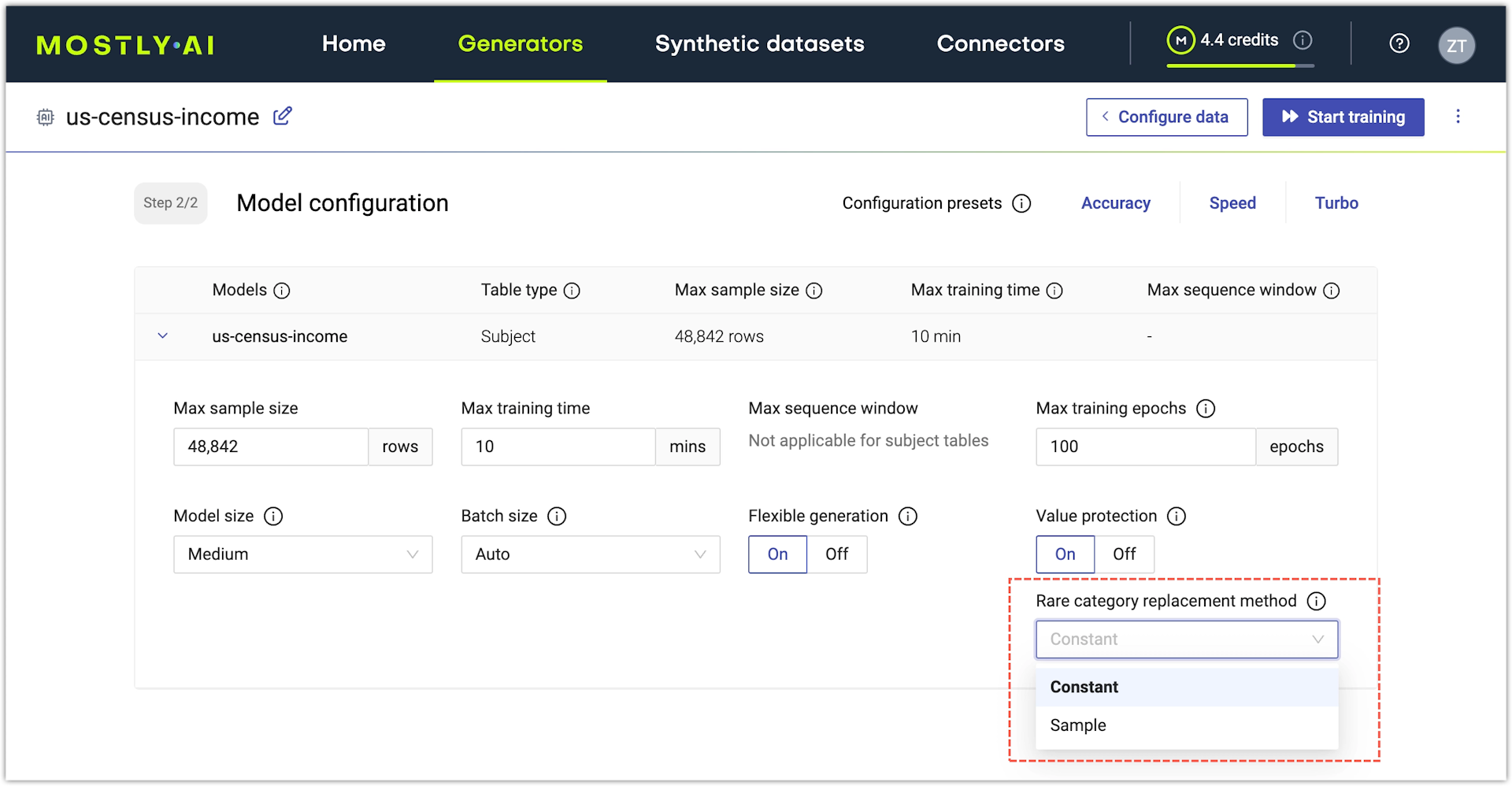
_RARE_ values
MOSTLY AI protects the privacy of your data with a number of mechanisms that make sure that no private data of people or other entities appears in your generated synthetic data.
