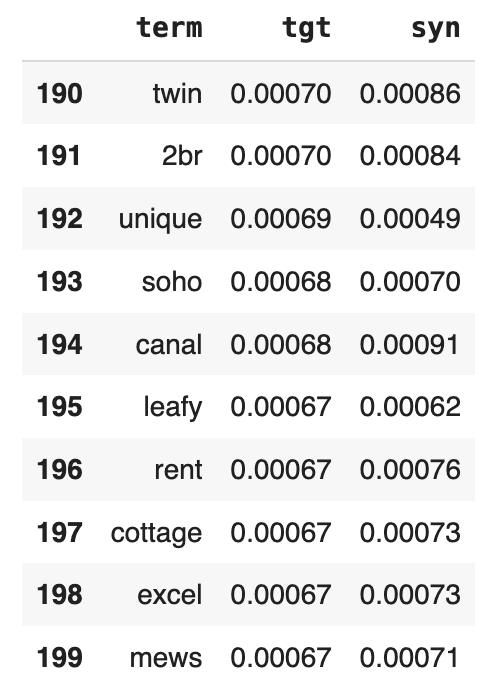
And again, plot the entire distribution for a comprehensive overview:
ax = title_term_freq.head(100).plot.line()
plt.title('Distribution of Term Frequencies')
plt.show()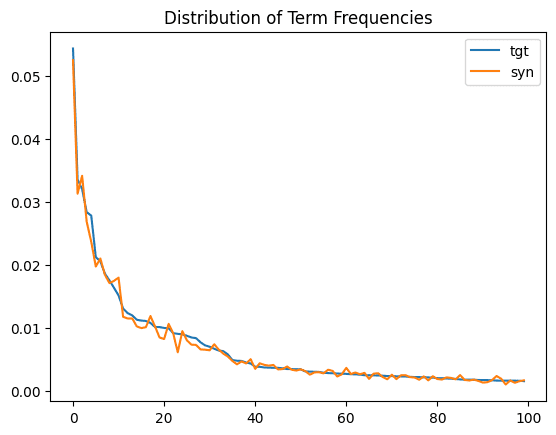
Just as we saw above with the character frequency distribution, we see a close match between the original and synthetic term frequency distributions. The statistical properties of the original dataset are being preserved.
Term co-occurrence
As a final statistical test, let’s take a look at the term co-occurrence: how often a word appears in a given listing title given the presence of another word. For example, how many words that contain the word “heart” also contain the word “London”?
The code below defines a helper function to calculate the term co-occurrence given two words:
def calc_conditional_probability(term1, term2):
tgt_beds = tgt["title"][
tgt["title"].str.lower().str.contains(term1).fillna(False)
]
syn_beds = syn["title"][
syn["title"].str.lower().str.contains(term1).fillna(False)
]
tgt_beds_double = tgt_beds.str.lower().str.contains(term2).mean()
syn_beds_double = syn_beds.str.lower().str.contains(term2).mean()
print(
f"{tgt_beds_double:.0%} of actual Listings, that contain `{term1}`, also contain `{term2}`"
)
print(
f"{syn_beds_double:.0%} of synthetic Listings, that contain `{term1}`, also contain `{term2}`"
)
print("")Let’s run this function for a few different examples of word combinations:
calc_conditional_probability('bed', 'double')
calc_conditional_probability('bed', 'king')
calc_conditional_probability('heart', 'london')
calc_conditional_probability('london', 'heart')14% of actual Listings, that contain `bed`, also contain `double`
13% of synthetic Listings, that contain `bed`, also contain `double`
7% of actual Listings, that contain `bed`, also contain `king`
6% of synthetic Listings, that contain `bed`, also contain `king`
28% of actual Listings, that contain `heart`, also contain `london`
26% of synthetic Listings, that contain `heart`, also contain `london`
4% of actual Listings, that contain `london`, also contain `heart`
4% of synthetic Listings, that contain `london`, also contain `heart`
Once again, we see that the term co-occurrences are being accurately preserved (with some minor variation) during the process of generating the synthetic text.
Now you might be asking yourself: if all of these characteristics are maintained, what are the chances that we'll end up with exact matches, i.e., synthetic records with the exact same title value as a record in the original dataset? Or perhaps even a synthetic record with the exact same values for all the columns?
Let's start by trying to find an exact match for 1 specific synthetic title value. Choose a title_value from the original title column and then use the code below to search for an exact match in the synthetic title column.
title_value = "Airy large double room"
tgt.loc[tgt["title"].str.contains(title_value, case=False, na=False)]
We see that there is an exact (partial) match in this case. Depending on the value you choose, you may or may not find an exact match. But how big of a problem is it that we find an exact partial match? Is this a sign of a potential privacy breach? It’s hard to tell from a single row-by-row validation, and, more importantly, this process doesn't scale very well to the 71K rows in the dataset.
