Train a new generator
With generators, MOSTLY AI makes it easy to use Generative AI to train your own AI models on single- and multi-table datasets. You can then use a trained generator to generate endless amounts of high-quality and privacy-protected synthetic data.
You can quickly train a new generator with a single tabular data file.
You can also train generators with two-table and multi-table datasets. For more information, see Set table relationships.
If you use the web application, you can start the training of a new generator from the Generators page.
Steps
-
On the Generators page, click + New generator.
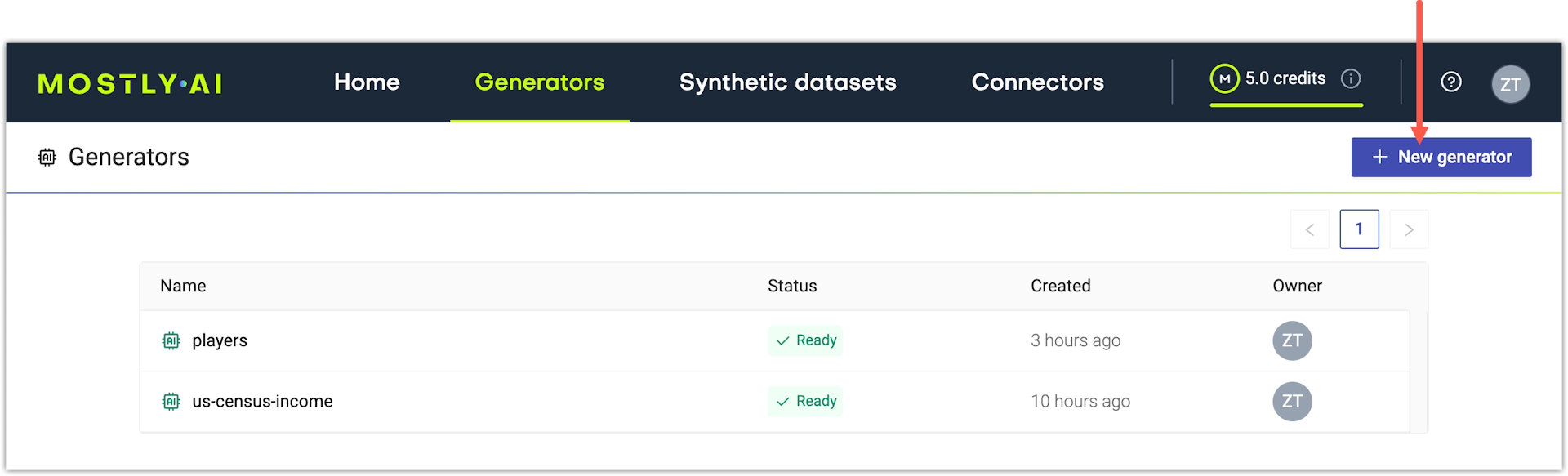
Step result: You now have a generator object created in the MOSTLY AI database and the generator is listed on the Generators page.
