Differential privacy
With MOSTLY AI, you can train a generator with differential privacy enabled to ensure that it can generate differentially private synthetic data.
When to use differential privacy?
MOSTLY AI models implement a number of privacy mechanisms to guarantee that a trained generator will never leak private data.
If you wish to add a mathematical guarantee that a trained generator is differentially private, you can enable differential privacy in its configuration before starting its training.
Train with differential privacy
In MOSTLY AI, you enable differential privacy on the Model configuration page of a generator. This means that you can train a generator to be differentially private from the start. Any synthetic datasets you generate with this generator will be differentially private as a result.
Steps
-
Open a non-trained generator (that has the status New or Continue)
-
Click Configure models in the upper right.
-
On the Model configuration page, expand a model to configure.
-
Expand Differential privacy and select On to enable differential privacy for the model.
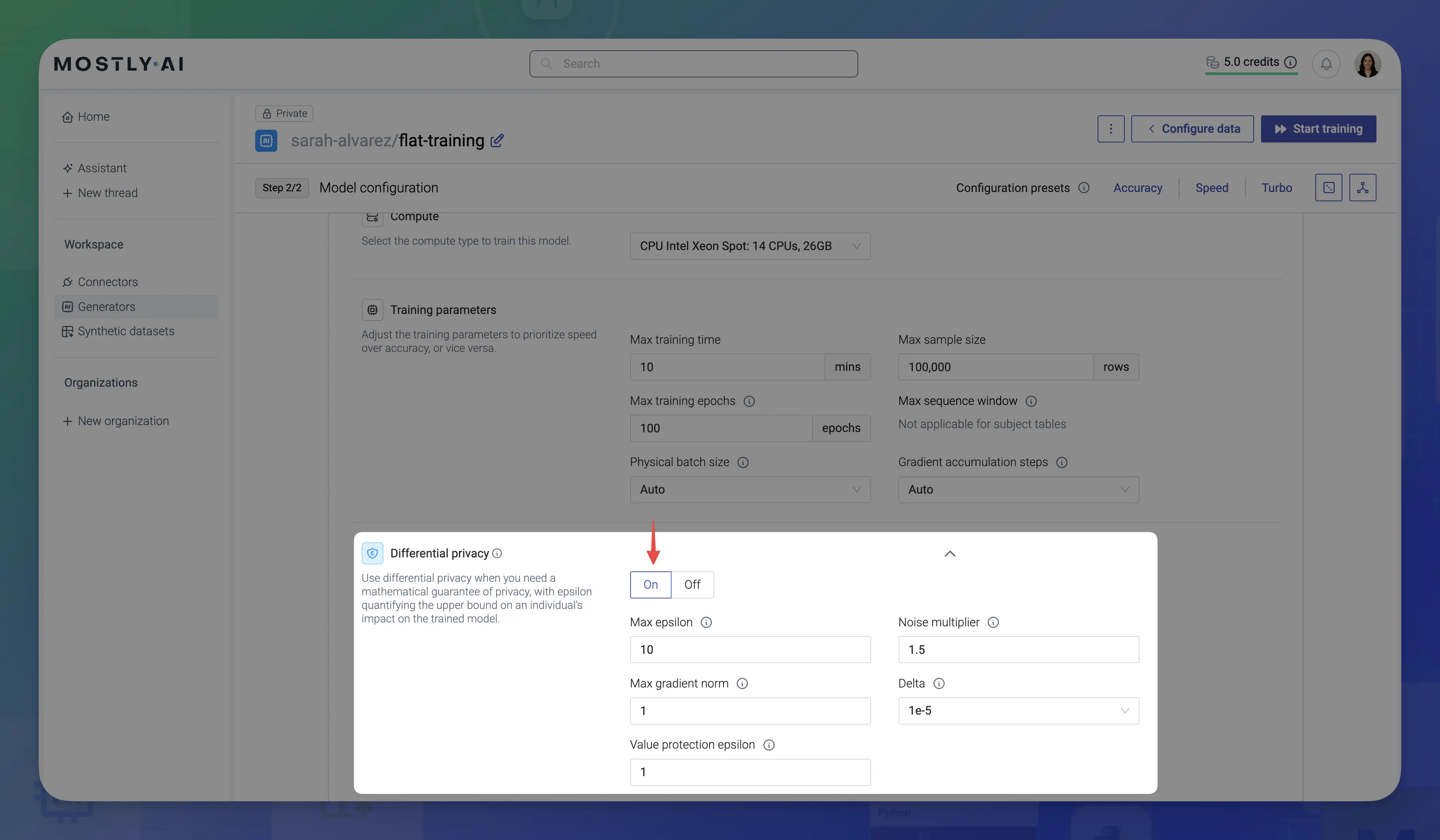
-
Configure the differential privacy options.