Evaluate the privacy of synthetic text
Let's perform a more comprehensive check for privacy by looking for exact matches between the synthetic and the original.
To do that, first split the original data into two equally-sized sets and measure the number of matches between those two sets:
n = int(tgt.shape[0]/2)
pd.merge(tgt[['title']][:n].drop_duplicates(), tgt[['title']][n:].drop_duplicates())
This is interesting. There are 323 cases of duplicate title values in the original dataset itself. This means that the appearance of one of these duplicate title values in the synthetic dataset would not point to a single record in the original dataset and therefore does not constitute a privacy concern.
What is important to find out here is whether the number of exact matches between the synthetic dataset and the original dataset exceeds the number of exact matches within the original dataset itself.
Let’s find out.
Take an equally-sized subset of the synthetic data, and again measure the number of matches between that set and the original data:
pd.merge(
tgt[["title"]][:n].drop_duplicates(), syn[["title"]][:n].drop_duplicates()
)
There are 236 exact matches between the synthetic dataset and the original, but significantly less than the number of exact matches that exist within the original dataset itself. Moreover, we can see that they occur only for the most commonly used descriptions.
It’s important to note that matching values or matching complete records are by themselves not a sign of a privacy leak. They are only an issue if they occur more frequently than we would expect based on the original dataset. Also note that removing those exact matches via post-processing would actually have a detrimental contrary effect. The absence of a value like "Lovely single room" in a sufficiently large synthetic text corpus would, in this case, actually give away the fact that this sentence was present in the original. See our peer-reviewed academic paper for more context on this topic.
Correlations between text and other columns
So far, we have inspected the statistical quality and privacy preservation of the synthesized text column itself. We have seen that both the statistical properties and the privacy of the original dataset are carefully maintained.
But what about the correlations that exist between the text columns and other columns in the dataset? Are these correlations also maintained during synthesization?
Let’s take a look by inspecting the relationship between the title and price columns. Specifically, we will look at the median price of listings that contain specific words that we would expect to be associated with a higher (e.g., “luxury”) or lower (e.g., “small”) price. We will do this for both the original and synthetic datasets and compare.
The code below prepares the data and defines a helper function to print the results:
tgt_term_price = (
tgt[["terms", "price"]]
.explode(column="terms")
.groupby("terms")["price"]
.median()
)
syn_term_price = (
syn[["terms", "price"]]
.explode(column="terms")
.groupby("terms")["price"]
.median()
)
def print_term_price(term):
print(
f"Median Price of actual Listings, that contain `{term}`: ${tgt_term_price[term]:.0f}"
)
print(
f"Median Price of synthetic Listings, that contain `{term}`: ${syn_term_price[term]:.0f}"
)
print("")Let’s then compare the median price for specific terms across the two datasets:
print_term_price("luxury")
print_term_price("stylish")
print_term_price("cozy")
print_term_price("small")Median Price of actual Listings, that contain `luxury`: $180
Median Price of synthetic Listings, that contain `luxury`: $179
Median Price of actual Listings, that contain `stylish`: $134
Median Price of synthetic Listings, that contain `stylish`: $140
Median Price of actual Listings, that contain `cozy`: $70
Median Price of synthetic Listings, that contain `cozy`: $70
Median Price of actual Listings, that contain `small`: $55
Median Price of synthetic Listings, that contain `small`: $60
We can see that correlations between the text and price features are very well retained.
Generate synthetic text with MOSTLY AI
In this tutorial, you have learned how to generate synthetic text using MOSTLY AI by simply specifying the correct Generation Method for the columns in your dataset that contain unstructured text. You have also taken a deep dive into evaluating the statistical integrity and privacy preservation of the generated synthetic text by looking at character and term frequencies, term co-occurrence, and the correlations between the text column and other features in the dataset. These statistical and privacy indicators are crucial components for creating high-quality synthetic data.
What’s next?
In addition to walking through the above instructions, we suggest experimenting with the following in order to get even more hands-on experience generating synthetic text data:
- analyzing further correlations, also for host_name
- using a different generation mood, e.g., conservative sampling. Take a look at the end of the video tutorial for a quick walkthrough.
- using a different dataset, e.g., the Austrian First Name dataset
You can also head straight to the other synthetic data tutorials:
- Evaluate synthetic data quality using downstream ML
- Optimize your training sample size for synthetic data accuracy
- Rebalancing your data for ML classification problems
- Perform conditional data generation
- Explainable AI with synthetic data
- How to generate synthetic data
The European Union’s Artificial Intelligence Act (“AI Act”) is likely to have a profound impact on the development and utilization of artificial intelligence systems. Anonymization, particularly in the form of synthetic data, will play a pivotal role in establishing AI compliance and addressing the myriad challenges posed by the widespread use of AI systems.