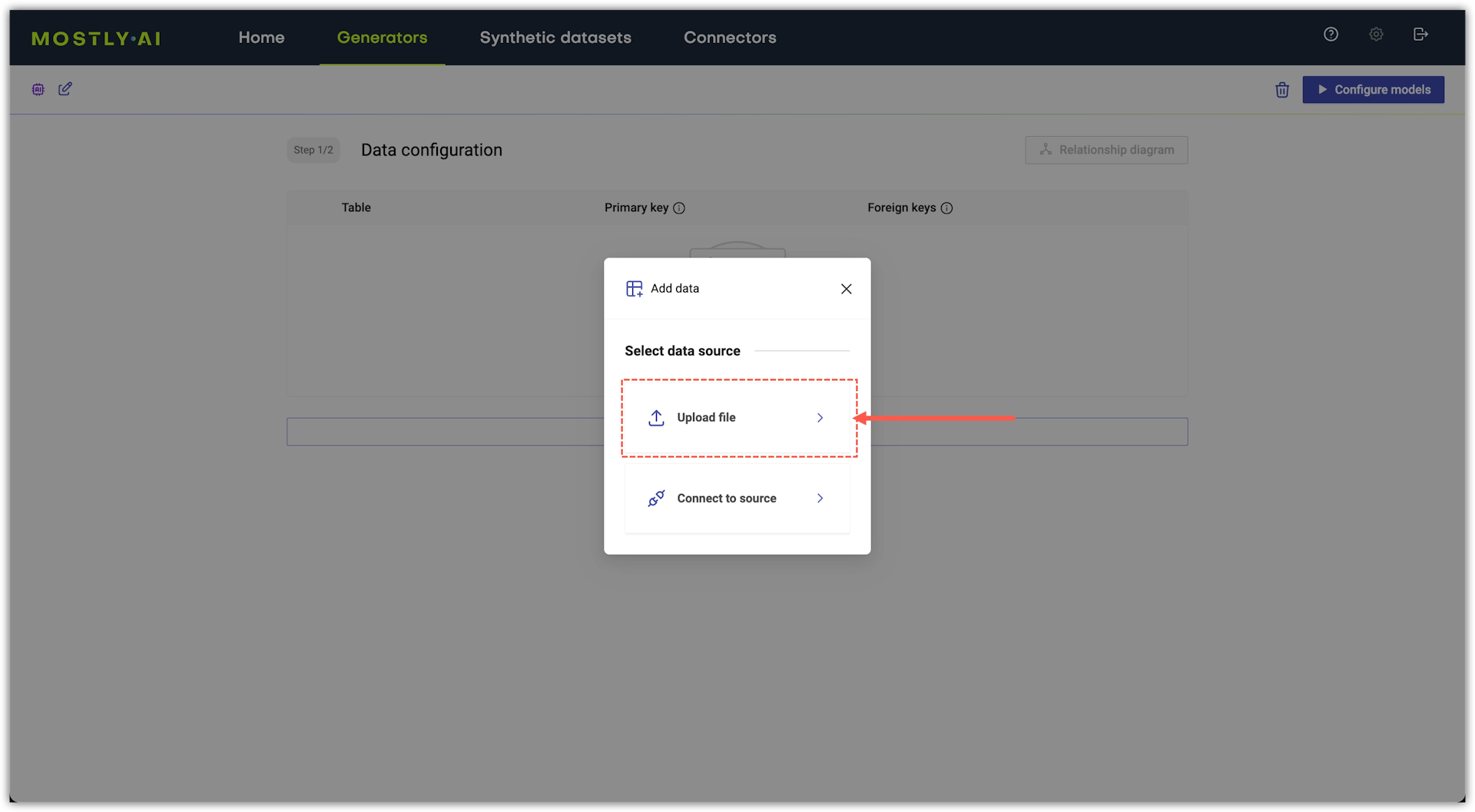
The Add data window appears prompting you to add tabular data for your generator to train on.
-
Add a table with file upload.
- From the Add data window, click Upload file.
💡
You can also add data from a database or cloud bucket when you select Connect to a source. To learn more, see Add data from a database and Add data from a cloud storage bucket.
