Set column types
When you add your original data to a generator, MOSTLY AI assigns a data type to each column based on the data inside. You can fine-tune the encoding type to ensure that the generated synthetic dataset provides the most accurate representation of your original data.
The encoding type defines how the Generative AI models in MOSTLY AI train on your data and the models then generate data.
The platform will automatically detect the most common data types that occur in datasets: Numeric, Categorical, and Datetime. All other encoding types need to be selected manually.
Steps
- In the generator Data configuration page, highlight an added table and click it.
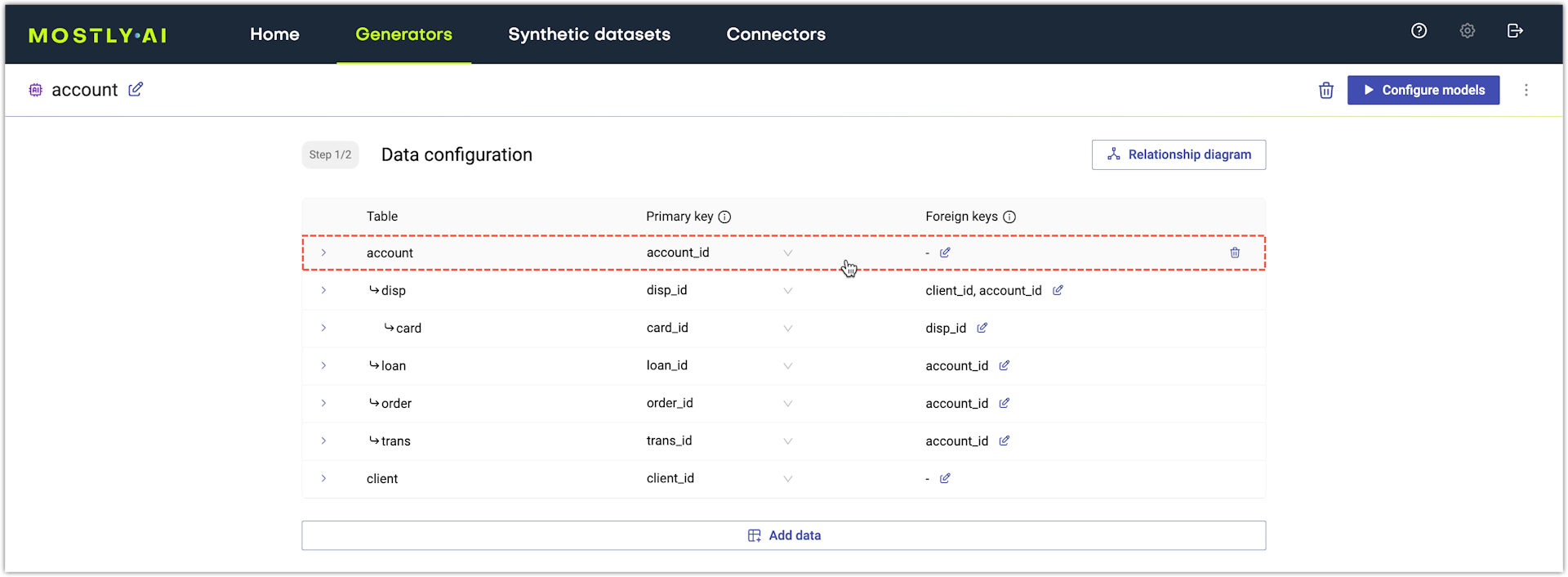 Step result: The table expands to reveal all table columns and their configuration.
Step result: The table expands to reveal all table columns and their configuration. - Click in the Encoding type area for a column.