This blog post offers an introductory overview of the primary features and objectives of the draft EU AI Act. It also elaborates on the indispensable role of synthetic data in ensuring AI compliance with data management obligations, especially for high-risk AI systems.
Notably, we focus on the European Parliament’s report on the proposal for a regulation of the European Parliament and the Council, which lays down harmonized rules on Artificial Intelligence (the Artificial Intelligence Act) and amends certain Union Legislative Acts (COM(2021)0206 – C9-0146/2021 – 2021/0106(COD)). It's important to note that this isn't the final text of the AI Act.
The first comprehensive regulation for AI compliance
The draft AI Act is a hotly debated legal initiative that will apply to providers and deployers of AI systems, among others. Remarkably, it is set to become the world's first comprehensive mandatory legal framework for AI. This will directly impact researchers, developers, businesses, and citizens involved in or affected by AI. AI compliance is a brand new domain that will transform the way companies manage their data.
The choice: AI compliance or costly consequences
Much like the GDPR, failure to comply with the AI Act's obligations can have substantial financial repercussions: maximum fines for non-compliance under the draft AI Act can be nearly double those under the GDPR. Depending on the severity and duration of the violation, penalties can range from warnings to fines of up to 7% of the offender's annual worldwide turnover.
Additionally, national authorities can order the withdrawal or recall of non-compliant AI systems from the market or impose temporary or permanent bans on their use. AI compliance is set to become a serious financial issue for companies doing business in the EU.
Risk-based classification
The draft EU AI Act operates on the principle that the level of regulation should align with the level of risk posed by an AI system. It categorizes AI systems into four risk categories:
- Unacceptable risk: This pertains to AI applications that are prohibited due to violations of human dignity, democracy, or fundamental rights, such as social scoring systems or real-time biometric identification in public spaces. AI systems in this category are entirely banned.
- High risk: High-risk AI applications are subject to stringent obligations before they can be placed on the market or put into service. This includes AI used in critical infrastructure, education, employment, health, justice, or law enforcement.
- Limited risk: AI applications in this category, such as chatbots, must adhere to transparency requirements.
- Minimal risk: AI applications with minimal risk face no specific obligations, such as AI used for entertainment or personal purposes.
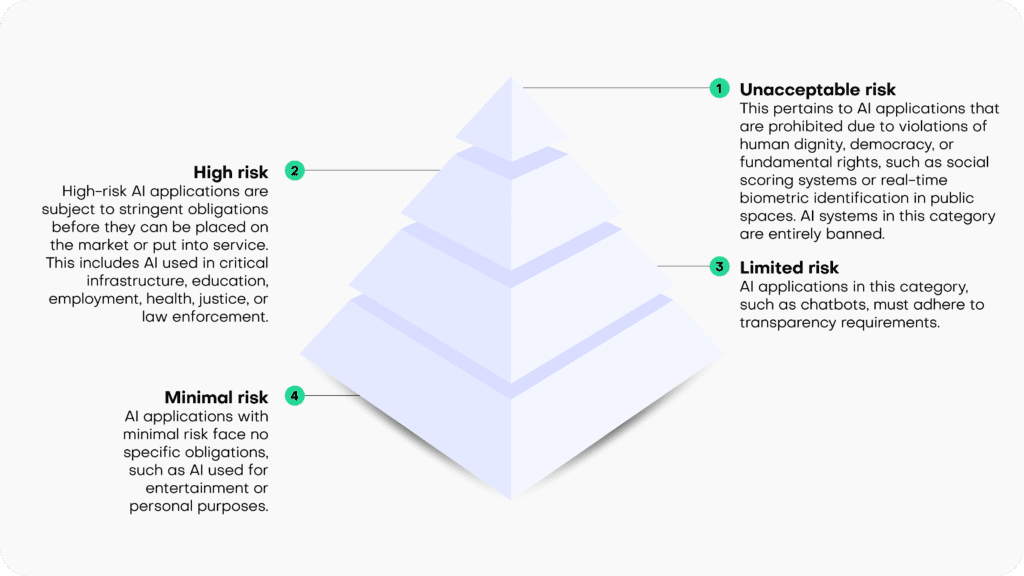
Synthetic solutions for AI compliance
The draft AI Act focuses its regulatory efforts on high-risk AI systems, imposing numerous obligations on them. These obligations encompass ensuring the robustness, security, and accuracy of AI systems. It also mandates the ability to correct or deactivate the system in case of errors or risks, as well as implementing human oversight and intervention mechanisms to prevent or mitigate harm or adverse impacts, as well as a number of additional requirements.
Specifically, under the heading “Data and data governance”, Art. 10 sets out strict quality criteria for training, validation and testing data sets (“data sets”) used as a basis for the development of “[h]igh-risk AI systems which make use of techniques involving the training of models with data” (which likely encompasses most high-risk AI systems).