Differential privacy setting Action DP max epsilon Set a maximum epsilon value for the model.
If exceeded, this value acts as a stopping criteria for training. Only those model checkpoints that have an epsilon value below this threshold will be saved. If left blank, the training proceeds without a stopping criteria.
For details, see Privacy budget (epsilon).DP noise multiplier Set the noise multiplier for the model. The noise multiplier determines the amount of noise added to the model’s gradients during training. A higher value results in more noise and stronger privacy, but may lead to less accurate results.
The default is1.5.
For details, see Noise multiplier.DP max gradient norm Set the maximum norm of the per-sample gradients. Gradients with norm higher than this will be clipped to this value.
The default is1.
For details, see Gradient clipping.Delta The delta value for differential privacy in the range of 1 x 10 ^ -3to1 x 10 ^ -12. It is the probability of the privacy guarantee not holding. The smaller the delta, the more confident you can be that the privacy guarantee holds.
The default is1 x 10 ^ -5.Value protection epsilon Privacy budget allocated for protecting value ranges during analysis. A higher value provides more accurate ranges but reduces the budget available for model training. 💡Note
The best amounts of epsilon, noise multiplier, and max gradient norm depend on your original data, specific use case, and the desired trade-off between privacy and accuracy.
As a best practice, start with the default values and adjust them based on the results.
-
Click Start training in the upper right to train the generator with differential privacy.
What’s next
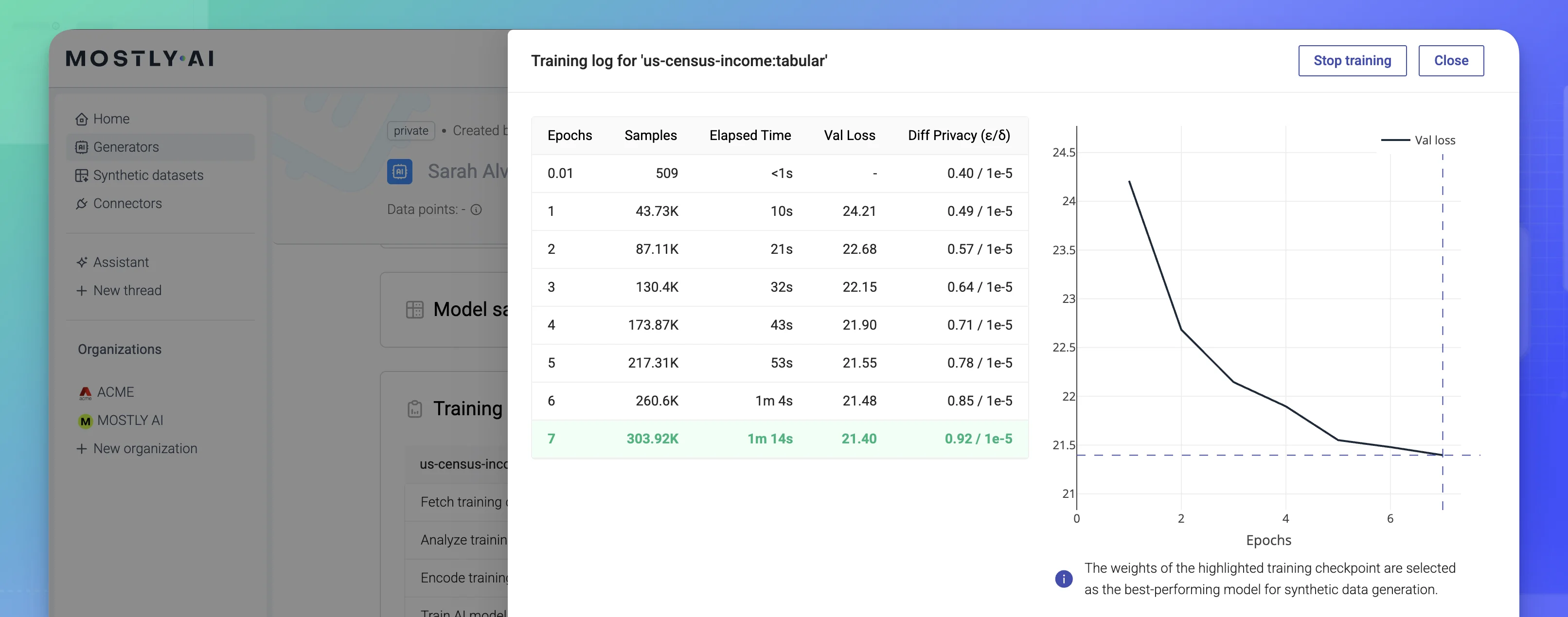
You can track the training progress and the epsilon value by opening the Training log from the Training status section.
The Training log includes the Diff privacy (ε/δ) column and shows the values of epsilon and delta. The delta is typically a very low value (such as 1e-5) and represents the probability threshold for potential privacy loss across the training epochs. A smaller delta implies a stricter privacy guarantee.
Appendix: Concepts
Differential privacy is a mathematical definition of privacy that ensures that the output of a computation does not reveal information about the input data. It is a way to maximize the accuracy of queries from statistical databases while minimizing the chances of identifying individual records.