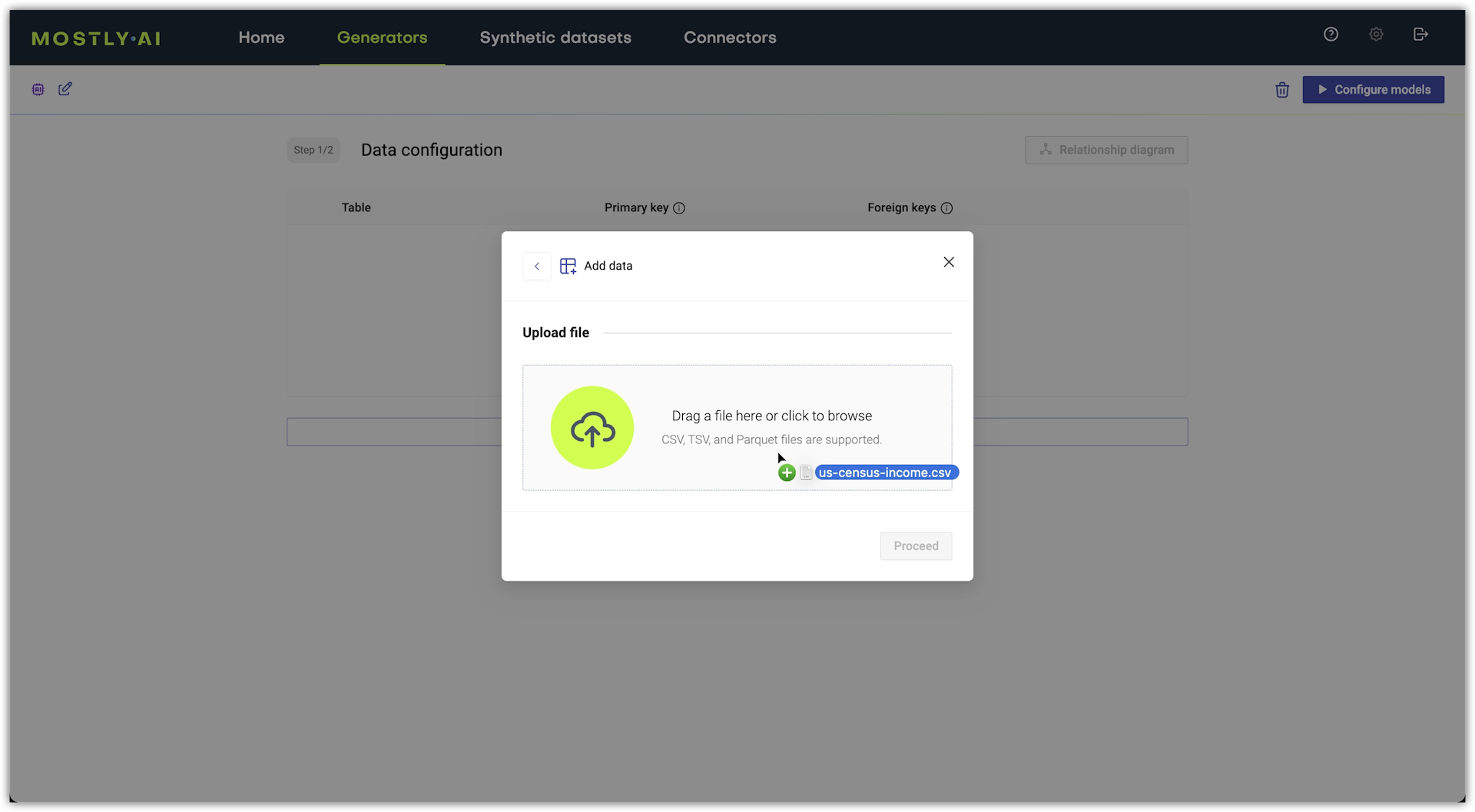
- Under Upload file, drag a local file onto the box or click the box to browse your local file system.
💡If you need a dataset, download one from the Datasets page.
- (Optional) Enter a name for the table.
The table name appears in the list of tables added to the generator. Also, the table name that you provide is what appears in each generated synthetic dataset.
- Click Proceed.
- From the Add data window, click Upload file.
-
Train the generator.
- Click Configure models in the upper right.