According to Art 10(2), the respective data sets shall be subject to appropriate data governance and management practices. This includes, among other things, an examination of possible biases that are likely to affect the health and safety of persons, negatively impact fundamental rights, or lead to discrimination (especially with regard to feedback loops), and requires the application of appropriate measures to detect, prevent, and mitigate possible biases. Not surprisingly, AI compliance will start with the underlying data.
Pursuant to Art 10 (3), data sets shall be “relevant, sufficiently representative, appropriately vetted for errors and as complete as possible in view of the intended purpose” and shall “have the appropriate statistical properties […]“.
Art 10(5) specifically stands out in the data governance context, as it contains a legal basis for the processing of sensitive data, as protected, among other provisions, by Art 9(1) GDPR: Art 10(5) entitles high-risk AI system providers, to the extent that is strictly necessary for the purposes of ensuring negative bias detection and correction, to exceptionally process sensitive personal data. However, such data processing must be subject to “appropriate safeguards for the fundamental rights and freedoms of natural persons, including technical limitations on the re-use and use of state-of-the-art security and privacy-preserving [measures]“.
Art 10(5)(a-g) sets out specific conditions which are prerequisites for the processing of sensitive data in this context. The very first condition, as stipulated in Art 10(5)(a) sets the scene: the data processing under Art 10 is only allowed if its goal, namely bias detection and correction “cannot be effectively fulfilled by processing synthetic or anonymised data”. Conversely, if an AI system provider is able detect and correct bias by using synthetic or anonymized data, it is required to do so and cannot rely on other “appropriate safeguards”.
The distinction between synthetic and anonymized data in the parliamentary draft of the AI Act is somewhat confusing, since considering the provision’s purpose, arguably only anonymized synthetic data qualifies as preferred method for tackling data bias. However, since anonymized synthetic data is a sub-category of anonymized data, the differentiation between those two terms is meaningless, unless the EU legislator attempts to highlight synthetic data as the preferred version of anonymized data (in which case the text of the provision should arguably read “synthetic or other forms of anonymized data”).
Irrespective of such details, it is clear that the EU legislator clearly requires the use of anonymized data for the processing of sensitive data as a primary bias detection and correction tool. It looks like AI compliance cannot be achieved without effective and AI-friendly data anonymization tools.
Recital 45(a) supports this (and extends the synthetic data use case to privacy protection and also addresses AI-system users, instead of only AI system providers):
“The right to privacy and to protection of personal data must be guaranteed throughout the entire lifecycle of the AI system. In this regard, the principles of data minimization and data protection by design and by default, as set out in Union data protection law, are essential when the processing of data involves significant risks to the fundamental rights of individuals.
Providers and users of AI systems should implement state-of-the-art technical and organizational measures in order to protect those rights. Such measures should include not only anonymization and encryption, but also the use of increasingly available technology that permits algorithms to be brought to the data and allows valuable insights to be derived without the transmission between parties or unnecessary copying of the raw or structured data themselves.”
The inclusion of synthetic data in the draft AI Act is a continuation of the ever-growing political awareness of the technology’s potential. This is underlined by a recent statement made by the EU Commission’s Joint Research Committee: “[Synthetic data] not only can be shared freely, but also can help rebalance under-represented classes in research studies via oversampling, making it the perfect input into machine learning and AI models."
Synthetic data is set to become one of the cornerstones of AI compliance in the very near future.
In this tutorial, you will learn how to use synthetic data to explore and validate a machine-learning model that was trained on real data. Synthetic data is not restricted by any privacy concerns and therefore enables you to engage a far broader group of stakeholders and communities in the model explanation and validation process. This enhances transparent algorithmic auditing and helps to ensure the safety of developed ML-powered systems through the practice of Explainable AI (XAI).
We will start by training a machine learning model on a real dataset. We will then evaluate and inspect this model using a synthesized (and therefore privacy-preserving) version of the dataset. This is also referred to as the Train-Real-Test-Synthetic methodology. We will then inspect the ML model using the synthetic data to better understand how the model makes its predictions. The Python code for this tutorial is publicly available and runnable in this Google Colab notebook.
Train model on real data
The first step will be to train a LightGBM model on a real dataset. You’ll be working with a subset of the UCI Adult Income dataset, consisting of 10,000 records and 10 attributes. The target feature is the income column which is a Boolean feature indicating whether the record is high-income (>50K) or not. Your machine learning model will use the 9 remaining predictor features to predict this target feature.