Value protection is on by default for each generator you train. One of the mechanisms included in Value protection is the Rare category protection which is also on by default and has two modes of operation. Learn about each mode and how it impacts the appearance of _RARE_ values in your synthetic datasets.
Methods of rare category protection
You can configure Rare category protection to replace rare categories in categorical columns with either the Constant or the Sample replacement method.
Constant method
With the Constant method, all rare categories in a categorical column are masked with the token _RARE_ to protect any people or entities from being re-identifiable in the synthetic data. The replacement occurs automatically before your generator starts training.
An example of a rare category in a Job title column can be the category President of the United States which makes the person behind the title instantly re-identifiable. With the Constant method, the category is masked with the _RARE_ token before model training.
The goals of this approach are to:
- prevent the training of the AI model with rare categories
- retain the original distribution of categories in the synthetic data
The Constant method is the default method for all categorical columns and is the reason why _RARE_ values appear in your synthetic data.
Sample method
With the Sample method, MOSTLY AI replaces any rare categories by sampling non-rare categories from the same column.
For example, in a Job title column, the rare category President of the United States can be replaced by sampling from a non-rare category, such as Senior Account Manager.
With this method, you can prevent _RARE_ values, but it comes with the trade-off of skewing the original distribution in the categorical column by boosting any non-rare categories that MOSTLY AI samples from.
Do not disable Value protection
MOSTLY AI recommends that you do not disable Value protection for categorical columns.
If you do so, you risk exposing your synthetic data to re-identification attacks. This means that the Generative AI models in MOSTLY AI are trained with rare categories and will generate rare categories in the synthetic data.
For example, in a Job title column, the categories CEO, CTO, CFO, and other C-level positions typically appear only once per company. If you are processing a dataset that includes all employees at a company, the data of all C-level executives is immediately open to re-identification if Value protection is not enabled.
If you use the default Constant method, MOSTLY AI replaces the C-level positions with _RARE_ values and keeps their data private. In this case, the distribution of the remaining categories is preserved in the synthetic data.
With the Sample method, MOSTLY AI randomly replaces the C-level positions with any of the other job titles in the column. This protects the data from re-identification but at the cost of accuracy due to the fact that the remaining job title categories are now redistributed in the synthetic data.
Use the Rare category replacement method that makes the most sense for your categorical columns. Or you can also use a different encoding type for specific categorical columns as explained in the sections below.
Cases with many _RARE_ values
In some cases, a categorical column in your synthetic data might contain only a few _RARE_ values. In other cases, however, a categorical column might contain nothing but _RARE_ values.
It all depends on the data in your categorical columns. The sections below review specific examples of categorical data and how that can impact the number of _RARE_ values that appear in your synthetic data.
Columns for names
Columns that contain first or last names of your data subjects are auto-assigned the Categorical encoding type and, by default, Value protection with the Constant replacement method of rare categories is enabled for such columns.
Such columns contain many distinct names which MOSTLY AI treats as rare categories. As a result, most or all values in such columns are _RARE_.
For such cases, you can use one of the alternatives suggested below.
Use the Text encoding type
You can use the Text encoding type to train the Generative AI models on the names in your original data, and then generate synthetic names.
Bear in mind that the Text encoding type might increase the computational time to train the Generative AI models as the names in the original dataset go through a process of tokenizing the names and analyzing the character sequence of each token.
Pre-process your data to exclude names
Another approach is to pre-process your original data and exclude columns with names before you go on to generate synthetic data.
This approach adds an prerequisite to the process of synthesizing data and MOSTLY AI recommends it only if you are familiar how to pre-process your data.
Columns for codes
If a column contains alphanumeric ID codes, MOSTLY AI auto-assigns the Categorical encoding type and enables the Constant replacement method.
Because each ID is unique in the column, the synthetic data for the column contain only _RARE_ values.