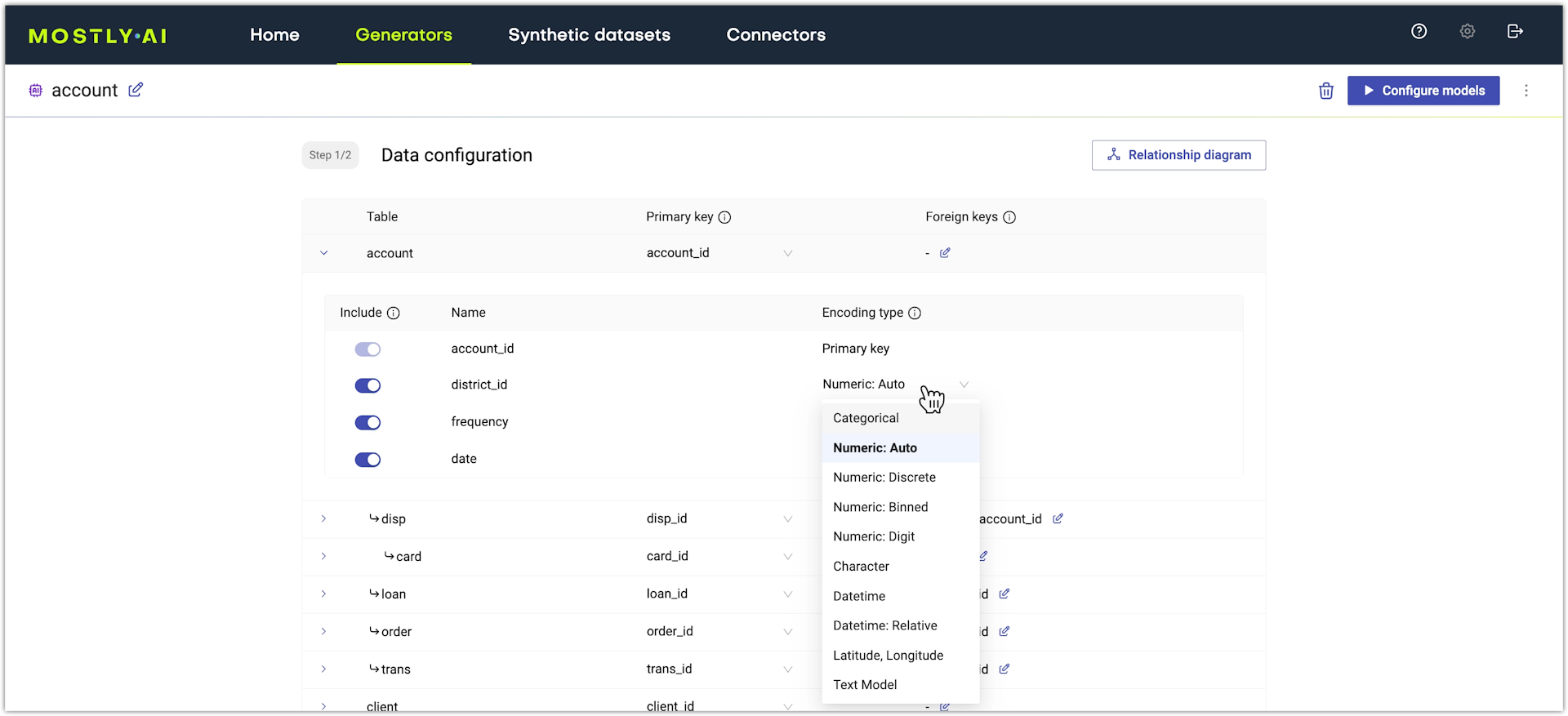
- Set a column type that best describes the data in the column.
For more information about each type, see the sections below.
Categorical
A categorical variable has a fixed set of possible values that are already present in the input data. An example of such a variable is T-shirt size, which could consist of the following categories: 'XS, S, M, L, XL'. The synthetic data will only contain categories that were present in the original data. Categorical variables thus prevent random values (for instance, 'XM, A, B') from appearing in your synthetic dataset.
If the automatic encoding type detection does not recognize a Numeric or Datetime column as such, it is encoded as Categorical.
You can control how the rare category protection mechanism works with Value protection settings and the Rare category replacement method which appear on the Model configuration page of a generator. These settings help with protecting rare categories. Rare categories may cause re-identification of outliers among your data subjects if they’re present in the resulting synthetic data.
There are two rare category protection methods available with which you can mask these categories:
Constant
Replaces rare categories with the value _RARE_.
The use of Constant introduces the _RARE_ category in your synthetic data and that can impact your downstream tasks. To avoid that, you can use the Sample method.
Sample
Replaces rare categories with categories that will appear in the synthetic version of this column. The categories are sampled from the original data based on their frequency. The more frequent a category is, the more likely it will be selected.
Numeric: Auto
With Numeric: Auto, MOSTLY AI uses heuristics to decide the most appropriate Numeric encoding type based on the data in a column. For most cases, select Numeric:Auto or leave it selected by default.
Numeric: Discrete
Discrete treats the numeric data in the column as categorical values. You can use this option for columns that have categorical numeric codes, such as:
- ZIP codes, postal codes, country phone codes
- binary
TrueorFalsethat are represented as the numeric values0and1 - any categorical data which are represented with numeric values
Extreme value protection and Rare category protection are ignored for columns with Discrete encoding type.