# load original (real) data
import numpy as np
import pandas as pd
df = pd.read_csv(f'{repo}/census.csv')
df.head(5)And then use the following code block to define the target feature, preprocess the data and train the LightGBM model:
import lightgbm as lgb
from lightgbm import early_stopping
from sklearn.model_selection import train_test_split
target_col = 'income'
target_val = '>50K'
def prepare_xy(df):
y = (df[target_col]==target_val).astype(int)
str_cols = [
col for col in df.select_dtypes(['object', 'string']).columns if col != target_col
]
for col in str_cols:
df[col] = pd.Categorical(df[col])
cat_cols = [
col for col in df.select_dtypes('category').columns if col != target_col
]
num_cols = [
col for col in df.select_dtypes('number').columns if col != target_col
]
for col in num_cols:
df[col] = df[col].astype('float')
X = df[cat_cols + num_cols]
return X, y
def train_model(X, y):
cat_cols = list(X.select_dtypes('category').columns)
X_trn, X_val, y_trn, y_val = train_test_split(
X, y, test_size=0.2, random_state=1
)
ds_trn = lgb.Dataset(
X_trn,
label=y_trn,
categorical_feature=cat_cols,
free_raw_data=False
)
ds_val = lgb.Dataset(
X_val,
label=y_val,
categorical_feature=cat_cols,
free_raw_data=False
)
model = lgb.train(
params={
'verbose': -1,
'metric': 'auc',
'objective': 'binary'
},
train_set=ds_trn,
valid_sets=[ds_val],
callbacks=[early_stopping(5)],
)
return modelRun the code lines below to preprocess the data, train the model and calculate the AUC performance metric score:
X, y = prepare_xy(df)
model = train_model(X, y)Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is: [63] valid_0's auc: 0.917156
The model has an AUC score of 91.7%, indicating excellent predictive performance. Take note of this in order to compare it to the performance of the model on the synthetic data later on.
Explainable AI: privacy concerns and regulations
Now that you have your well-performing machine learning model, chances are you will want to share the results with a broader group of stakeholders. As concerns and regulations about privacy and the inner workings of so-called “black box” ML models increase, it may even be necessary to subject your final model to a thorough auditing process. In such cases, you generally want to avoid using the original dataset to validate or explain the model, as this would risk leaking private information about the records included in the dataset.
So instead, in the next steps you will learn how to use a synthetic version of the original dataset to audit and explain the model. This will guarantee the maximum amount of privacy preservation possible. Note that it is crucial for your synthetic dataset to be accurate and statistically representative of the original dataset. We want to maintain the statistical characteristics of the original data but remove the privacy risks. MOSTLY AI provides some of the most accurate and secure data synthesization in the industry.
Synthesize dataset using MOSTLY AI
Follow the steps below to download the original dataset and synthesize it via MOSTLY A’s synthetic data generator:
- Download
census.csvby clicking here, and then save the file to disk by pressing Ctrl+S or Cmd+S, depending on your operating system.
- Navigate to your MOSTLY AI account, click on the “Synthetic Datasets” tab, and upload
census.csvhere.
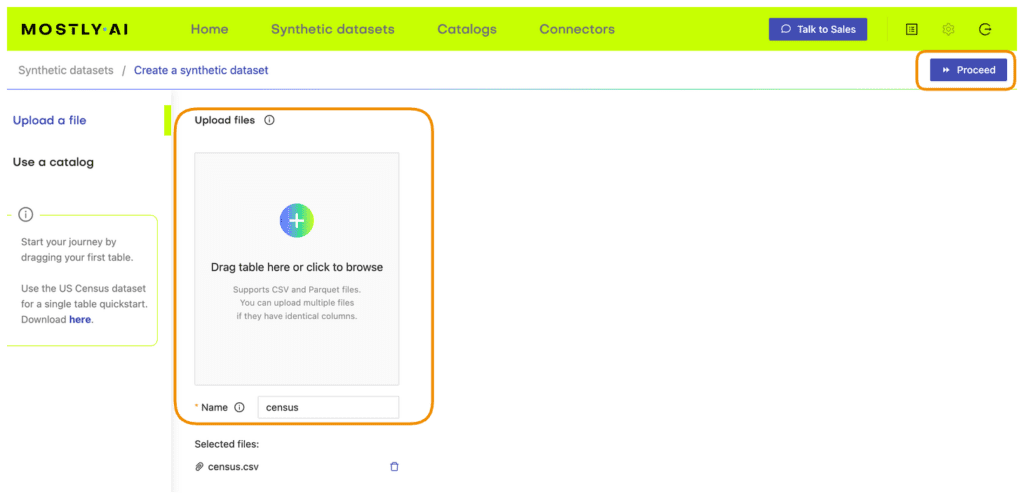
- Synthesize
census.csv, leaving all the default settings.