Example
Imagine a database that contains the salaries of all employees in a company. If you query the database to get the average salary of all employees, the result will be different if you include or exclude the salary of a single employee.
Differential privacy ensures that the result of the query is the same or very similar, regardless of whether the salary of a single employee is included or not.
Key concepts of differential privacy are noise addition and privacy budget (also known as epsilon).
Noise addition
Differential privacy works by adding controlled random noise to the data or results derived from it (such as averages or counts). This noise is used to mask the contribution of individual records to the output of a query, making it impossible to identify individual records.
The amount of noise to add depends on the privacy budget, or epsilon (ε).
Privacy budget (epsilon)
The privacy budget, or epsilon (ε), is a measure of how much privacy loss is acceptable. It quantifies the trade-off between privacy and data accuracy. A smaller epsilon means stronger privacy, as the effect of any single data point is more heavily obscured, but may lead to less accurate results.
Each query or analysis consumes a portion of the privacy budget. With repeated queries, the budget can be potentially exhausted, which limits how much information can be extracted from a dataset before privacy risks increase.
Appendix: Techniques
MOSTLY AI uses the Opacus library to implement differential privacy in its models. Opacus is a library for training PyTorch models with differential privacy.
Gradient clipping
During training, the gradients of each individual sample in a batch are computed. To limit the influence of any single sample on the model, the gradients are clipped to a predefined maximum norm. This ensures that the model does not overfit to any single sample and that the training process is more stable.
Noise multiplier
After gradient clipping, Opacus adds noise to the sum of gradients before they are applied to update the model parameters. This noise, typically Gaussian, is calibrated based on the privacy budget (epsilon) specified by the user, which defines how much information about any single sample can be inferred from the model.