Numeric: Binned
You can use Binned for columns containing large integers or long decimals and, as a result, produce long training times that were otherwise needed when you previously selected Numeric (now renamed to Digit). MOSTLY AI bins the numerical values into 100 bins and considers each a category during training. During generation, MOSTLY AI samples values from the corresponding bin to generate the synthetic values in the column.
Numeric: Digit
Numeric: Digit recognizes the data in the column as numeric values.
MOSTLY AI can synthesize floating-point values with a precision of up to 8 digits after the decimal point.
Character
Use the Character encoding type to synthesize short strings with a consistent pattern, such as phone numbers, license plate numbers, company ID’s, transaction ID, and social security ID’s.
Datetime
Datetime refers to values that contain a date part and a time part. This encoding type enables MOSTLY AI to synthesize them and generate valid and statistically representative dates and times.
The following formats are supported:
| Format | Example | |
|---|---|---|
| Date | yyyy-MM-dd | 2020-02-08 |
| Datetime with hours | yyyy-MM-dd HHyyyy-MM-ddTHHyyyy-MM-ddTHHZ | 2020-02-08 092020-02-08T092020-02-08T09Z |
| Datetime with minutes | yyyy-MM-dd HH:mmyyyy-MM-ddTHH:mmyyyy-MM-ddTHH:mmZ | 2020-02-08 09:302020-02-08T09:302020-02-08T09:30Z |
| Datetime with seconds | yyyy-MM-dd HH:mm:ssyyyy-MM-ddTHH:mm:ssyyyy-MM-ddTHH:mm:ssZ | 2020-02-08 09:30:262020-02-08T09:30:262020-02-08T09:30:26Z |
| Datetime with milliseconds | yyyy-MM-dd HH:mm:ss.SSSyyyy-MM-ddTHH:mm:ss.SSSyyyy-MM-ddTHH:mm:ss.SSSZ | 2020-02-08 09:30:26.1232020-02-08T09:30:26.1232020-02-08T09:30:26.123Z |
Datetime: Relative
Datetime: Relative models the time interval between two subsequent events in the synthetic dataset. This encoding type causes the time between events to become very accurate, but the dates become less accurate.
The Datetime: Relative encoding type is only available for linked tables.
Latitude, Longitude
Use the Latitude, Longitude encoding type to synthesize geolocation coordinates.
MOSTLY AI requires a geolocation coordinate to be encoded in a single field with the latitude and longitude as comma-separated values. The latitude must be on the comma’s left side and the longitude on the right.
The values must be in decimal degrees format and range from -90 to 90 for latitude and -180 to 180 for longitude. Their precision cannot be larger than five digits after the decimal dot. This translates to an accuracy of approx. 1 meter. Any additional digits will be ignored.
| Start location | End location | Some other location |
|---|---|---|
70.31311, 150.1 | -90.0, 180.0 | 37.311, 173.8998 |
-39.0, 120.33114 | 78.31112, -100.031 | -10.10, -80.901 |
For CSV files, wrap each coordinate in double quotes. To learn more, see CSV files requirements.
Text Model
Use the Text Model type to synthesize unstructured natural language texts up to 1,000 characters long.
You can use this encoding type to generate realistic, representative, and anonymous financial transaction texts, short user feedback, medical assessments, PII fields, etc. As the resulting synthetic texts are representative of the terms, tokens, and their co-occurrence in the original data, they can be confidently used in analytics and machine learning use cases, such as sentiment analysis and named-entity recognition. Even though they might look noisy and not very human-readable, they will work perfectly for these use cases.
Our text synthesis model is language-agnostic and doesn’t contain the biases of some pre-trained models—any content is solely learned from the original training data. This means that it can process any language, vernacular, and slang present in the original data.
The amount of data required to produce usable results depends on the diversity of the original texts' vocabulary, categories, names, etc. As a rule of thumb, the more structure there is, the fewer samples are needed.
The synthetic texts are generated in a context-aware manner—the messages from a teenager are different from those of an 85-year old grandmother, for instance. By considering the other attributes of a synthetic subject’s profile, MOSTLY AI is capable of synthesizing appropriate natural language texts for each of them.
Below, you can find two examples. The first example demonstrates MOSTLY AI’s ability to synthesize entirely new names from a multilingual dataset. And the second example shows the result of synthesizing Tripadvisor reviews. Here you can see that the resulting texts accurately retain the context of the establishment they discuss (Restaurant or Hotel) and the synthesized rating.
Multilingual names dataset
| Original | Synthetic |
|---|---|
| |
Tripadvisor reviews
| Original |
|---|
|
| Synthetic |
|---|
|