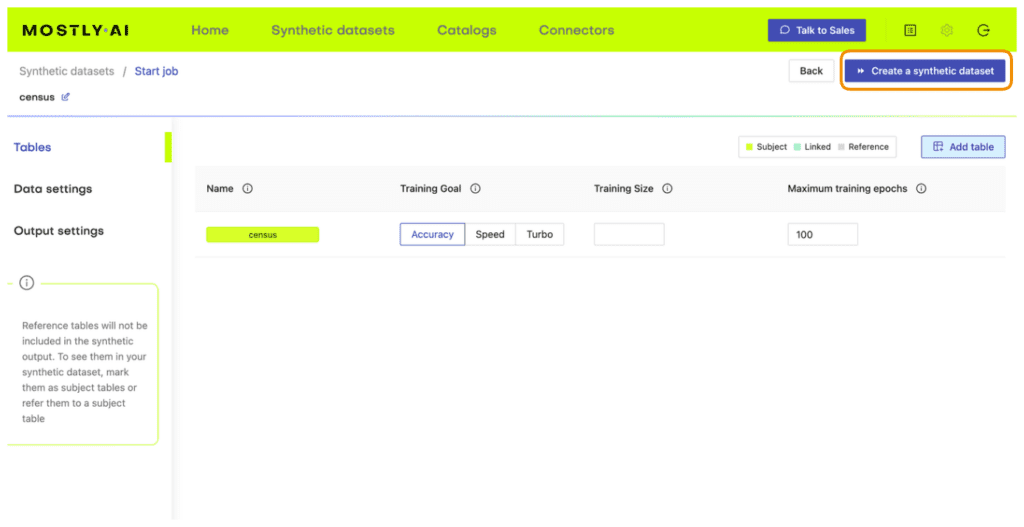
- Once the job has finished, download the generated synthetic data as a CSV file to your computer.
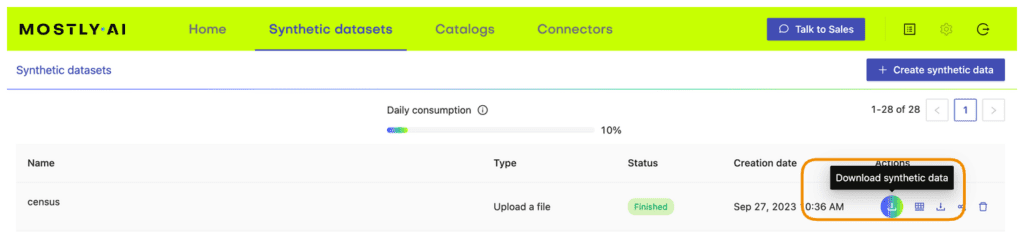
- Access the generated synthetic data from wherever you are running your code. If you are running in Google Colab, you will need to upload it by executing the next cell.
# upload synthetic dataset
if is_colab:
import io
uploaded = files.upload()
syn = pd.read_csv(io.BytesIO(list(uploaded.values())[0]))
print(f"uploaded synthetic data with {syn.shape[0]:,} records and {syn.shape[1]:,} attributes")
else:
syn_file_path = './census-synthetic.csv'
syn = pd.read_csv(syn_file_path)
print(f"read synthetic data with {syn.shape[0]:,} records and {syn.shape[1]:,} attributes")You can now poke around and explore the synthetic dataset, for example by sampling 5 random records. You can run the line below multiple times to see different samples.
syn.sample(5)
The records in the syn dataset are synthesized, which means they are entirely fictional (and do not contain private information) but do follow the statistical distributions of the original dataset.
Evaluate ML performance using synthetic data
Now that you have your synthesized version of the UCI Adult Income dataset, you can use it to evaluate the performance of the LightGBM model you trained above on the real dataset.
The code block below preprocesses the data calculates performance metrics for the LightGBM model using the synthetic dataset, and visualizes the predictions on a bar plot:
from sklearn.metrics import roc_auc_score, accuracy_score
import seaborn as sns
import matplotlib.pyplot as plt
X_syn, y_syn = prepare_xy(syn)
p_syn = model.predict(X_syn)
auc = roc_auc_score(y_syn, p_syn)
acc = accuracy_score(y_syn, (p_syn >= 0.5).astype(int))
probs_df = pd.concat([
pd.Series(p_syn, name='probability').reset_index(drop=True),
pd.Series(y_syn, name=target_col).reset_index(drop=True),
], axis=1)
fig = sns.displot(data=probs_df, x='probability', hue=target_col, bins=20, multiple="stack")
fig = plt.title(f"Accuracy: {acc:.1%}, AUC: {auc:.1%}", fontsize=20)
plt.show()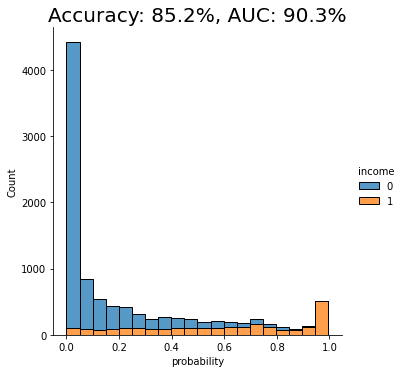
We see that the AUC score of the model on the synthetic dataset comes close to that of the original dataset, both around 91%. This is a good indication that our synthetic data is accurately modeling the statistical characteristics of the original dataset.