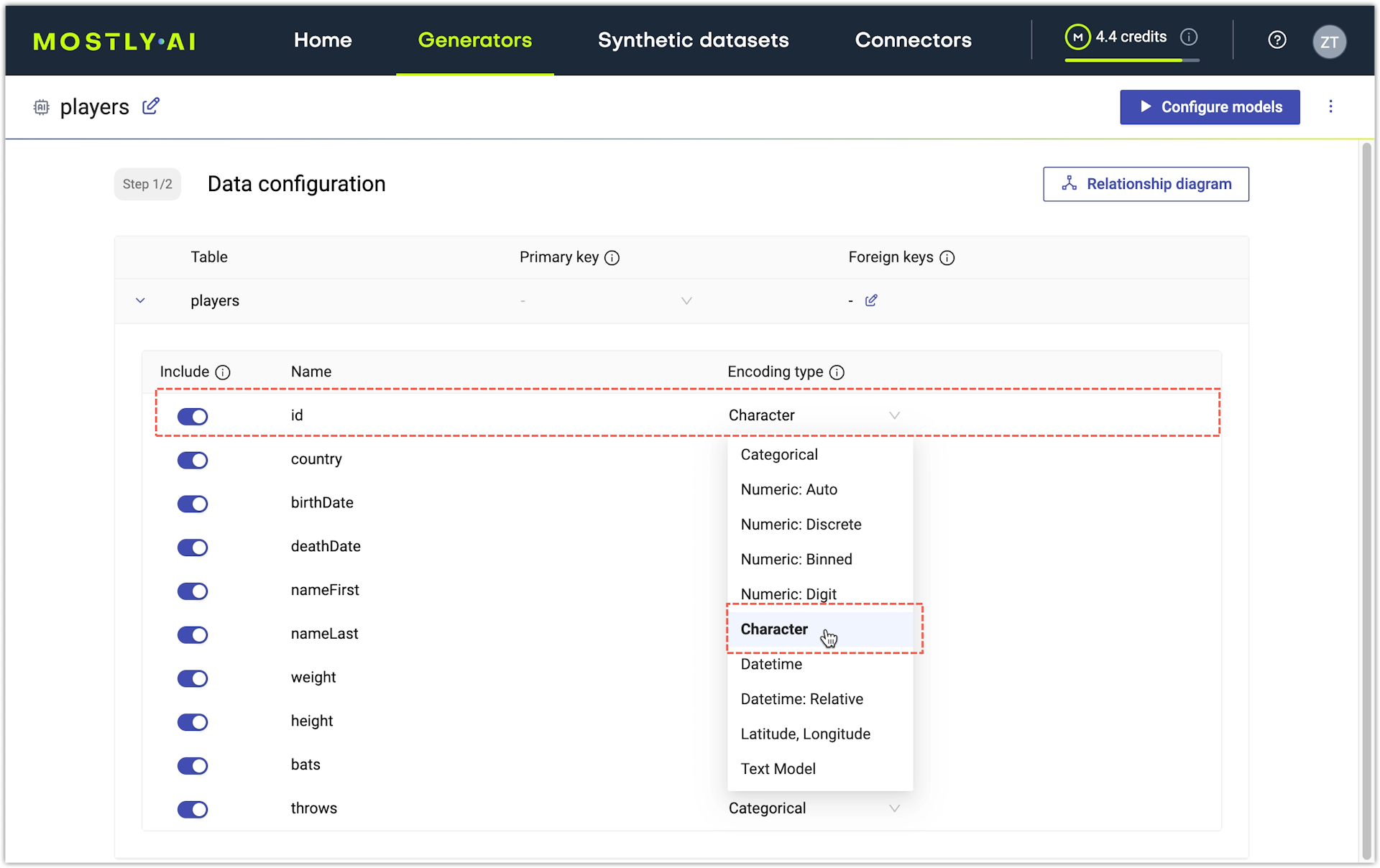
Use Character encoding type
If the original column contains short strings with a consistent pattern (phone numbers, license plate numbers, company IDs, and so on), you can use the Character encoding type to train the Generative AI model for this table with the code patterns.