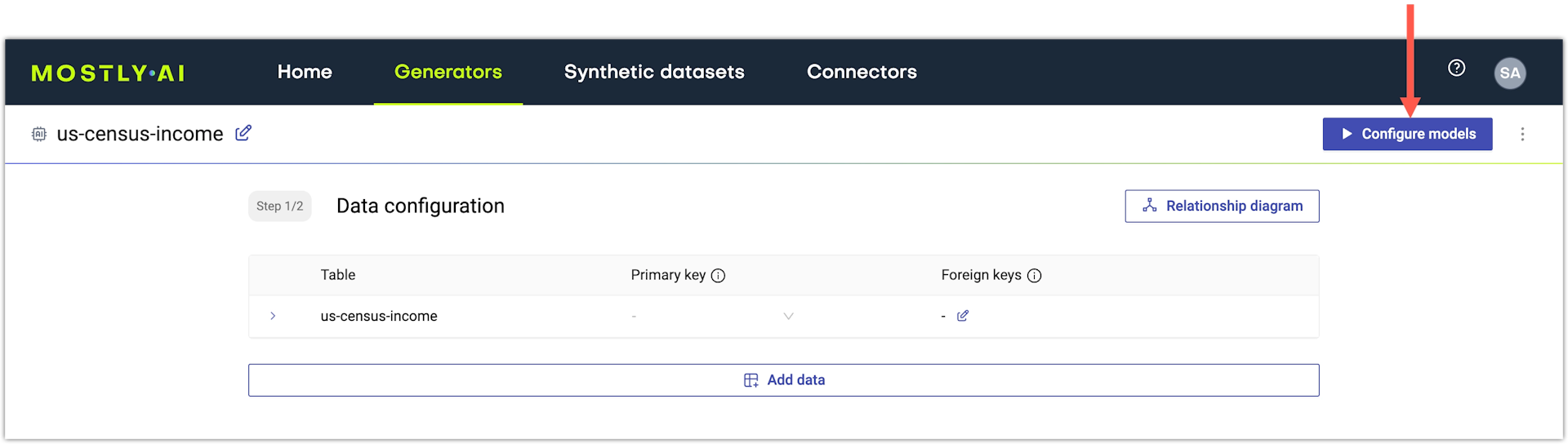
- On the Model configuration page, click Start training.
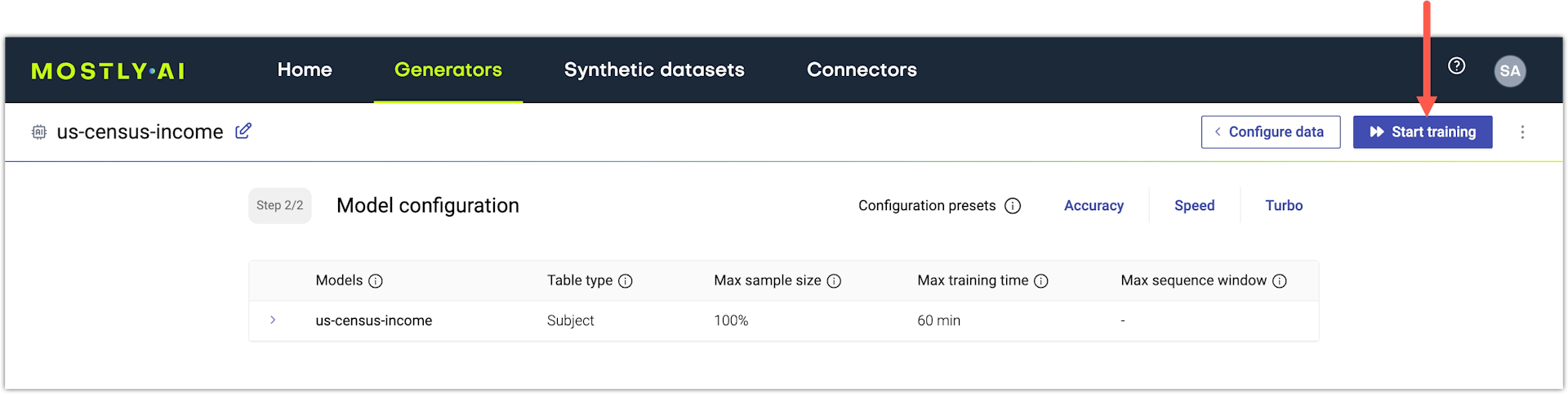
- Click Configure models in the upper right.
Result
Your generator now starts training. When the training completes, your generator is ready to generate synthetic data.