Explain ML Model using Synthetic Data
We will be using the SHAP library to perform our model explanation and validation: a state-of-the-art Python library for explainable AI. If you want to learn more about the library or explainable AI fundamentals in general, we recommend checking out the SHAP documentation and/or the Interpretable ML Book.
The important thing to note here is that from this point onwards, we no longer need access to the original data. Our machine-learning model has been trained on the original dataset but we will be explaining and inspecting it using the synthesized version of the dataset. This means that the auditing and explanation process can be shared with a wide range of stakeholders and communities without concerns about revealing privacy-sensitive information. This is the real value of using synthetic data in your explainable AI practice.
SHAP feature importance
Feature importances are a great first step in better understanding how a machine learning model arrives at its predictions. The resulting bar plots will indicate how much each feature in the dataset contributes to the model’s final prediction.
To start, you will need to import the SHAP library and calculate the so-called shap values. These values will be needed in all of the following model explanation steps.
# import library
import shap
# instantiate explainer and calculate shap values
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_syn)You can then plot the feature importances for our trained model:
shap.initjs()
shap.summary_plot(shap_values, X_syn, plot_size=0.2)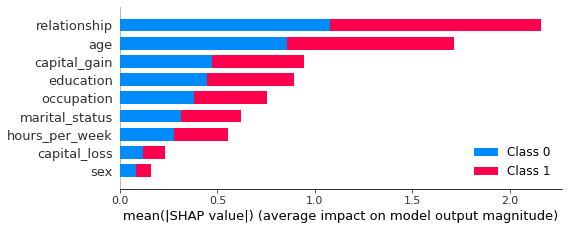
In this plot, we see clearly that both the relationship and age features contribute strongly to the model’s prediction. Perhaps surprisingly, the sex feature contributes the least strongly. This may be counterintuitive and, therefore, valuable information. Without this plot, stakeholders may draw their own (possibly incorrect) conclusions about the relative importance of the sex feature in predicting the income of respondents in the dataset.
SHAP dependency plots
To get even closer to explainable AI and to get an even more fine-grained understanding of how your machine learning model is making its predictions, let’s proceed to create dependency plots. Dependency plots tell us more about the effect that a single feature has on the ML model’s predictions.
A plot is generated for each feature, with all possible values of that feature on the x-axis and the corresponding shap value on the y-axis. The shap value is an indication of how much knowing the value of that particular feature affects the outcome of the model. For a more in-depth explanation of how shap values work, check out the SHAP documentation.
The code block below plots the dependency plots for all the predictor features in the dataset:
def plot_shap_dependency(col):
col_idx = [
i for i in range(X_syn.shape[1]) if X_syn.columns[i]==col][0]
shp_vals = (
pd.Series(shap_values[1][:,col_idx], name='shap_value'))
col_vals = (
X_syn.iloc[:,col_idx].reset_index(drop=True))
df = pd.concat([shp_vals, col_vals], axis=1)
if col_vals.dtype.name != 'category':
q01 = df[col].quantile(0.01)
q99 = df[col].quantile(0.99)
df = df.loc[(df[col] >= q01) & (df[col] <= q99), :]
else:
sorted_cats = list(
df.groupby(col)['shap_value'].mean().sort_values().index)
df[col] = df[col].cat.reorder_categories(sorted_cats, ordered=True)
fig, ax = plt.subplots(figsize=(8, 4))
plt.ylim(-3.2, 3.2)
plt.title(col)
plt.xlabel('')
if col_vals.dtype.name == 'category':
plt.xticks(rotation = 90)
ax.tick_params(axis='both', which='major', labelsize=8)
ax.tick_params(axis='both', which='minor', labelsize=6)
p1 = sns.lineplot(x=df[col], y=df['shap_value'], color='black').axhline(0, color='gray', alpha=1, lw=0.5)
p2 = sns.scatterplot(x=df[col], y=df['shap_value'], alpha=0.1)
def plot_shap_dependencies():
top_features = list(reversed(X_syn.columns[np.argsort(np.mean(np.abs(shap_values[1]), axis=0))]))
for col in top_features:
plot_shap_dependency(col)
plot_shap_dependencies()Let’s take a closer look at the dependency plot for the relationship feature:
The relationship column is a categorical feature and we see all 6 possible values along the x-axis. The dependency plot shows clearly that records containing “husband” or “wife” as the relationship value are far more likely to be classified as high-income (positive shap value). The black line connects the average shap values for each relationship type, and the blue gradient is actually the shap value of each of the 10K data points in the dataset. This way, we also get a sense of the variation in the lift.
This becomes even more clear when we look at a feature with more discrete values, such as the age column.