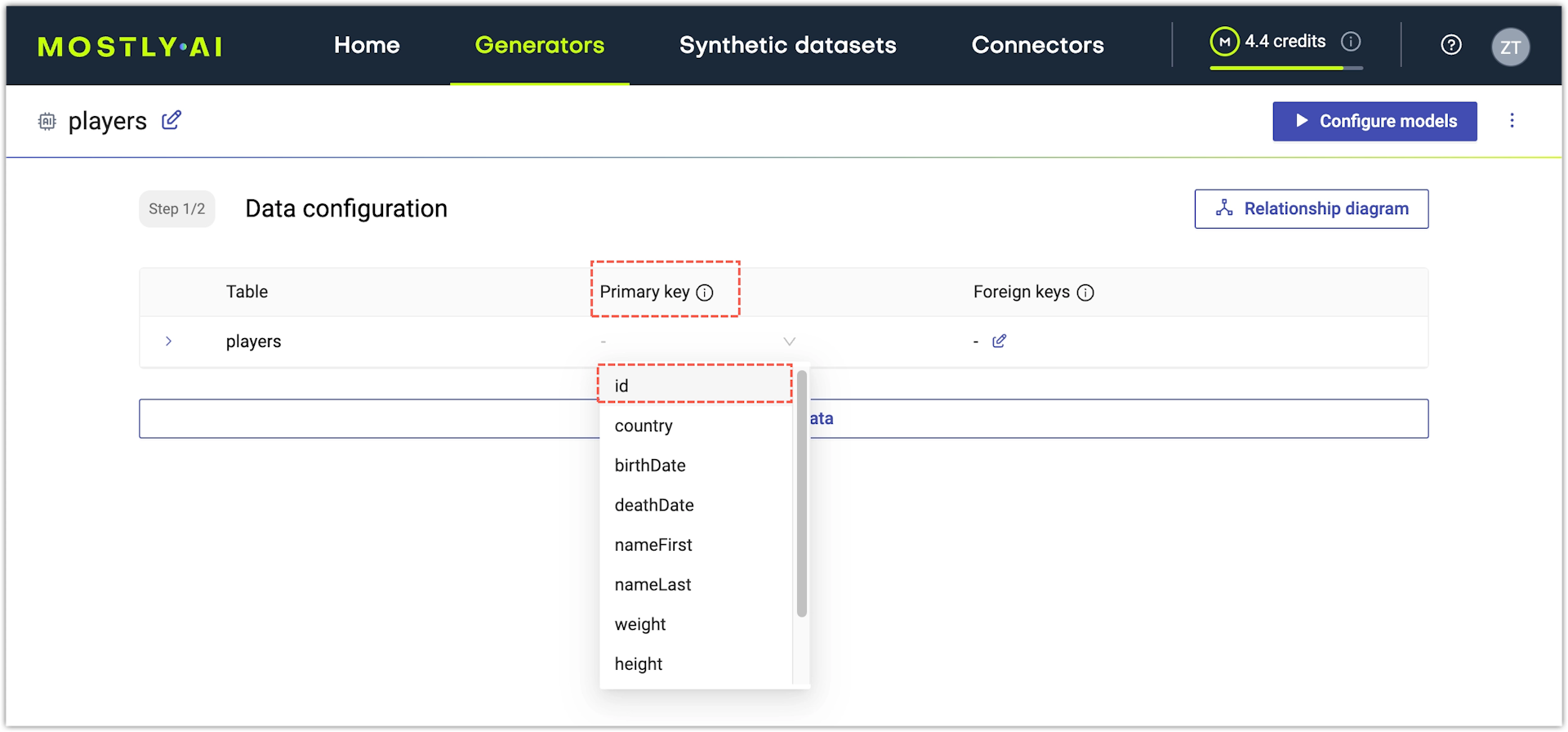
Set a primary key
If the original column is a primary key column, you can set a Primary key to generate primary key values. MOSTLY AI generates integer or UUID primary keys in the column depending on its primary key format.
Pre-process your data to exclude primary keys
If you do not intend to set a primary key on a table or point any foreign keys to it, you can pre-process the table to exclude the primary key column. Alternatively, deselect the Include checkbox on the Data configuration page of a generator.
Columns for emails
If a column contains emails, MOSTLY AI again auto-assigns the Categorical encoding type and enables Rare category protection with the Constant method.
If each row in the column contains a unique email, all emails will appear as _RARE_ values in the synthetic data.