This dependency plot shows us that the likelihood of a record being high-income increases together with age. As the value of age decreases from 28 to 18, we see (on average) an increasingly lower chance of being high-income. From around 29 and above, we see an increasingly higher chance of being high-income, which stables out around 50. Notice the wide range of values once the value of age exceeds 60, indicating a large variance.
Go ahead and inspect the dependency plots for the other features on your own. What do you notice?
SHAP values for synthetic samples
The two model explanation methods you have just worked through aggregate their results over all the records in the dataset. But what if you are interested in digging even deeper down to uncover how the model arrives at specific individual predictions? This level of reasoning and inspection at the level of individual records would not be possible with the original real data, as this contains privacy-sensitive information and cannot be safely shared. Synthetic data ensures privacy protection and enables you to share model explanations and inspections at any scale. Explainable AI needs to be shareable and transparent - synthetic data is the key to this transparency.
Let’s start by looking at a random prediction:
# define function to inspect random prediction
def show_idx(i):
shap.initjs()
df = X_syn.iloc[i:i+1, :]
df.insert(0, 'actual', y_syn.iloc[i])
df.insert(1, 'score', p_syn[i])
display(df)
return shap.force_plot(explainer.expected_value[1], shap_values[1][i,:], X_syn.iloc[i,:], link="logit")
# inspect random prediction
rnd_idx = X_syn.sample().index[0]
show_idx(rnd_idx)
The output shows us a random record with an actual score of 0, meaning this is a low-income (<50K) record. The model scores all predictions with a value between 0 and 1, where 0 is a perfect low-income prediction and 1 is a perfect high-income prediction. For this sample, the model has given a prediction score of 0.17, which is quite close to the actual score. In the red-and-blue bars below the data table, we can see how different features contributed to this prediction. We can see that the values of the relationship and marital status pushed this sample towards a lower prediction score, whereas the education, occupation, capital_loss, and age features pushed for a slightly higher prediction score.
You can repeat this single-sample inspection method for specific types of samples, such as the sample with the lowest/highest prediction score:
idx = np.argsort(p_syn)[0]
show_idx(idx)
Or a sample with particular characteristics of interest, such as a young female doctorate under the age of 30:
idx = syn[
(syn.education=='Doctorate')
& (syn.sex=='Female')
& (syn.age<=30)].sample().index[0]
show_idx(idx)
You can also zoom back out again to explore the shap values across a larger number of samples. For example, you can aggregate the shap values of 1,000 samples using the code below:
shap.initjs()
shap.force_plot(explainer.expected_value[1], shap_values[1][:1000,:], X.iloc[:1000,:], link="logit")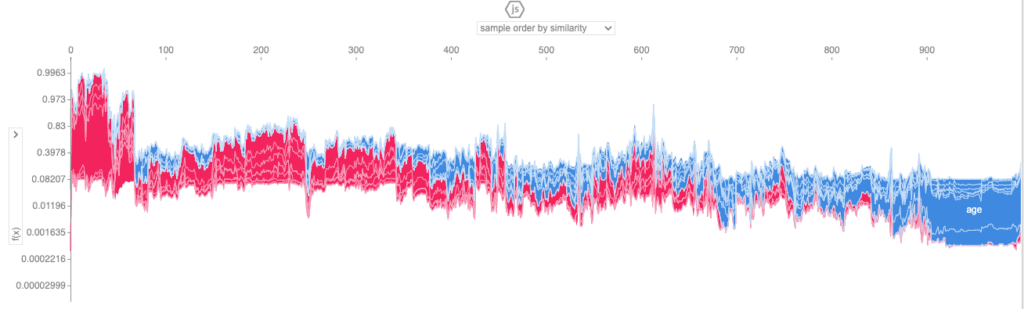
This view enables you to look through a larger number of samples and inspect the relative contributions of the predictor features to each individual sample.
Explainable AI with MOSTLY AI
In this tutorial, you have seen how machine learning models that have been trained on real data can be safely tested and explained with synthetic data. You have learned how to synthesize an original dataset using MOSTLY AI and how to use this synthetic dataset to inspect and explain the predictions of a machine learning model trained on the real data. Using the SHAP library, you have gained a better understanding of how the model arrives at its predictions and have even been able to inspect how this works for individual records, something that would not be safe to do with the privacy-sensitive original dataset.
Synthetic data ensures privacy protection and therefore enables you to share machine learning auditing and explanation processes with a significantly larger group of stakeholders. This is a key part of the explainable AI concept, enabling us to build safe and smart algorithms that have a significant impact on individuals' lives.
What’s next?
In addition to walking through the above instructions, we suggest experimenting with the following in order to get even more hands-on experience using synthetic data for explainable AI:
- replicate the explainability section with real data and compare results
- use a different dataset, eg. the UCI bank marketing dataset
- use a different ML model, eg. a RandomForest model
You can also head straight to the other synthetic data tutorials: